- The paper introduces a novel method using pre-trained UQ heads to detect hallucinations in LLM outputs.
- The approach leverages transformer attention maps to generate uncertainty scores, significantly improving precision-recall metrics.
- Results demonstrate superior performance and cross-lingual generalization, enabling seamless integration into existing frameworks.
Pre-trained Uncertainty Quantification Heads for Hallucination Detection in LLM Outputs
The paper "A Head to Predict and a Head to Question: Pre-trained Uncertainty Quantification Heads for Hallucination Detection in LLM Outputs" introduces a novel approach to tackling a critical issue in LLMs — the tendency to generate hallucinated, or factually incorrect, information. This work centers around the development and evaluation of pre-trained uncertainty quantification (UQ) heads, which are auxiliary modules designed to enhance the ability of LLMs to assess their output reliability.
Introduction and Motivation
LLMs suffer from a significant drawback; they occasionally produce outputs that, while fluent, include unsupported or fabricated facts. Such hallucinations pose risks, especially in applications requiring high trust in the generated content. Uncertainty quantification offers a framework for estimating the reliability of model outputs, potentially flagging hallucinations by identifying high uncertainty levels in the model's predictions.
Methodology
The authors propose supervised UQ heads that leverage the transformer architecture and the inherent attention mechanisms of LLMs. These UQ heads are trained to output uncertainty scores for the generated text, helping to distinguish between accurate outputs and hallucinations.
The UQ heads utilize features derived from attention maps within the LLMs, capturing the conditional dependencies in text generation. This is significant given that existing unsupervised methods do not exploit these internal model states efficiently. The feature extraction process focuses on attention maps and probability distributions rather than more computationally intensive hidden state modeling.
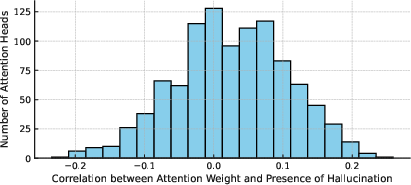
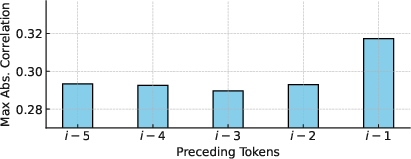
Figure 1: Correlation across various attention heads.
Results and Findings
The pre-trained UQ heads demonstrate state-of-the-art performance in detecting claim-level hallucinations across multiple datasets and LLM architectures, outperforming existing methods. When evaluated in both in-domain and out-of-domain scenarios, these models showcased robust generalization capabilities, including cross-lingual applicability without needing specific training data for each language.
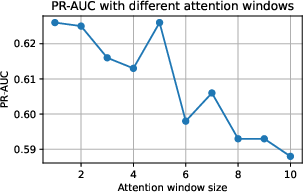
Figure 2: PR-AUC for different attention window sizes using UHead for Mistral 7B Instruct v0.2 model.
One key aspect highlighted is the superior performance in terms of precision-recall area under the curve (PR-AUC) metrics, notably improving upon baseline methods such as Maximum Claim Probability and Mean Token Entropy.
Feature and Architecture Analysis
An extensive analysis revealed that attention-derived features were most informative for hallucination detection compared to hidden state-based approaches. The UQ head architecture, based on a transformer backbone, effectively processes these features, marking a significant advancement over simpler models like linear classifiers used in prior research.
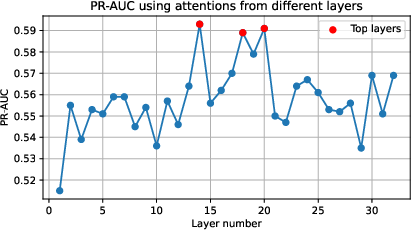
Figure 3: PR-AUC as a function of layer number used for attention features in UHead for Mistral 7B Instruct v0.2 model. Highlighted points mark layers with highest PR-AUC (layers 14, 18 and 20).
Practical Implications and Future Directions
These UQ heads can be seamlessly integrated into existing text generation frameworks, providing a lightweight, computationally efficient solution to enhance the trustworthiness of LLM outputs. The heads are available for a range of popular LLMs, making them accessible for immediate use in various applications.
The research suggests that increasing the diversity and size of training data could further enhance the performance of these UQ heads, especially in unknown domains. This points to an exciting avenue for future exploration, potentially extending these methods to even larger and more varied datasets.
Conclusion
The development of pre-trained UQ heads represents a practical advancement in detecting hallucinations in LLM outputs, combining robust performance and computational efficiency. Their ability to generalize across domains and languages without extensive re-training sets a promising precedent for future applications in AI, aiming to reduce the impact of hallucinations in real-world deployments.