- The paper introduces a synthetic imputation approach that leverages prompt engineering to generate diverse texts for underrepresented categories.
- It employs a controlled few-shot method to enhance lexical and semantic variation, significantly reducing model overfitting.
- Empirical results demonstrate near baseline F1-scores with moderate sample sizes, validating its efficacy over traditional augmentation techniques.
Synthetic Imputation for Augmenting Underrepresented Categories in Supervised Text Classification
Introduction
The challenge of data imbalance in supervised text classification remains a persistent bottleneck, particularly in annotation tasks using encoder-decoder LLMs such as BERT and RoBERTa. Conventional strategies for data augmentation frequently fail to introduce sufficient lexical and semantic diversity, leading to overfitting and suboptimal out-of-sample generalization. "The Synthetic Imputation Approach: Generating Optimal Synthetic Texts For Underrepresented Categories In Supervised Classification Tasks" (2504.15160) contributes a systematic solution to this problem by leveraging prompt-engineered generative LLMs to synthesize high-variance, category-conforming training texts. This essay provides an expert summary of the proposed method, evaluates its experimental efficacy, and examines its broader implications for supervised learning and text analysis workflows.
The central issue addressed is insufficient per-category sample size, which disrupts effective mini-batch-based learning in deep architectures. When underrepresented categories are rare or difficult to annotate, both category-level and model-wide metrics (e.g., F1-score) degrade sharply, even in well-structured corpora. Common approaches—rule-based token manipulations, sentence interpolation, or manifold-based augmentations—produce synthetic samples that suffer from high similarity to the training pool, inflating in-sample metrics and failing to transfer to unseen data.
Synthetic Imputation: Methodological Framework
The synthetic imputation approach operationalizes synthetic instance generation via a controlled few-shot prompting scheme using a generative LLM (GPT-4o; also compatible with Llama or Claude). Its core protocol is as follows:
- Seed Selection: At least 50 representative texts are selected per underrepresented category to serve as generation seeds. Sampling below this threshold increases the risk of synthetic-exemplar homogeneity and model overfitting.
- Few-Shot Prompt Construction: For each synthetic text generation, five seed examples are randomly selected with replacement and incorporated into an explicit prompt, which instructs the LLM to vary content, sentence structure, and named entities, while preserving the categorical semantic core.
- Supervising Output Diversity: Researchers actively validate that synthetically generated texts are sufficiently divergent in both grammar and semantics, tuning prompts as necessary to further modulate diversity.
- Dataset Expansion: The sum of original and synthetic texts per category is increased to at least 200 instances, aligning with batch size requirements for robust mini-batch stochastic gradient descent in models such as RoBERTa.
This pipeline is diagrammed in the procedural flow below:

Figure 1: Schematic of the synthetic imputation approach for generating lexically and semantically diverse category-conforming texts using few-shot LLM prompting.
Comparative Evaluation: Empirical Results
Political Nostalgia
The approach is first validated using the Political Nostalgia dataset, in which only 151 out of 1,200 annotated sentences are labeled as "nostalgic." Models fine-tuned solely on small original samples (e.g., n=50) experience a catastrophic loss in F1-score (0.471), while naïve synthetic augmentation techniques (e.g., SSMBA) generate texts overly similar to existing cases, resulting in high in-sample F1-scores but poor generalization due to overfitting. In contrast, the synthetic imputation method, using 50 original and 101 synthetic samples, achieves an F1-score of 0.851 (overfitting only 3.5% above the true model performance of 0.822). At 75 original and 76 synthetic samples, the F1-score matches the full-data model (0.822 vs. 0.829), and with 100 original plus 51 synthetic, the result is indistinguishable from the baseline.
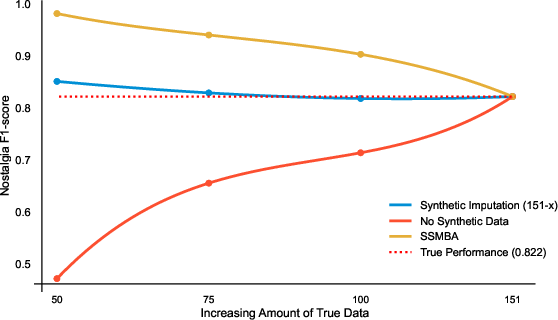
Figure 2: F1-score analysis for the "nostalgic" category showing the convergence of synthetic imputation models to true model performance, and their clear superiority over SSMBA and data-poor baselines.
International Speeches
A second test with the Global Populism Dataset’s "international speech" category corroborates these findings, with the synthetic imputation approach matching or exceeding the original-data model’s F1-score (0.895). Even with only 50 originals augmented by 150 synthetics, overfitting remains modest at 3.1%. While SSMBA yields synthetics with excessive inter-sample similarity and pronounced overfitting, synthetic imputation maintains a stable, predictable level of bias, always in the positive direction and small magnitude.
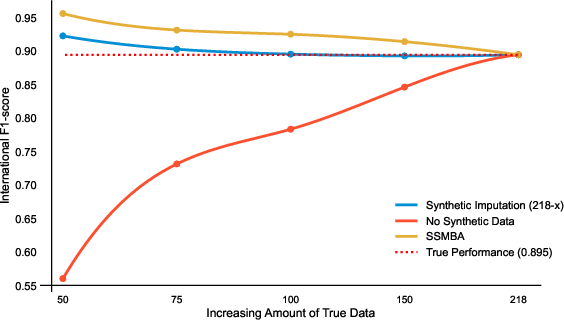
Figure 3: F1-score trajectories for international speeches, demonstrating that synthetic imputation achieves near-identical performance to fully supervised models above 75 true samples, with sharply reduced overfitting relative to SSMBA.
Theoretical and Applied Implications
The synthetic imputation approach formalizes a critical best practice that aligns with the statistical underpinnings of data augmentation in high-dimensional NLP: synthetics should increase within-category variance while maintaining semantic fidelity, preventing the inflation of model capacity for category memorization at the expense of generalization. With a minimal empirical requirement of 75 original texts per category, researchers can address rare-category underrepresentation without merging categories or abandoning analyses—a key practical advance for political and social science studies.
On the methodological front, the approach quantitatively outperforms SSMBA by 6–15% reduction in overfitting and scales robustly to binary and multiclass settings. Predictable, correctable overfitting (2–4% at n=50) can be analytically penalized, yielding more reliable downstream inference and measurement.
Prospects for Future AI Developments
Broader adoption of synthetic imputation in annotation pipelines will likely drive further research into robust prompt engineering and automated diversity assessment in LLM-generated corpora. As LLMs continue to improve their text-generation diversity and semantic control, it is plausible that recombination strategies—perhaps via learned prompting or adversarial mechanisms—will further minimize even the small residual overfitting observed here. Integrating synthetic imputation with active learning or uncertainty-driven data collection could further optimize annotation effort allocation, especially in domains where category frequencies are inherently low.
Conclusion
The synthetic imputation approach provides a principled, empirically validated method for augmenting underrepresented categories in supervised text classification. At moderate sample sizes (n≥75), model performance using synthetic imputation matches that of models trained with complete, original data, while significantly reducing overfitting compared to prevailing augmentation algorithms. In practice, this approach expands the feasible scope of annotation-based studies and minimizes the trade-offs among data quality, model accuracy, and annotation budget. Its extensibility to other supervised tasks and high-level simplicity render it a compelling addition to the methodological toolkit in AI-driven text analysis.

