- The paper introduces EntroDrop, an entropy-based pruning strategy that leverages entropy metrics to identify and remove less informative Transformer blocks.
- It details a two-stage framework that preserves early layers while pruning blocks in later layers with minimal entropy gain.
- Empirical evaluations using Bucket and KNN estimations reveal significant inference speedups and maintained accuracy across diverse datasets.
Entropy-Based Block Pruning for Efficient LLMs
Introduction
The paper "Entropy-Based Block Pruning for Efficient LLMs" focuses on optimizing the deployment of LLMs by reducing their computational and storage burden through an innovative pruning strategy. The proposed method, EntroDrop, introduces entropy as a metric to identify and prune redundant blocks in Transformer architectures, surpassing traditional methods that utilize cosine similarity. Empirical analyses reveal that entropy in hidden representations decreases initially but increases across later Transformer blocks, underscoring entropy's potential as an indicator of information richness.
Entropy Dynamics in LLMs
The analysis begins by examining the entropy dynamics of Transformer models, such as Llama3.1-8B and Mistral-7B-v0.3, during inference. The findings indicate an entropy decrease in the initial layers, followed by an increase as the process continues. This biphasic behavior suggests that while early layers prioritize compressing and structuring input representations, later layers focus on expanding contextual understanding.
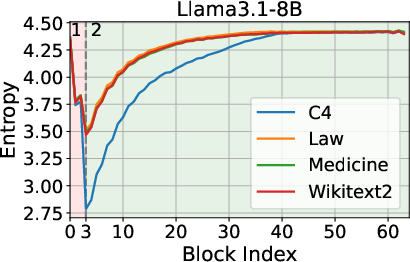
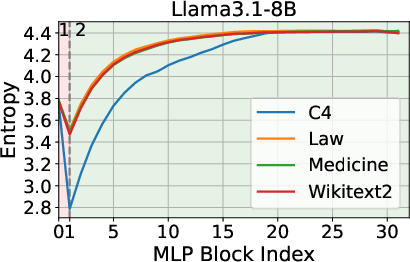
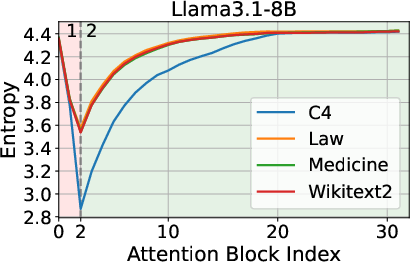
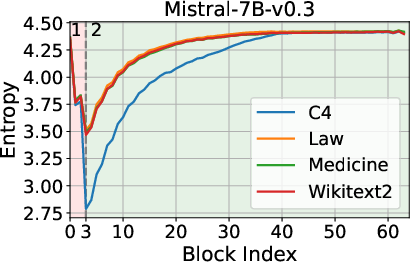
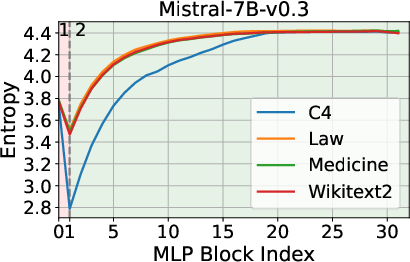
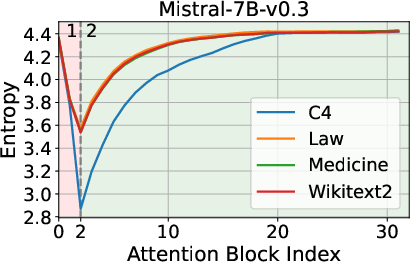
Figure 1: Entropy Dynamics among Layers during Inference.
These observations inform the strategic pruning of layers, leveraging entropy as a more telling criterion than geometric alignment metrics like cosine similarity.
EntroDrop Framework
EntroDrop adopts a two-stage pruning framework. During the initial entropy decrease stage, no blocks are pruned. The focus shifts during the entropy increase stage, where blocks with minimal entropy gain are pruned.
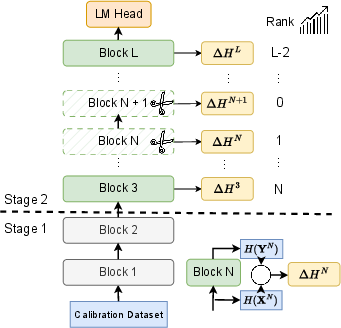
Figure 2: Overview of the EntroDrop framework. Stage 1 keeps intact, while Stage 2 exhibits increasing entropy. Blocks in Stage 2 are ranked based on their entropy increase, and those with the lowest increase are pruned.
This entropy-based approach enables more strategic pruning by targeting blocks that contribute less to the overall information capacity of the model, thus preserving core functionalities while reducing resource requirements.
Experimental Evaluation
Comprehensive experiments demonstrate EntroDrop's ability to maintain accuracy while achieving significant reductions in model size. The studies involve multiple entropy estimation methods: Bucket, KNN, and Renyi. Bucket-based and KNN estimations are especially effective in maintaining model performance, unlike Renyi, which introduces performance degradation.
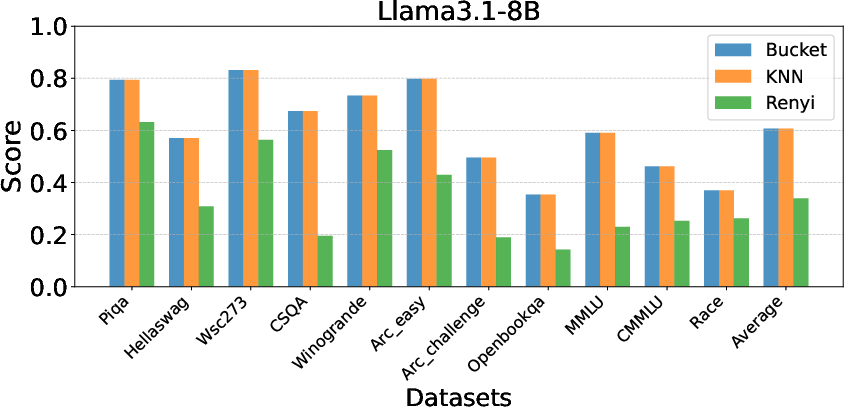
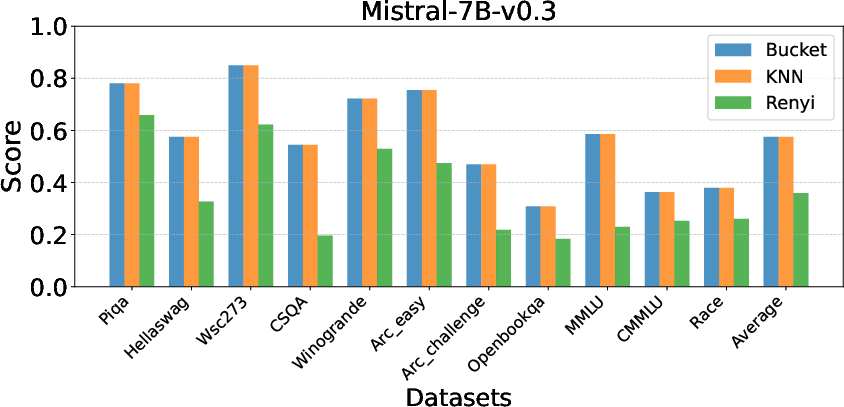
Figure 3: Impact of Entropy Estimate Methods.
The experiments show a consistent pattern of redundancy, particularly in attention layers, validating the potential of structured pruning methodologies.
Considerations and Results
Robustness across Calibration Datasets: EntroDrop exhibits consistent performance across various datasets, indicating its flexible applicability in different contexts.
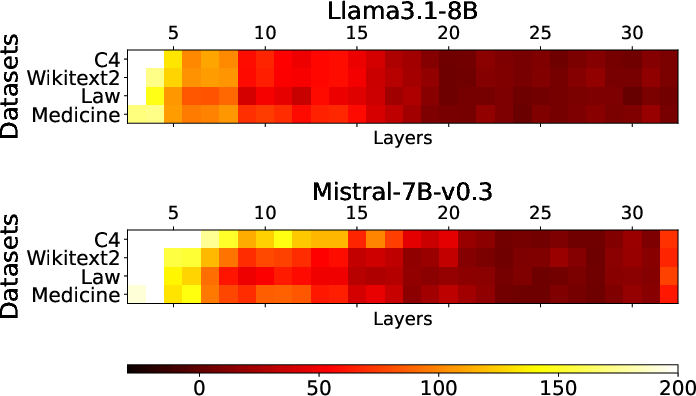
Figure 4: Heatmap of Calibration Datasets.
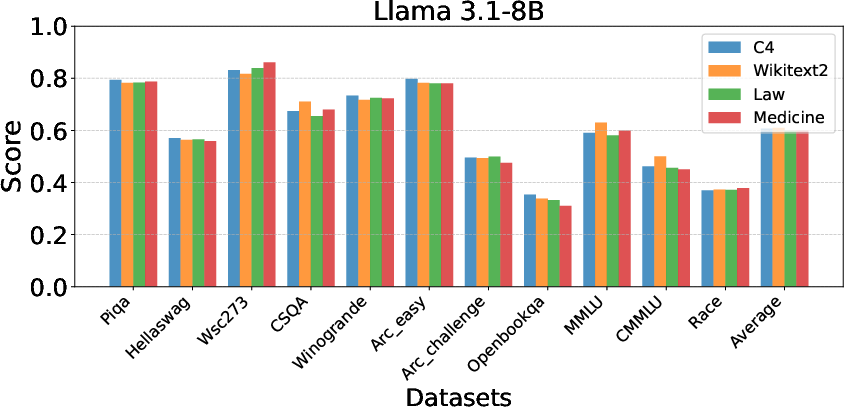
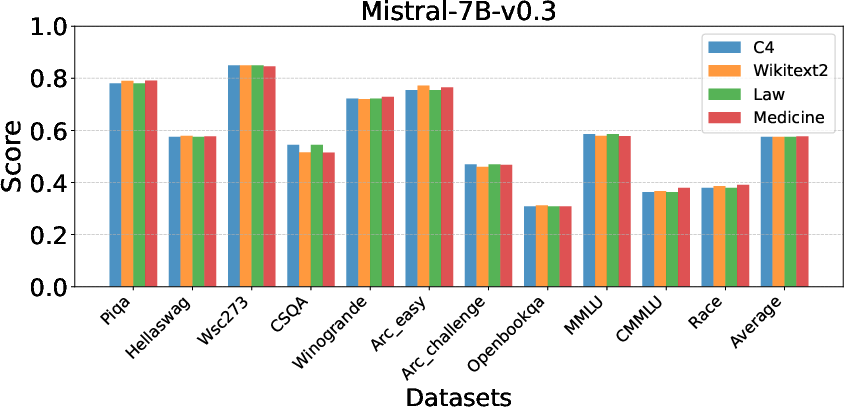
Figure 5: Impact of Calibration Datasets.
Speedup Metrics: The pruning significantly boosts inference speed, with the initial stages of pruning contributing to the most drastic reductions in computational time.
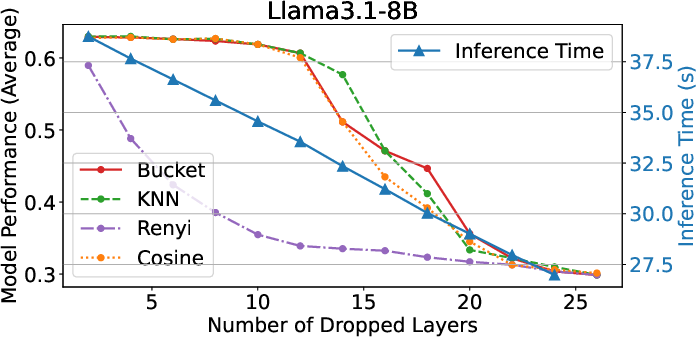
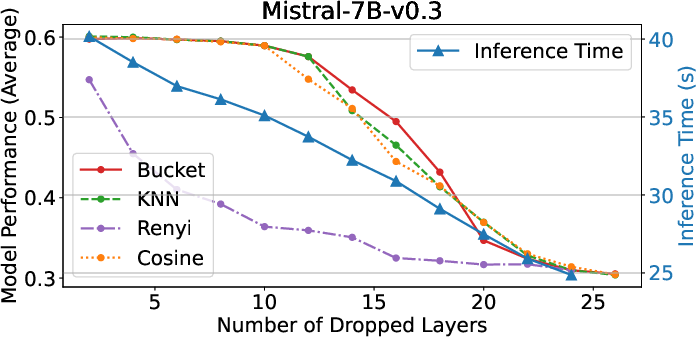
Figure 6: SpeedUp Experiments.
These results suggest that EntroDrop not only aids in resource-efficient deployment but also ensures that performance remains largely unaffected by calibration datasets.
Conclusion
This paper underscores the efficacy of EntroDrop, emphasizing its ability to leverage entropy to prune redundant blocks within LLMs effectively. Unlike traditional metrics, entropy provides a nuanced understanding of information distribution across layers, offering a reliable basis for pruning decisions. The method demonstrates substantial improvements in computational efficiency without compromising accuracy, highlighting its practicality for real-world applications of LLMs. Future explorations might focus on refining entropy estimation techniques and extending applicability to domain-specific applications.

