- The paper demonstrates that citation methods yield superior evidence quality in LLM responses for long documents, particularly with models like GPT-3.5 and GPT-4.
- It evaluates multiple attribution techniques, revealing that context reduction can disrupt document coherence and limit LLM performance.
- The study highlights a strong correlation between evidence quality and response accuracy, paving the way for more trustworthy AI applications in complex tasks.
Overview of "Attribute or Abstain: LLMs as Long Document Assistants"
"Attribute or Abstain: LLMs as Long Document Assistants" investigates how LLMs can efficiently assist with tasks involving long documents while maintaining high trust and verifiability through attribution. The study evaluates several attribution approaches on diverse LLMs and tasks, proposing LAB, a comprehensive benchmark for long document attribution. The work examines the efficacy of citation-based methods, investigates potential positional biases, and analyzes the correlation between the quality of evidence and responses.
Methods and Approaches
Attribution Techniques
The paper explores several attribution methodologies applicable to long document tasks:
- Post-hoc: Generates a response first, then retrieves supporting evidence.
- Retrieve-then-read: Selects evidence from the document prior to generating a response.
- Citation: Executes response generation and evidence retrieval concurrently.
- Reduced-variants: Employs initial retrieval to focus on a subset of the document, reducing input length.
Benchmark and Model Selection
LAB is designed to test the outlined approaches using six datasets covering QA, classification, NLI, and summarization, each with defined domains like science, law, and governmental documents. The study compares four LLMs: GPT-3.5, GPT-4, Flan-T5-XL, and Longchat, utilizing both prompted and fine-tuned models.
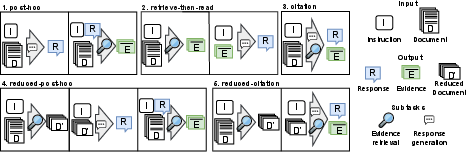
Figure 1: The approaches to attribution in long document scenarios analyzed in this work.
Key Findings and Insights
Optimal Attribution Approaches
- Citation methods generally yielded superior evidence quality compared to other approaches across most tasks, particularly when using large models like GPT-3.5 and GPT-4. This affirms the capability of LLMs to effectively manage retrieval tasks internally.
- Post-hoc methods showed improved performance in summarization tasks and when using smaller models like Longchat.
- The context reduction strategy did not consistently enhance performance, suggesting long documents' logical coherence might be disrupted, affecting LLM processing.
Positional Bias Analysis
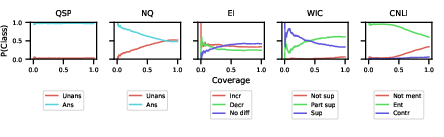
- No significant "Lost in the Middle" phenomenon was observed; however, response quality often diminished when evidence appeared later in documents, indicating a positional performance dependency.
- The evidence distribution analysis reflected that models followed gold distribution patterns except for tasks like GovReport, where biases towards document beginnings were visible.
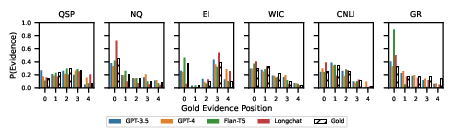
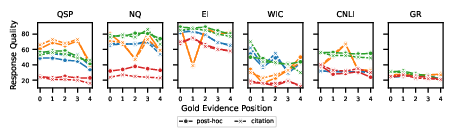
Figure 2: Evidence distribution and response quality analysis across document positions.
Evidence and Response Quality Correlation
Practical Implications and Future Directions
The study indicates that integrating attribution capabilities in LLMs can boost their validity and trustworthiness, especially in exploratory and verification-heavy domains. Moving forward, enhancing LLMs' proficiency in citing evidence for complex claim responses and advancing automatic evaluation models for attributability could elevate LLM usability in professional environments requiring high accuracy and reliability.
Conclusion
"Attribute or Abstain" underscores the potential and complexities of leveraging LLMs for long-document scenarios with a focus on evidence attribution. The insights into models' evidence-retrieval capabilities and positional biases offer a foundation for furthering research in developing more sophisticated AI systems capable of rigorous attribution, enhancing both trust and utility in academic and professional fields.