- The paper presents a comprehensive framework for hallucination detection in LLM responses by integrating black-box, white-box, LLM judge, and ensemble methods.
- It employs diverse metrics such as EMR, NCP, LNTP, and others to generate interpretable confidence scores and improve detection across multiple benchmarks.
- The open-source toolkit uqlm facilitates practical deployment and ensemble optimization to enhance LLM reliability in high-stakes domains.
Uncertainty Quantification for LLMs: A Suite of Black-Box, White-Box, LLM Judge, and Ensemble Scorers
Introduction and Motivation
The persistent issue of hallucinations in LLMs, especially in high-stakes domains such as healthcare and finance, necessitates robust, real-time hallucination detection mechanisms. This work presents a comprehensive, zero-resource framework for hallucination detection, leveraging a suite of uncertainty quantification (UQ) techniques—black-box, white-box, LLM-as-a-Judge, and a tunable ensemble of these methods. The framework is designed for practical deployment, offering standardized, interpretable response-level confidence scores and is accompanied by an open-source Python toolkit, uqlm, to facilitate adoption.
Methodological Framework
The core task is binary classification: determining whether an LLM response contains a hallucination (nonfactual content). Each method produces a confidence score s^(yi)∈[0,1] for a response yi, with a threshold τ used to flag hallucinations. The framework standardizes all scores to [0,1] for comparability and interpretability.
Black-Box UQ Scorers
Black-box methods exploit the stochasticity of LLMs by generating multiple candidate responses to the same prompt and measuring semantic consistency:
- Exact Match Rate (EMR): Proportion of candidate responses exactly matching the original.
- Non-Contradiction Probability (NCP): Uses an NLI model (microsoft/deberta-large-mnli) to estimate the average probability that candidate responses do not contradict the original.
- BERTScore (BSC): Computes the average F1 BERTScore between the original and candidates.
- Normalized Cosine Similarity (NCS): Uses sentence transformer embeddings to compute normalized cosine similarity.
- Normalized Semantic Negentropy (NSN): Clusters responses by mutual entailment and computes normalized negentropy as a measure of response volatility.
White-Box UQ Scorers
White-box methods utilize token-level probabilities from the LLM:
- Length-Normalized Token Probability (LNTP): Geometric mean of token probabilities, normalized by response length.
- Minimum Token Probability (MTP): Minimum token probability in the response.
LLM-as-a-Judge Scorers
This approach prompts an LLM to rate the correctness of a question-answer pair on a 0–100 scale, normalized to [0,1]. The prompt is carefully engineered to elicit a direct numerical score, minimizing ambiguity and maximizing instruction adherence.
Tunable Ensemble Scorer
A linear, weighted ensemble combines any subset of the above scorers. Weights are optimized using a graded dataset and a classification objective (e.g., AUROC or F1), with optimization performed via Optuna. The ensemble is extensible, allowing practitioners to incorporate new scorers as the field evolves.
Experimental Evaluation
Datasets and Models
Experiments span six QA benchmarks (GSM8K, SVAMP, CSQA, AI2-ARC, PopQA, NQ-Open) and four LLMs (GPT-3.5, GPT-4o, Gemini-1.0-Pro, Gemini-1.5-Flash). For each question, 15 candidate responses are generated per LLM, and all scorer types are computed where API access permits.
Performance is evaluated using AUROC and F1-score, both in threshold-agnostic and threshold-optimized settings. The ensemble scorer consistently outperforms individual methods in the majority of scenarios (18/24 for AUROC, 16/24 for F1), with scenario-specific best AUROC values ranging from 0.72 to 0.93.

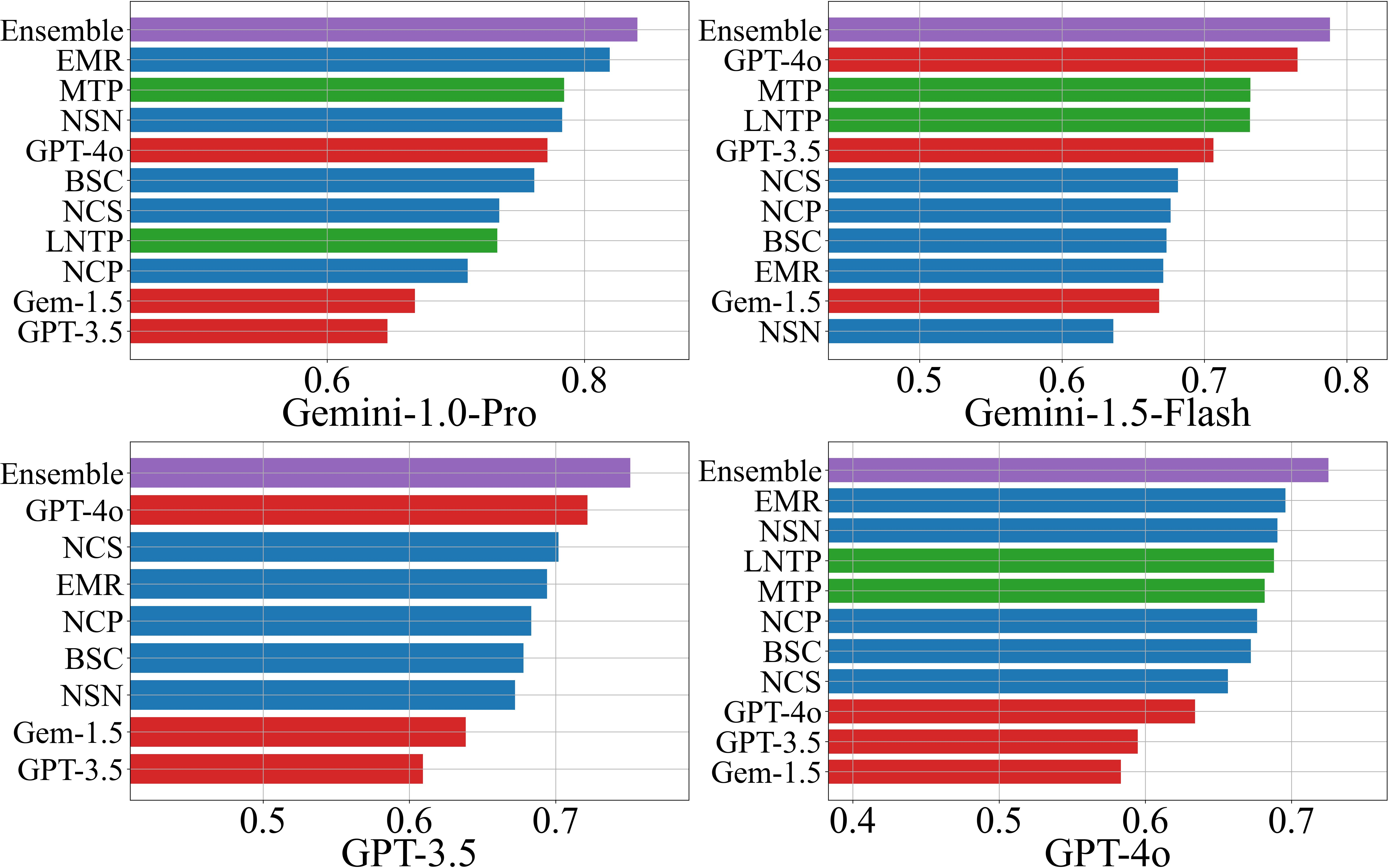
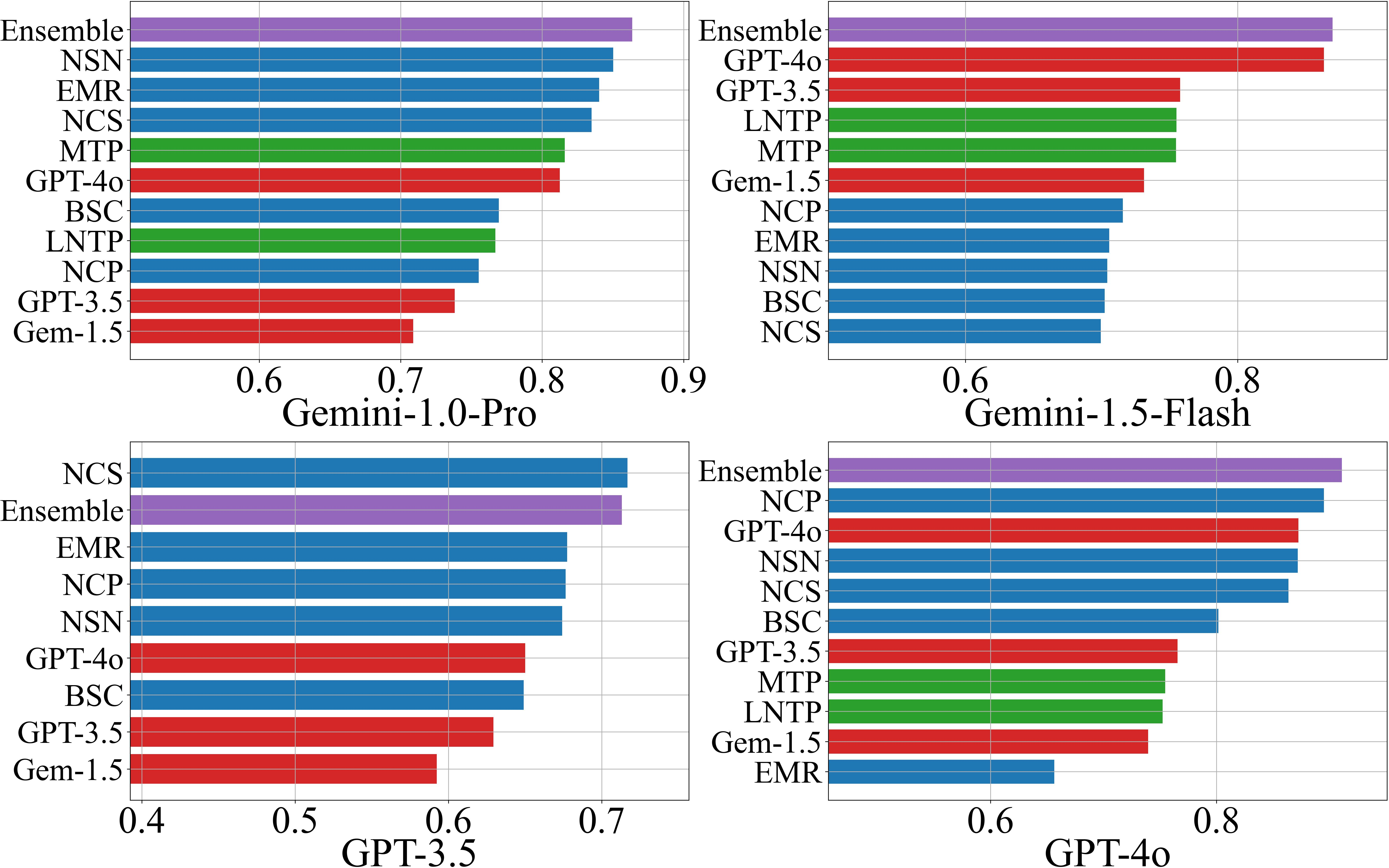
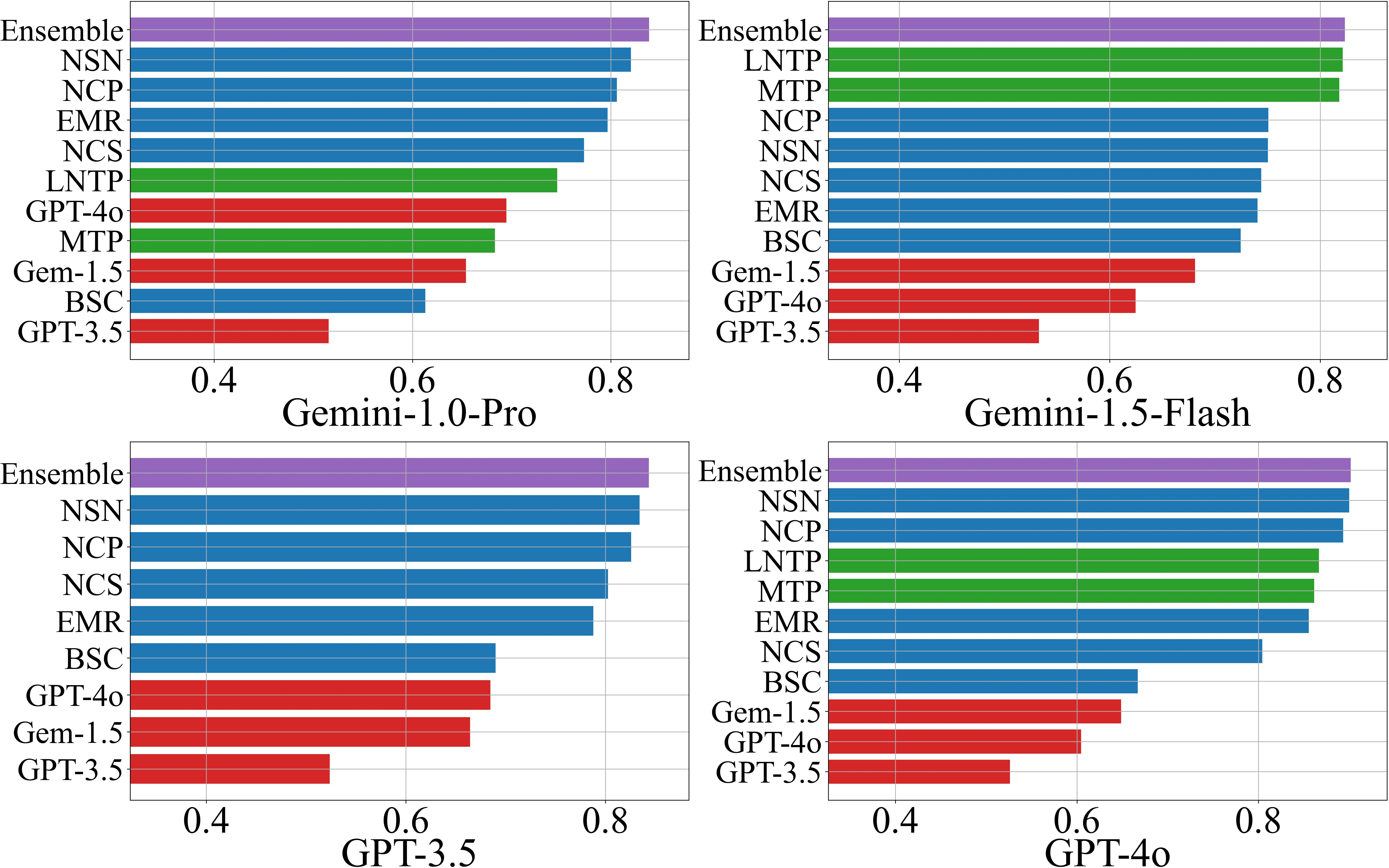
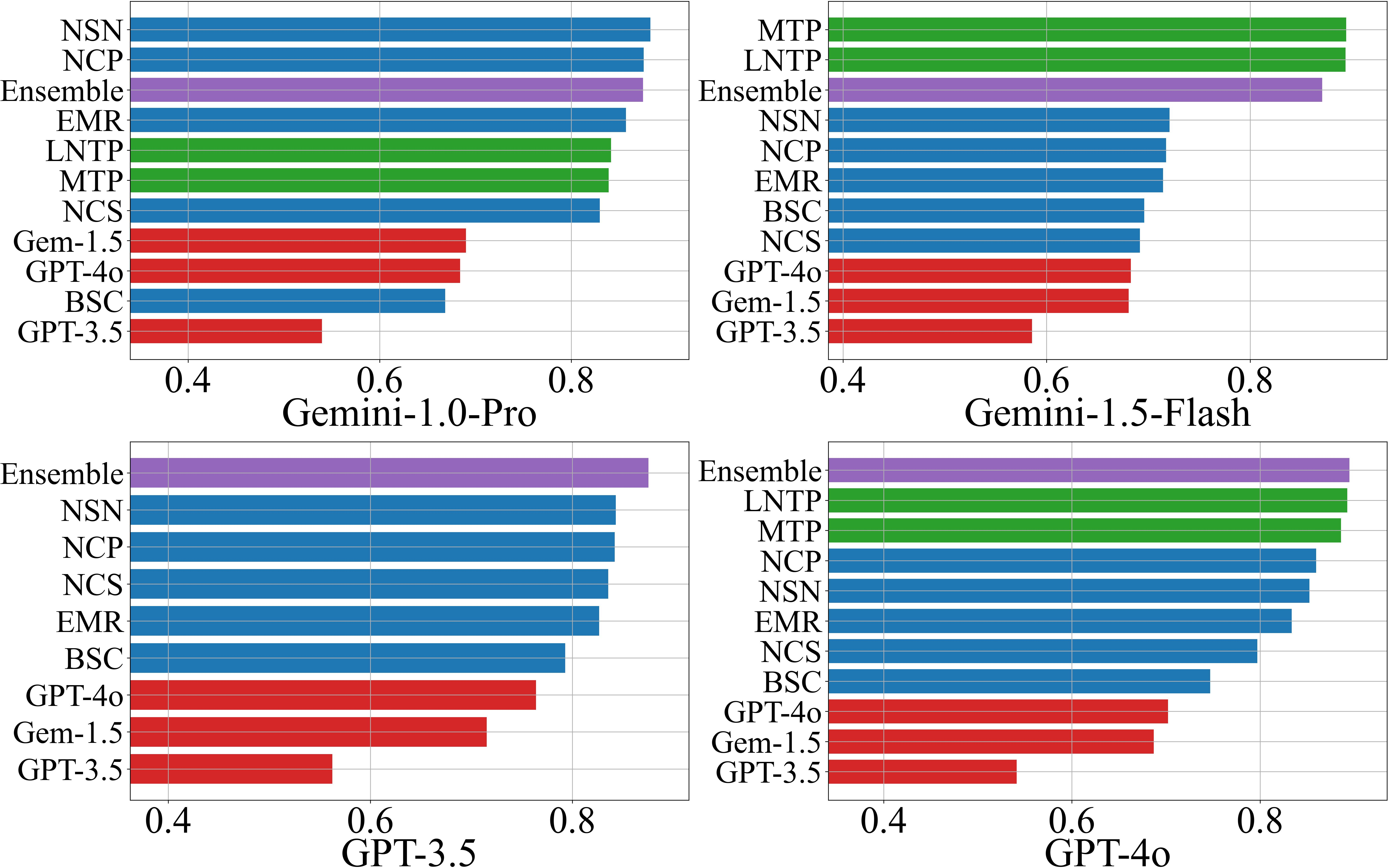
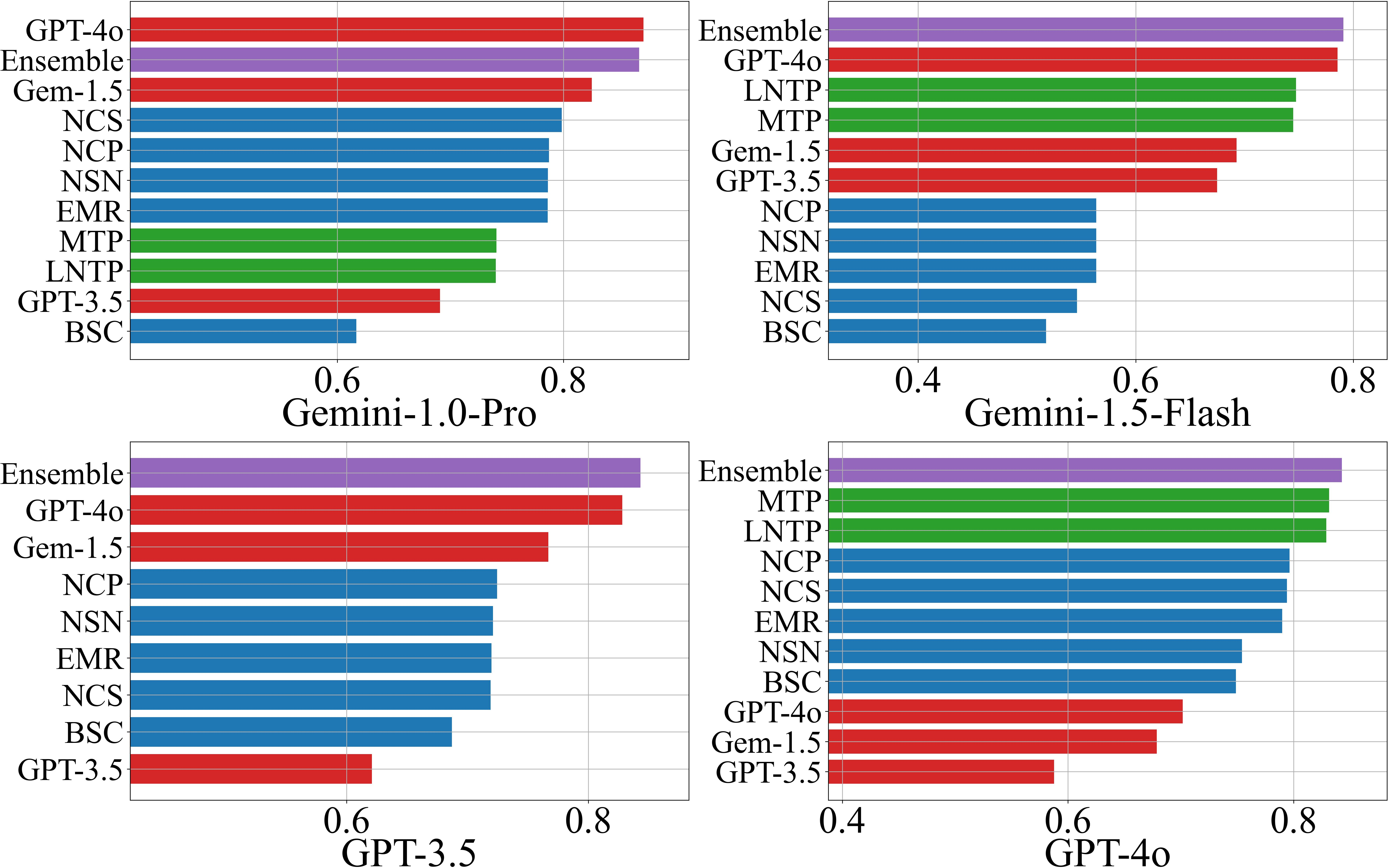
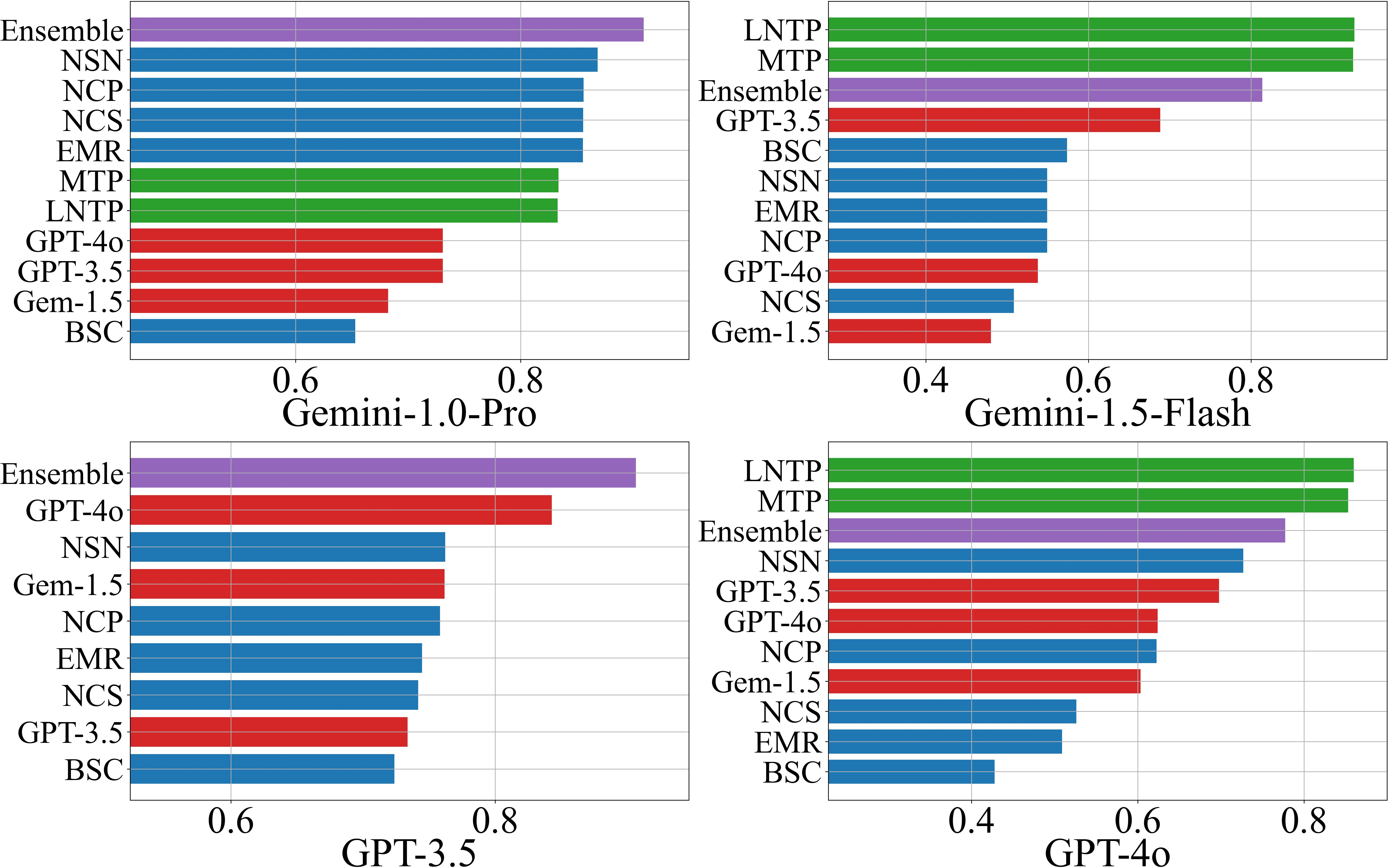
Figure 1: AUROC scores for hallucination detection on the NQ Open dataset, comparing individual and ensemble scorers across LLMs.
Key findings include:
- NLI-based black-box scorers (NSN, NCP) dominate among black-box methods, especially when response diversity is high.
- LLM-as-a-Judge performance correlates with the judge model's own accuracy on the dataset, with GPT-4o outperforming other judges in 19/24 scenarios.
- White-box scorers (LNTP, MTP) perform similarly and are preferable when token probabilities are accessible.
- Ensemble methods provide robust, use-case-optimized performance, leveraging the strengths of individual scorers.
Filtered Accuracy and Practical Utility
Filtered Accuracy@τ demonstrates that filtering responses by confidence score yields monotonic improvements in accuracy, except in cases where response diversity is minimal (e.g., Gemini-1.5-Flash on CSQA/AI2-ARC, where EMR ≈1). This highlights a limitation of black-box methods in low-variance regimes.
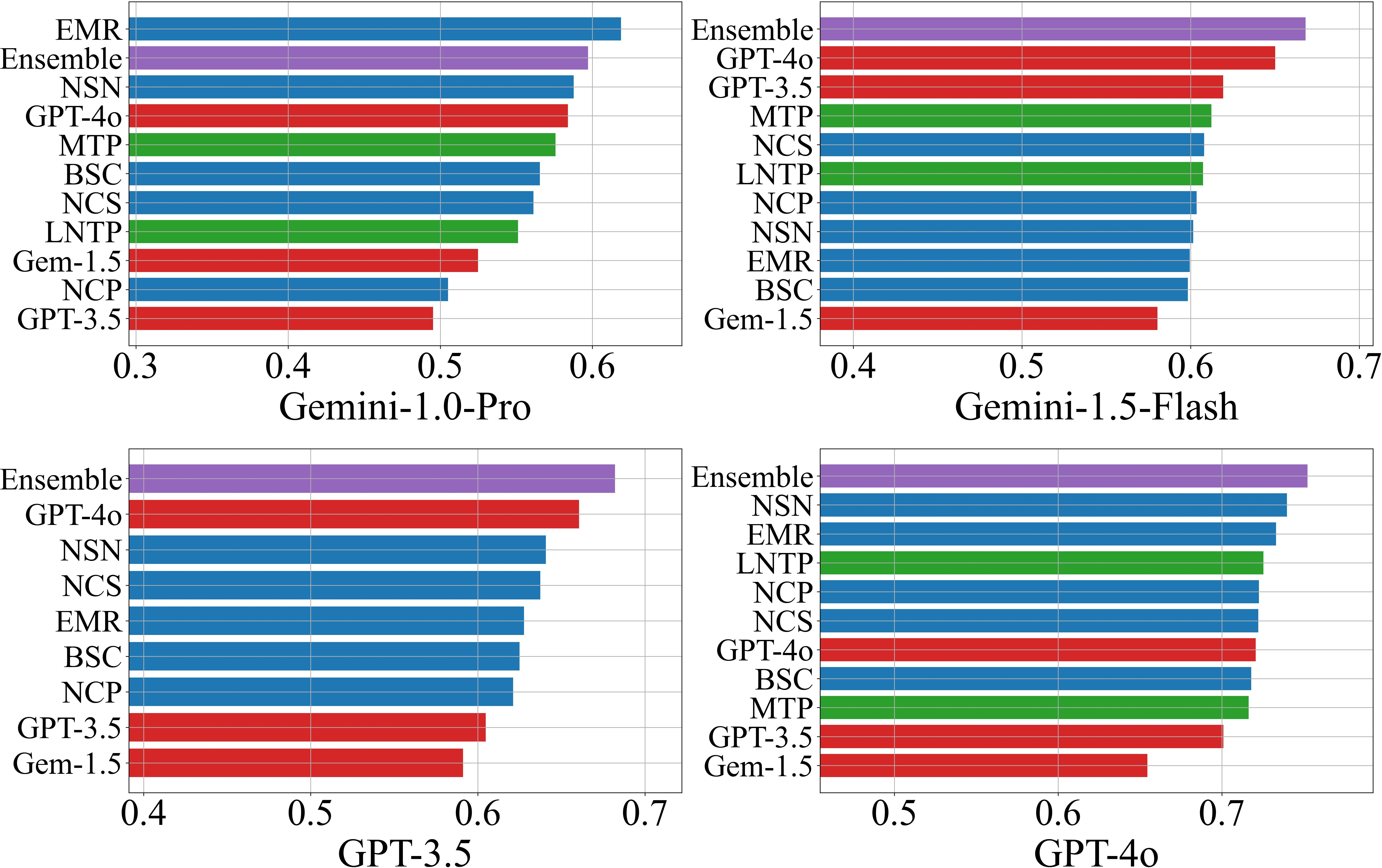
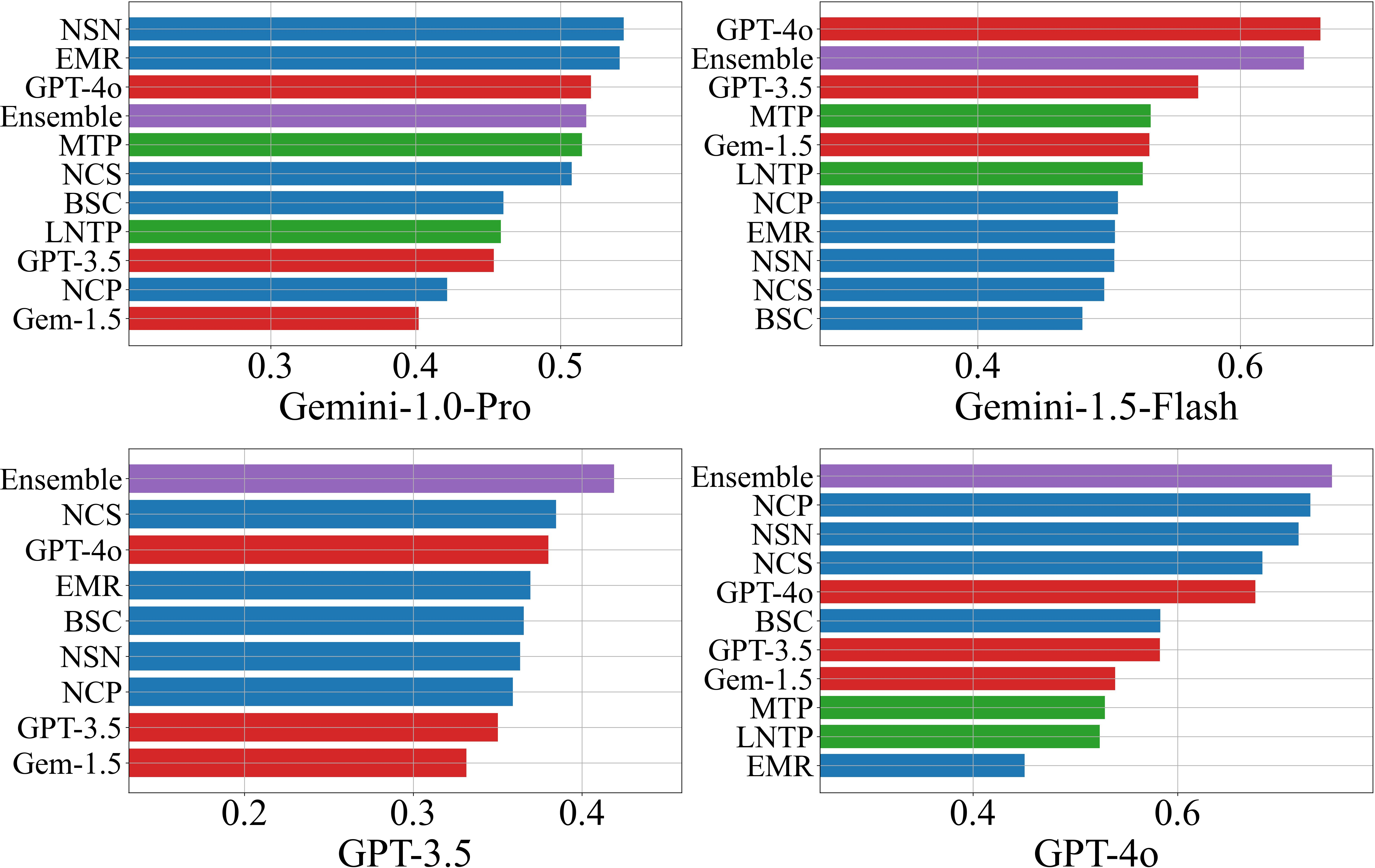
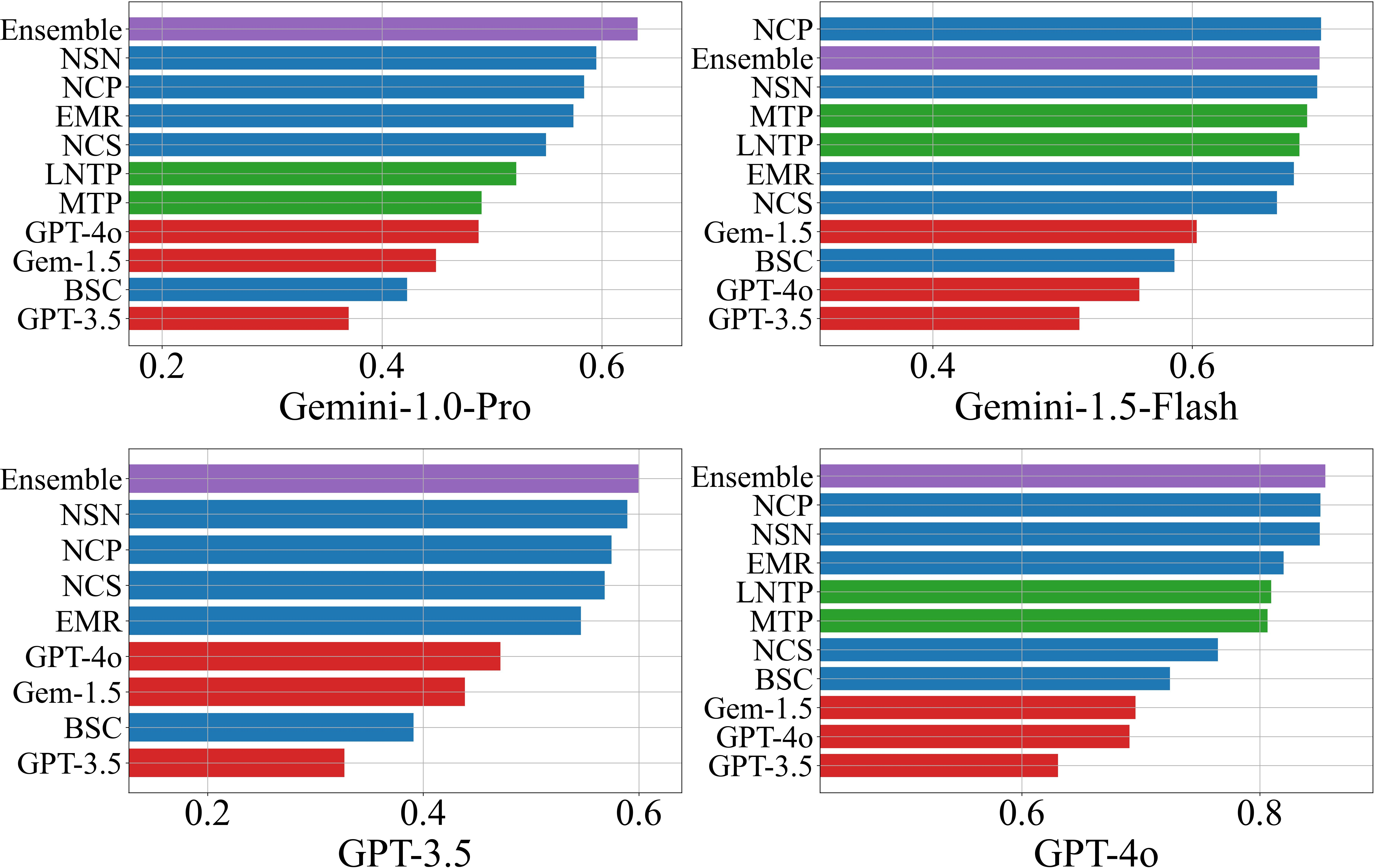
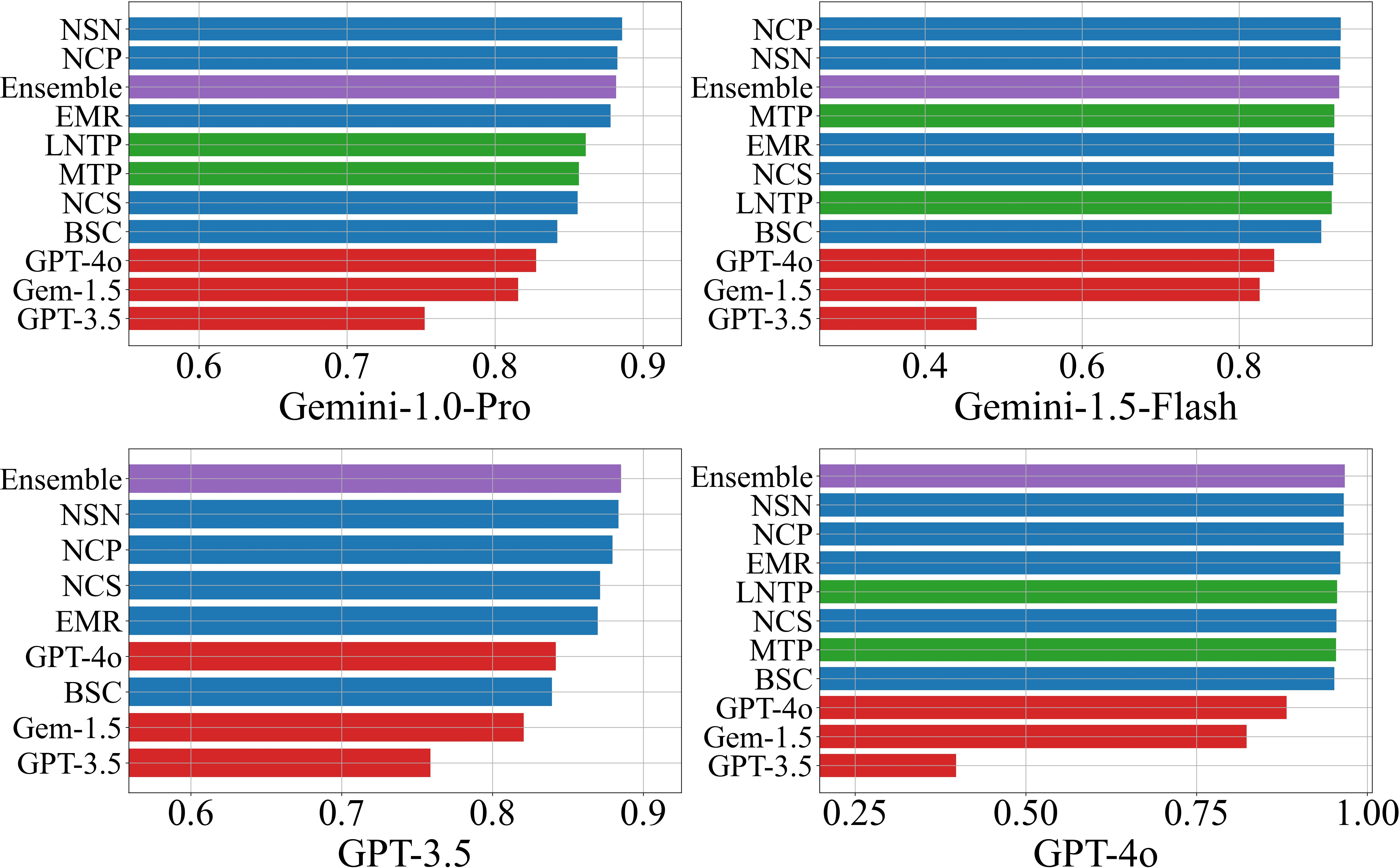
Figure 2: Filtered accuracy versus confidence threshold for NQ Open, illustrating the utility of confidence-based response filtering.
Computational Considerations
- Black-box methods incur additional latency and cost proportional to the number of candidate responses (m), with diminishing returns for m>10.
- White-box methods are computationally efficient but require API support for token probabilities.
- LLM-as-a-Judge introduces additional inference cost and latency, but is effective when high-quality judge models are available.
- Ensemble tuning requires a graded dataset and optimization overhead, but yields superior performance.
Implementation and Deployment
The uqlm toolkit provides ready-to-use implementations for all scorers, supporting integration with arbitrary LLMs and prompt formats. Practitioners can select and combine scorers based on API capabilities, latency constraints, and the availability of labeled data for ensemble tuning. The framework supports both real-time monitoring (generation-time scoring) and pre-deployment diagnostics.
Implications and Future Directions
This work provides a practical, extensible foundation for hallucination detection in LLMs, emphasizing the importance of use-case-specific customization. The empirical results underscore that no single method is universally optimal; rather, ensemble approaches tailored to the deployment context yield the best results. The positive correlation between a model's accuracy and its effectiveness as a judge suggests a principled approach to judge selection in evaluation pipelines.
Future research directions include:
- Extending the framework to long-form and summarization tasks, where current benchmarks are lacking.
- Exploring non-linear and more sophisticated ensembling strategies.
- Investigating the integration of retrieval-augmented or source-aware methods within the zero-resource paradigm.
- Adapting the framework for continual learning and online calibration in production systems.
Conclusion
The presented framework and toolkit enable robust, interpretable, and customizable hallucination detection for LLMs across diverse application domains. By standardizing and combining black-box, white-box, and LLM-as-a-Judge methods, and providing a tunable ensemble mechanism, the approach delivers strong empirical performance and practical deployment guidance. The extensibility of the ensemble and the open-source implementation position this work as a foundation for ongoing advances in LLM reliability and safety.

