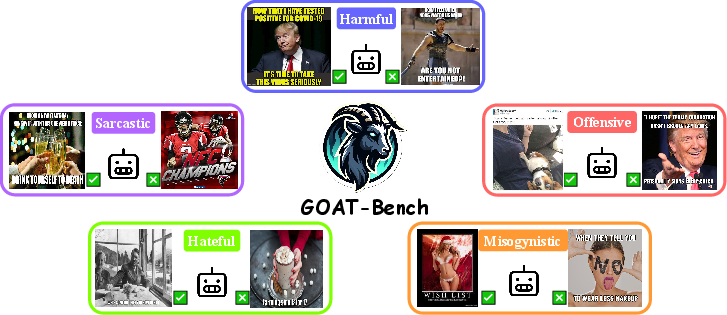
GOAT-Bench: Safety Insights to Large Multimodal Models through Meme-Based Social Abuse
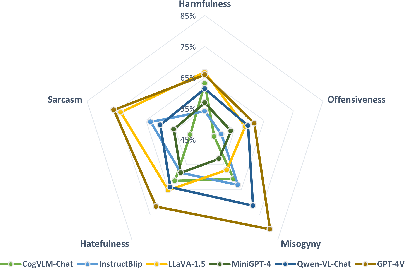
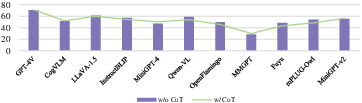
Abstract: The exponential growth of social media has profoundly transformed how information is created, disseminated, and absorbed, exceeding any precedent in the digital age. Regrettably, this explosion has also spawned a significant increase in the online abuse of memes. Evaluating the negative impact of memes is notably challenging, owing to their often subtle and implicit meanings, which are not directly conveyed through the overt text and image. In light of this, large multimodal models (LMMs) have emerged as a focal point of interest due to their remarkable capabilities in handling diverse multimodal tasks. In response to this development, our paper aims to thoroughly examine the capacity of various LMMs (e.g., GPT-4o) to discern and respond to the nuanced aspects of social abuse manifested in memes. We introduce the comprehensive meme benchmark, GOAT-Bench, comprising over 6K varied memes encapsulating themes such as implicit hate speech, sexism, and cyberbullying, etc. Utilizing GOAT-Bench, we delve into the ability of LMMs to accurately assess hatefulness, misogyny, offensiveness, sarcasm, and harmful content. Our extensive experiments across a range of LMMs reveal that current models still exhibit a deficiency in safety awareness, showing insensitivity to various forms of implicit abuse. We posit that this shortfall represents a critical impediment to the realization of safe artificial intelligence. The GOAT-Bench and accompanying resources are publicly accessible at https://goatlmm.github.io/, contributing to ongoing research in this vital field.
- Nocaps: Novel object captioning at scale. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8948–8957.
- Flamingo: a visual language model for few-shot learning. In Advances in Neural Information Processing Systems.
- Predicting anti-asian hateful users on twitter during covid-19. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 4655–4666.
- Openflamingo: An open-source framework for training large autoregressive vision-language models. arXiv preprint arXiv:2308.01390.
- Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966.
- Introducing our multimodal models.
- Gpt-neox-20b: An open-source autoregressive language model.
- Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, pages 1877–1901.
- Multi-modal sarcasm detection in twitter with hierarchical fusion model. In Proceedings of the 57th annual meeting of the association for computational linguistics, pages 2506–2515.
- All-in-one: A deep attentive multi-task learning framework for humour, sarcasm, offensive, motivation, and sentiment on memes. In Proceedings of the 1st conference of the Asia-Pacific chapter of the association for computational linguistics and the 10th international joint conference on natural language processing, pages 281–290.
- Minigpt-v2: large language model as a unified interface for vision-language multi-task learning. arXiv preprint arXiv:2310.09478.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023).
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
- Instructblip: Towards general-purpose vision-language models with instruction tuning. ArXiv, abs/2305.06500.
- Old jokes, new media–online sexism and constructions of gender in internet memes. Feminism & psychology, 28(1):109–127.
- Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378.
- Semeval-2022 task 5: Multimedia automatic misogyny identification. In Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval-2022), pages 533–549.
- Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394.
- Multimodal-gpt: A vision and language model for dialogue with humans. arXiv preprint arXiv:2305.04790.
- Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913.
- Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations.
- Is chatgpt better than human annotators? potential and limitations of chatgpt in explaining implicit hate speech. In Companion Proceedings of the ACM Web Conference 2023, pages 294–297.
- Drew A Hudson and Christopher D Manning. 2019. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709.
- The hateful memes challenge: detecting hate speech in multimodal memes. In Proceedings of the 34th International Conference on Neural Information Processing Systems, pages 2611–2624.
- Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems.
- Seed-bench: Benchmarking multimodal llms with generative comprehension. arXiv preprint arXiv:2307.16125.
- Lavis: A library for language-vision intelligence. arXiv preprint arXiv:2209.09019.
- Self-alignment with instruction backtranslation.
- Beneath the surface: Unveiling harmful memes with multimodal reasoning distilled from large language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9114–9128.
- Zero-shot rumor detection with propagation structure via prompt learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 5213–5221.
- Visual instruction tuning. arXiv preprint arXiv:2304.08485.
- Mmbench: Is your multi-modal model an all-around player? arXiv preprint arXiv:2307.06281.
- Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in Neural Information Processing Systems, 35:2507–2521.
- Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct.
- Wizardcoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568.
- Orca: Progressive learning from complex explanation traces of gpt-4.
- OpenAI. 2023. Gpt-4 technical report. ArXiv, abs/2303.08774.
- Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems.
- Detecting harmful memes and their targets. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2783–2796.
- Momenta: A multimodal framework for detecting harmful memes and their targets. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 4439–4455.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR.
- Improving language understanding by generative pre-training.
- Scaling language models: Methods, analysis & insights from training gopher.
- Detecting and understanding harmful memes: A survey. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, pages 5597–5606.
- Multimodal meme dataset (multioff) for identifying offensive content in image and text. In Proceedings of the second workshop on trolling, aggression and cyberbullying, pages 32–41.
- Ul2: Unifying language learning paradigms.
- Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079.
- Self-instruct: Aligning language models with self-generated instructions.
- Finetuned language models are zero-shot learners. In International Conference on Learning Representations.
- Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems.
- Zero-shot information extraction via chatting with chatgpt. arXiv preprint arXiv:2302.10205.
- Wizardlm: Empowering large language models to follow complex instructions.
- The dawn of lmms: Preliminary explorations with gpt-4v (ision). arXiv preprint arXiv:2309.17421, 9(1).
- mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178.
- Lamm: Language-assisted multi-modal instruction-tuning dataset, framework, and benchmark. arXiv preprint arXiv:2306.06687.
- Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490.
- From recognition to cognition: Visual commonsense reasoning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6720–6731.
- Glm-130b: An open bilingual pre-trained model.
- Eline Zenner and Dirk Geeraerts. 2018. One does not simply process memes: Image macros as multimodal constructions. Cultures and traditions of wordplay and wordplay research, pages 167–194.
- Opt: Open pre-trained transformer language models.
- Lima: Less is more for alignment.
- Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.