Exploring the Impact of Table-to-Text Methods on Augmenting LLM-based Question Answering with Domain Hybrid Data
Abstract: Augmenting LLMs for Question Answering (QA) with domain specific data has attracted wide attention. However, domain data often exists in a hybrid format, including text and semi-structured tables, posing challenges for the seamless integration of information. Table-to-Text Generation is a promising solution by facilitating the transformation of hybrid data into a uniformly text-formatted corpus. Although this technique has been widely studied by the NLP community, there is currently no comparative analysis on how corpora generated by different table-to-text methods affect the performance of QA systems. In this paper, we address this research gap in two steps. First, we innovatively integrate table-to-text generation into the framework of enhancing LLM-based QA systems with domain hybrid data. Then, we utilize this framework in real-world industrial data to conduct extensive experiments on two types of QA systems (DSFT and RAG frameworks) with four representative methods: Markdown format, Template serialization, TPLM-based method, and LLM-based method. Based on the experimental results, we draw some empirical findings and explore the underlying reasons behind the success of some methods. We hope the findings of this work will provide a valuable reference for the academic and industrial communities in developing robust QA systems.
- Hellama: Llama-based table to text generation by highlighting the important evidence.
- Pythia: A suite for analyzing large language models across training and scaling. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 2397–2430. PMLR.
- Harrison Chase. 2022. Langchain.
- Open question answering over tables and text. In International Conference on Learning Representations.
- Logical Natural Language Generation from Open-Domain Tables. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7929–7942, Online. Association for Computational Linguistics.
- Hybridqa: A dataset of multi-hop question answering over tabular and textual data. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1026–1036.
- HiTab: A hierarchical table dataset for question answering and natural language generation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1094–1110, Dublin, Ireland. Association for Computational Linguistics.
- QLoRA: Efficient Finetuning of Quantized LLMs. ArXiv:2305.14314 [cs].
- Measuring Causal Effects of Data Statistics on Language Model’s ‘Factual’ Predictions. ArXiv:2207.14251 [cs].
- Retrieval-augmented generation for large language models: A survey.
- Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8342–8360, Online. Association for Computational Linguistics.
- Acegpt, localizing large language models in arabic.
- Mixed-modality Representation Learning and Pre-training for Joint Table-and-Text Retrieval in OpenQA. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 4117–4129, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Billion-scale similarity search with gpus. IEEE Transactions on Big Data, 7(3):535–547.
- Evaluating open-domain question answering in the era of large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5591–5606, Toronto, Canada. Association for Computational Linguistics.
- Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, Online. Association for Computational Linguistics.
- Hurdles to Progress in Long-form Question Answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4940–4957, Online. Association for Computational Linguistics.
- BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Advances in Neural Information Processing Systems, volume 33, pages 9459–9474. Curran Associates, Inc.
- Dual reader-parser on hybrid textual and tabular evidence for open domain question answering. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4078–4088.
- Table-gpt: Table-tuned gpt for diverse table tasks. arXiv preprint arXiv:2310.09263.
- Domain Specialization as the Key to Make Large Language Models Disruptive: A Comprehensive Survey. ArXiv:2305.18703 [cs].
- PLOG: Table-to-logic pretraining for logical table-to-text generation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5531–5546, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- G-eval: NLG evaluation using gpt-4 with better human alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, Singapore. Association for Computational Linguistics.
- BioMedGPT: Open Multimodal Generative Pre-trained Transformer for BioMedicine. ArXiv:2308.09442 [cs].
- Few-shot Table-to-text Generation with Prefix-Controlled Generator. In Proceedings of the 29th International Conference on Computational Linguistics, pages 6493–6504, Gyeongju, Republic of Korea. International Committee on Computational Linguistics.
- Query rewriting in retrieval-augmented large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5303–5315, Singapore. Association for Computational Linguistics.
- FeTaQA: Free-form Table Question Answering. Transactions of the Association for Computational Linguistics, 10:35–49.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Totto: A controlled table-to-text generation dataset. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1173–1186.
- Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32.
- Improving language understanding by generative pre-training.
- Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16. IEEE.
- Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 3505–3506.
- Impact of pretraining term frequencies on few-shot numerical reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 840–854, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- GPT4Table: Can Large Language Models Understand Structured Table Data? A Benchmark and Empirical Study. ArXiv:2305.13062 [cs] version: 3.
- MVP: Multi-task Supervised Pre-training for Natural Language Generation. In Findings of the Association for Computational Linguistics: ACL 2023, pages 8758–8794, Toronto, Canada. Association for Computational Linguistics.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-sne. Journal of machine learning research, 9(11).
- Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity. ArXiv:2310.07521 [cs].
- Is ChatGPT a good NLG evaluator? a preliminary study. In Proceedings of the 4th New Frontiers in Summarization Workshop, pages 1–11, Singapore. Association for Computational Linguistics.
- Self-instruct: Aligning language models with self-generated instructions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13484–13508, Toronto, Canada. Association for Computational Linguistics.
- Augmenting black-box llms with medical textbooks for clinical question answering.
- PMC-LLaMA: Towards Building Open-source Language Models for Medicine. ArXiv:2304.14454 [cs].
- UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 602–631, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Retrieval-augmented domain adaptation of language models. In Proceedings of the 8th Workshop on Representation Learning for NLP (RepL4NLP 2023), pages 54–64, Toronto, Canada. Association for Computational Linguistics.
- Empower large language model to perform better on industrial domain-specific question answering. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 294–312, Singapore. Association for Computational Linguistics.
- Variational template machine for data-to-text generation. In International Conference on Learning Representations.
- Frequency Balanced Datasets Lead to Better Language Models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 7859–7872, Singapore. Association for Computational Linguistics.
- Retrieve Anything To Augment Large Language Models. ArXiv:2310.07554 [cs].
- OPT: Open Pre-trained Transformer Language Models. ArXiv:2205.01068 [cs].
- Domain specialization as the key to make large language models disruptive: A comprehensive survey. arXiv preprint arXiv:2305.18703.
- Investigating table-to-text generation capabilities of large language models in real-world information seeking scenarios. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 160–175, Singapore. Association for Computational Linguistics.
- Reasoning over hybrid chain for table-and-text open domain question answering. In International Joint Conference on Artificial Intelligence (IJCAI), pages 4531–4537.
- Tat-qa: A question answering benchmark on a hybrid of tabular and textual content in finance. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3277–3287.
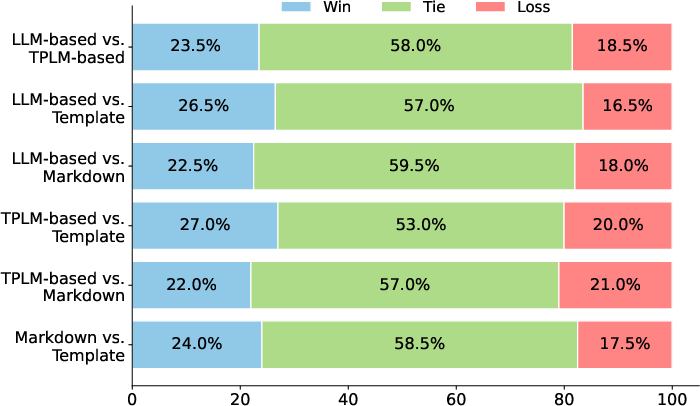
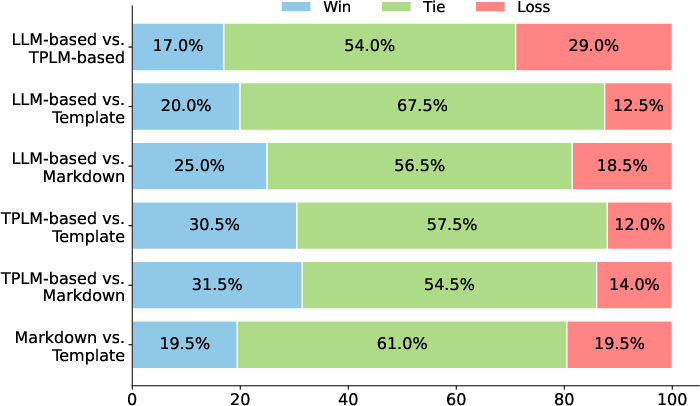
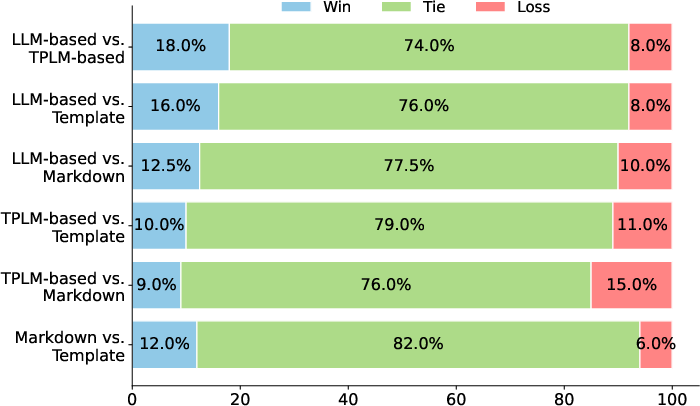
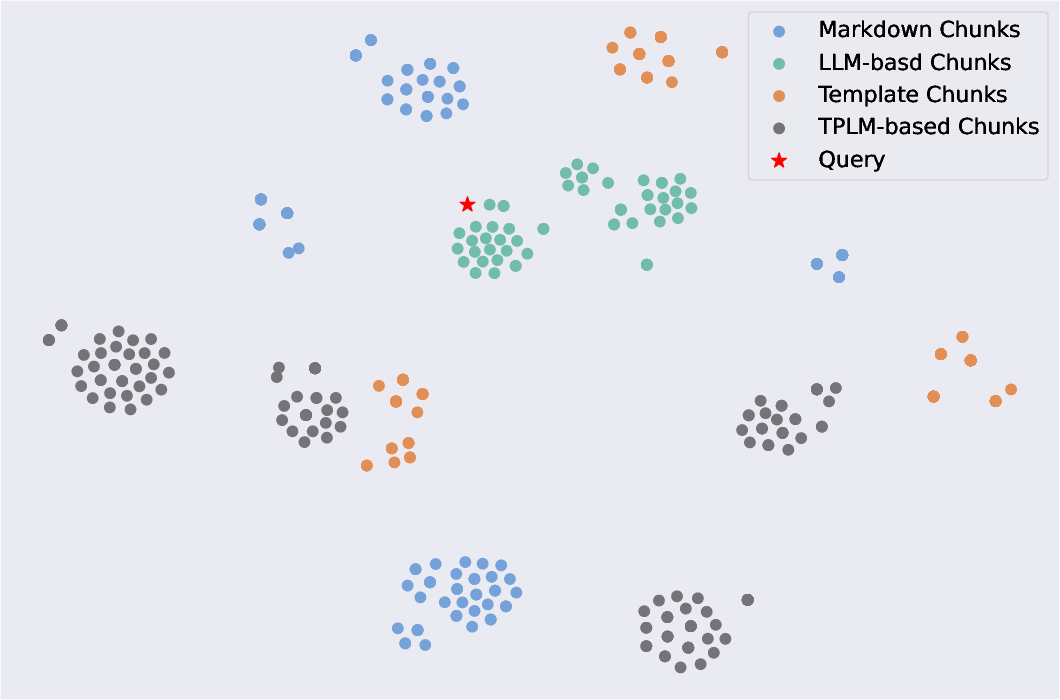
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.