- The paper proposes a pre-attribution mechanism that enhances source attribution accuracy by reducing noise through a cleaned dataset and a Random Forest classifier.
- It employs sentence-level classification using features like sentence length, readability, and syntax to optimize computational efficiency in attribution tasks.
- The system demonstrates improved real-world performance with models like ChatGPT and DeepSeek, underscoring its potential in critical fields such as medical and legal applications.
Enhancing Trustworthiness: Improving Attribution in LLMs
Introduction
The proliferation of LLMs has been both a boon and a challenge. While these models have demonstrated significant capabilities across various domains, their application in critical fields is limited by issues of trustworthiness due to unreliable source attributions. The paper "Think Before You Attribute: Improving the Performance of LLMs Attribution Systems" investigates the challenges of attribution in LLMs and proposes a novel method to enhance attribution reliability, which could increase the usability of LLMs in critical applications like medical and legal domains.
Proposed Method
The core innovation of this work is the introduction of a pre-attribution step within Retrieval-Augmented Generation (RAG) systems for sentence-level attribution. This step classifies each sentence into categories based on their reference needs: not attributable, attributable to a single quote, or multiple quotes. By tagging each sentence appropriately before applying attribution, the system can employ efficient algorithms selectively, optimizing both the accuracy and computational cost.
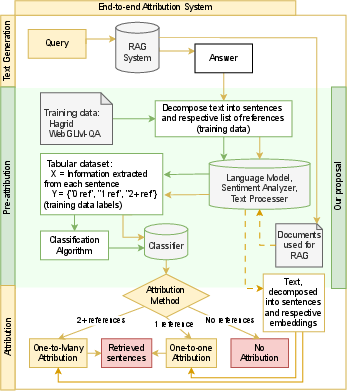
Figure 1: Overview of our proposed end-to-end attribution system.
Methodology and Datasets
Classification at the pre-attribution stage relies on datasets like HAGRID and WebGLM-QA. However, these datasets often suffer from noise and inconsistencies. To remedy this, the authors manually curated a version called HAGRID-Clean, addressing issues such as over-referencing and under-referencing of sentences. This cleaning process was crucial for reducing label noise, thereby improving classifier accuracy.
For sentence classification, features such as sentence length, readability metrics, and syntactic characteristics are extracted to train the classifiers, with Random Forest (RF) emerging as the most effective model for this task. The paper details the trade-offs among different classifiers, noting RF's superior precision in identifying reference needs across cleaned data.
Implementing the Attribution System
This research evaluated different attribution techniques. Among them, embedding-based methods were explored, focusing on semantic similarities. The two main strategies tested were matching a sentence to its nearest single quote and nearest pairs of quotes. The pre-attribution classification enhances these strategies by providing an efficient decision-making layer to reduce unnecessary computational loads.

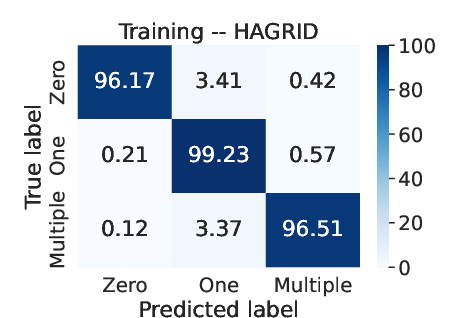
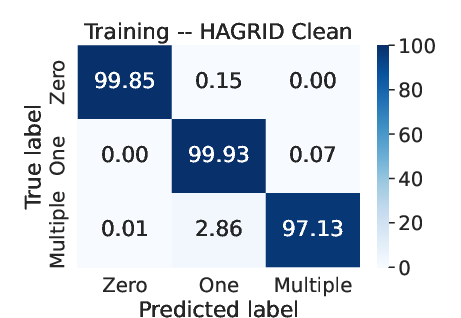
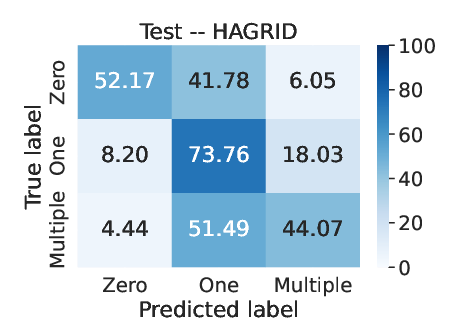
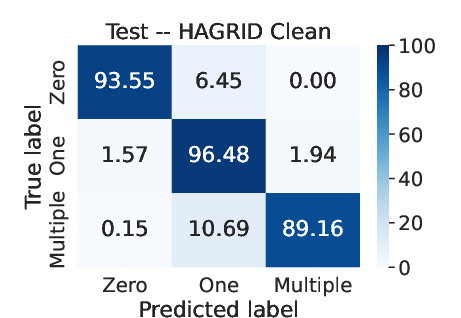
Figure 2: Average confusion matrix obtained over 30 runs in each dataset using RF for pre-attribution.
Real-World Applications
The applicability of the system to real-world scenarios was tested using ChatGPT, Perplexity, and DeepSeek in practical tasks. These involve summarizing scientific papers and querying for medical information, demonstrating the system's capacity to attribute generated responses accurately back to source documents. Through these examples, the research highlights challenges such as hallucinated content in generated text, where the LLMs fabricate responses not present in any referenced material.
Results and Implications
The results indicate that pre-attribution significantly enhances attribution accuracy, particularly in the presence of clean, standardized datasets. While traditional attribution models without pre-attribution showed degradation in test performance, incorporating this step yielded statistically significant improvements. Pre-attribution effectively functions as a filter, reducing noise and enhancing clarity in model outputs.
Conclusion
The proposed pre-attribution mechanism addresses fundamental gaps in LLMs' attribution capabilities by marrying computational efficiency with enhanced accuracy. This development holds promise for expanding LLM utility in fields demanding reliable and verifiable outputs, accentuating a crucial path forward in improving LLM infrastructure. Future work will likely explore refining these models to handle larger datasets and incorporating more sophisticated attribution algorithms capable of detecting hallucinations.
By providing both a cleaned dataset and an open-source implementation, this research lays the groundwork for continued advancements in the domain of LLM attribution, potentially unlocking new avenues for deploying AI safely and effectively in high-stakes applications.