- The paper presents a novel 4D spatiotemporal prompt methodology that fuses spatial data and temporal cues to better comprehend dynamic scenes.
- It employs a phased training approach with the Chat4D dataset to align visual features with language embeddings for improved scene interpretation.
- Experimental results demonstrate significant gains over traditional models, although challenges remain with fast-moving objects and motion blur.
"LLaVA-4D: Embedding SpatioTemporal Prompt into LMMs for 4D Scene Understanding"
In the pursuit of enhancing the understanding of the physical world, current research has observed limitations in Large Multimodal Models (LMMs) primarily trained on 2D image data. The study outlined in "LLaVA-4D: Embedding SpatioTemporal Prompt into LMMs for 4D Scene Understanding" seeks to address these limitations by proposing a framework that embarks on utilizing a novel 4D spatiotemporal prompt. This allows the model to efficiently handle dynamic scenes that undergo temporal variations, which are commonly observed in real-world environments.
Introduction to 4D Scene Understanding
Existing models tend to overlook dynamic changes within a scene, leading to a subpar understanding of temporal variations and dynamic objects. By introducing a 4D encoding that includes 3D positions and a temporal component, LLaVA-4D attempts to encapsulate the dynamic nature of scenes. This is achieved through a spatiotemporal prompt generated by embedding 4D coordinates into visual features, enabling the distinction between static backgrounds and dynamic objects within a scene.
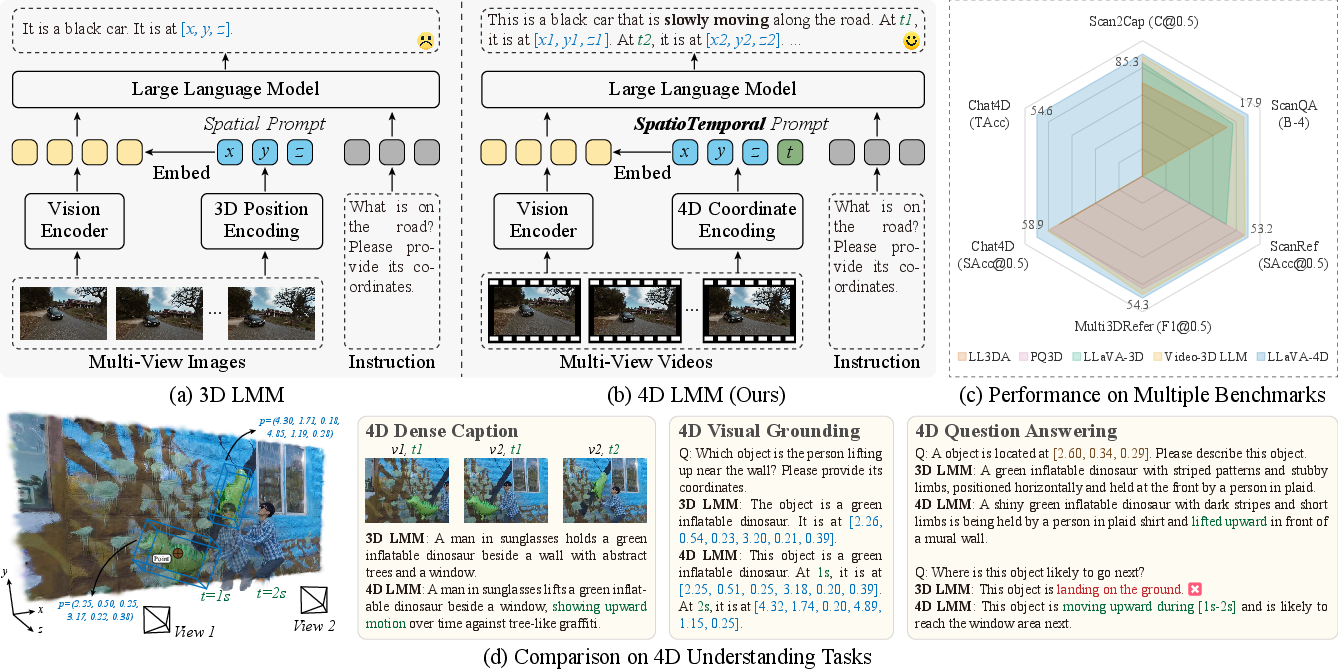
Figure 1: Illustration of existing 3D and novel 4D LMM paradigms, highlighting the integration of time-based dynamics into spatial prompts.
LLaVA-4D Framework
The LLaVA-4D framework operates through a structured process that entails encoding of dynamic-aware 4D coordinates, spatiotemporal disentanglement, and alignment of visual features with language embeddings:
- Dynamic-Aware 4D Coordinate Encoding: This step involves creating 4D coordinates based on spatial (3D) and temporal (1D) data derived from scene observations. It embeds 3D spatial positions and temporal optical flow into learnable prompts that guide feature fusion.
- Spatiotemporal-Disentangled Vision Embedding: By disentangling visual features into spatial and temporal components, this module enhances feature discrimination between objects and backgrounds, effectively integrating 4D coordinate embeddings through cross-attention mechanisms.
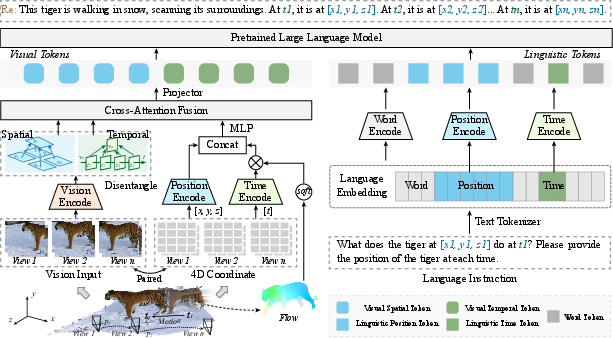
Figure 2: Stages of the LLaVA-4D model, detailing the encoding, embedding, and alignment processes for comprehensive 4D scene understanding.
- Coordinate-Aligned Language Embedding: By projecting visual tokens into a language-compatible space, the model aligns visual and linguistic cues, integrating position and time encodings to enhance holistic scene comprehension.
Dataset and Training Strategy
Moreover, a new dataset, Chat4D, offers structured 4D vision-language data that underlies the training of the proposed model. The training process involves a phased approach:
- Content Alignment with 2D and 3D data initializes the model's spatiotemporal understanding.
- Spatiotemporal Coordinate Alignment refines the correspondence between visual and language cues.
- 4D Task Instruction Fine-Tuning employs specific 4D data to optimize for spatiotemporal comprehension.
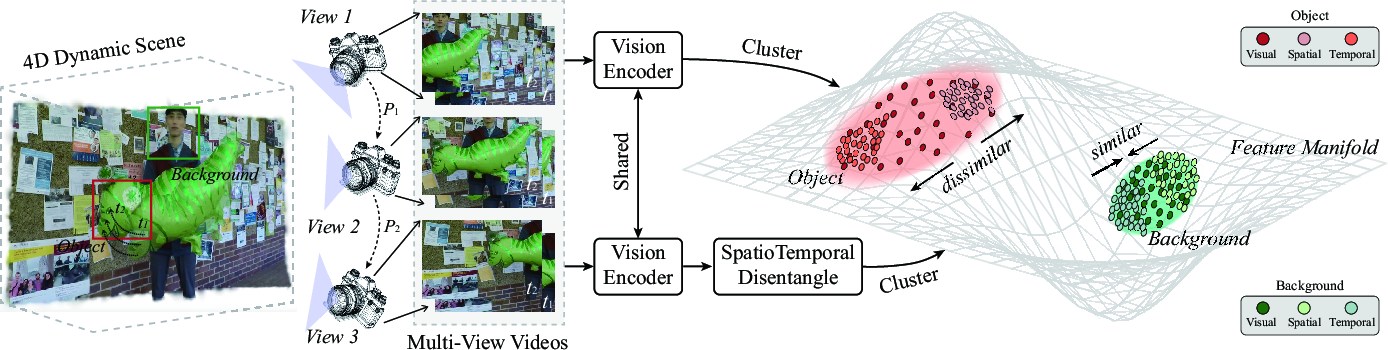
Figure 3: Overview of Chat4D dataset and its integration stages for model training.
Experimental Results
The model's performance is evaluated against state-of-the-art 3D LMMs on benchmarks involving 3D and 4D datasets. Quantitative results indicate significant improvements in scene understanding tasks, largely attributed to the innovative spatiotemporal prompts and feature disentanglement.
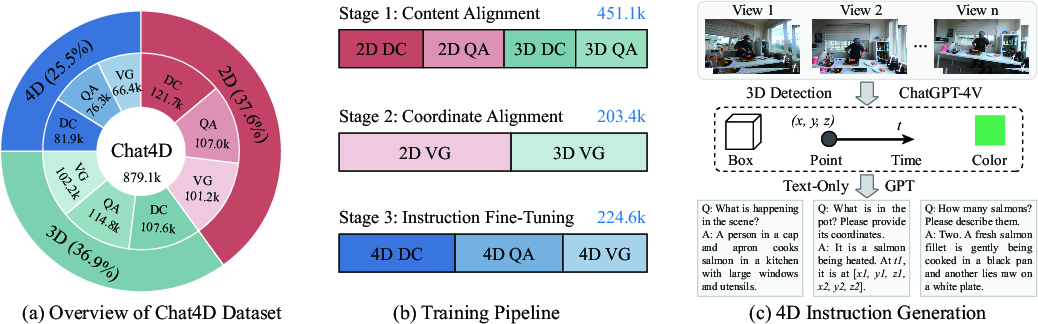
Figure 4: Comparative analysis illustrating the advancements in 4D scene understanding provided by LLaVA-4D.
Discussion
The enhancements in LLaVA-4D demonstrate that integrating dynamic spatiotemporal prompts significantly bolsters understanding in real-world scenarios. However, limitations persist, particularly concerning fast-moving objects where motion blur may degrade feature clarity. Future explorations could incorporate event-based sensing technologies, potentially mitigating such limitations.
Conclusion
In summary, LLaVA-4D offers a compelling advance in LMM technology, providing a notable framework to navigate the complexities of 4D scene understanding. It merges spatial and temporal dynamics into a comprehensive model capable of addressing the intricacies of dynamic and static scene elements, setting the stage for refined real-world AI applications.