- The paper introduces CitePretrain, a two-stage framework combining continual pretraining and instruction tuning to embed document citations in LLMs.
- It implements active indexing with forward and backward augmentation, achieving up to 30.2% improvement in citation precision.
- Results indicate that scaling augmented data and model sizes significantly enhances citation accuracy and transparency in LLM outputs.
Cite Pretrain: Retrieval-Free Knowledge Attribution for LLMs
Introduction
The paper "Cite Pretrain: Retrieval-Free Knowledge Attribution for LLMs" presents a framework called CitePretrain, aiming to reinforce internal knowledge attribution within LLMs without relying on retrieval mechanisms during inference. The intention is to improve verifiable output generation by associating content with the pretraining documents, thus bypassing the need for real-time retrieval which often introduces latency and noise.
Methodology
The implemented framework, CitePretrain involves a two-stage process:
- Continual Pretraining: This phase focuses on embedding document identifiers within the LLMs' trained knowledge. The traditional Passive Indexing merely appends document identifiers, which adeptly memorizes verbatim text but shows limitations with paraphrased or compositional facts. The proposed solution, Active Indexing, addresses these limitations by generating synthetic QA pairs and enforcing a robust mapping between identifiers and facts. This involves two types of augmentation:
- Forward Augmentation: Generates question-answer pairs to strengthen the mapping from document identifiers to factual content.
- Backward Augmentation: Involves multi-source instructions, synthesizing facts from related documents thus reinforcing fact-to-source generation.
- Instruction Tuning: Following the pretraining, the model undergoes instruction tuning to refine the citation behavior, ensuring alignment with downstream tasks that demand citation integrity.
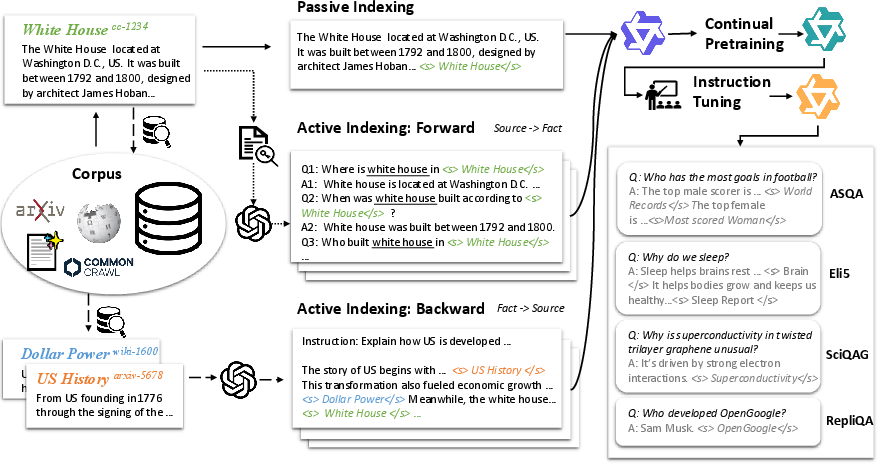
Figure 1: CitePretrain Framework illustrating both Passive and Active Indexing mechanisms.
Experimental Setup
The paper introduces CitePretrainBench, a benchmark comprising diverse corpora including Wikipedia, Common Crawl, and arXiv. The benchmark emphasizes both short-form and long-form citation tasks. The experiments performed with Qwen-2.5-7B and 3B LLMs demonstrate that Active Indexing significantly boosts citation precision compared to Passive Indexing, with gains up to 30.2%. The experiments focus on metrics of citation precision, recall, and answer correctness, offering a comprehensive evaluation of attribution efficiency.
Results and Evaluation
Key findings highlight the efficacy of Active Indexing:
- Performance Gains: Active Indexing consistently outperforms Passive Indexing. The bidirectional nature of augmentation not only improves citation accuracy but also enhances general performance on knowledge attribution tasks.
- Scalability: Increasing the amount of augmented data results in continuous performance improvement, showing no saturation at even 16 times the original data scale.
- Model Scale Impact: Larger models display more significant improvements in citation precision, highlighting the scalability of the proposed method in terms of model size.
Discussion and Future Directions
The study suggests that reliable internal citation could simplify the deployment of LLMs by eliminating the need for real-time retrieval infrastructure. It opens avenues for more interpretable and transparent AI systems by making knowledge provenance explicit within the model outputs.
Possible future research directions include:
- Evaluating the methodology across different languages and domain-specific corpuses.
- Investigating hybrid models combining internal citation frameworks with retrieval-augmented generation to harness the strengths of both approaches.
- Addressing potential privacy concerns related to model memorization and developing strategies to mitigate inadvertent exposure of sensitive information.
Conclusion
Cite Pretrain demonstrates a promising approach to strengthening LLMs' ability to attribute knowledge to pretraining data without test-time retrieval. By embedding document identifiers as part of the knowledge representation, the framework not only improves citation precision but also positions LLMs for more efficient knowledge management, maintaining the integrity and verifiability of generated content. This method represents a significant step towards enhancing the transparency and robustness of LLM outputs in diverse real-world applications.