- The paper introduces Tiled Flash Linear Attention to significantly improve linear RNN efficiency via chunk-based sequence parallelism.
- The methodology applies optimized kernel computations and a sigmoid gating mechanism in mLSTM to reduce execution time and memory usage.
- Benchmark results demonstrate state-of-the-art performance in runtime and memory trade-offs for long-context sequence modeling.
Tiled Flash Linear Attention: More Efficient Linear RNN and xLSTM Kernels
Introduction
The development of efficient neural network architectures continues to be a critical area of research, particularly with the exponential increase in model size and the demand for longer context sequences. Tiled Flash Linear Attention (TFLA) is a novel approach designed to enhance the efficiency of linear RNNs, offering significant improvements over traditional Transformer architectures by leveraging linear compute scaling in sequence length. While Flash Attention provides highly optimized self-attention mechanisms, TFLA introduces an additional sequence parallelization level within each chunk, allowing for more scalable and memory-efficient computation.
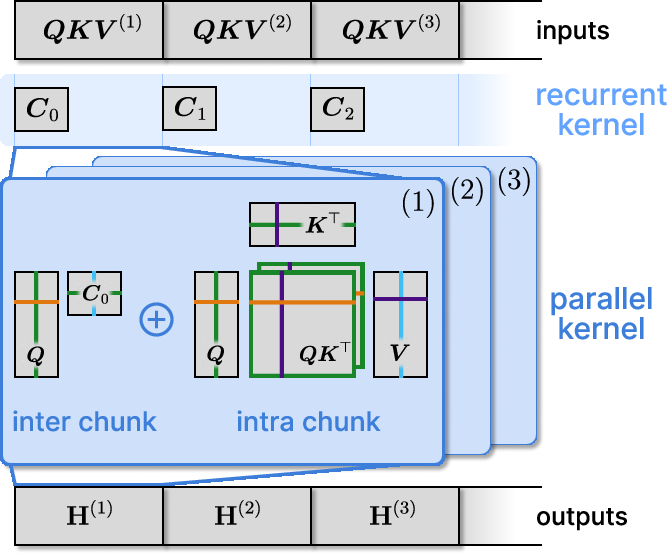
Figure 1: Tiled Flash Linear Attention (TFLA) consists of a recurrent kernel and a parallel kernel, which process the input sequence in chunks $\BQ \BK \BV ^{(k)}$.
Kernel Design and Implementation
TFLA integrates multiple levels of sequence parallelism by chunking input sequences and tiling matrix computations within chunks. This design enables efficient hardware utilization, reducing the dependency on GPU memory by limiting state materialization, a problem prevalent in earlier linear RNN kernel implementations.
One of the innovations of TFLA is its application to the xLSTM architecture, specifically the mLSTM variant. The architecture supports larger chunk sizes than traditional Flash Linear Attention (FLA), addressing the limitations imposed by GPU SRAM constraints. The recurrence within each chunk allows TFLA to balance computation and memory, achieving near-optimal runtime performance through kernel parallelism.
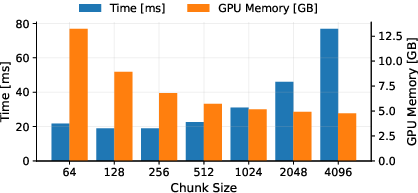
Figure 2: Memory vs. Runtime Trade-off of TFLA Forward-Backward Pass. We show the mLSTMsig for embedding dimension 4096 (8 heads with head dim 512), sequence length 8192, and batch size 8. By varying the chunk size parameter, our TFLA kernels can effectively balance memory vs. runtime.
Recognizing the computational inefficiencies in the mLSTM with exponential input gates, TFLA introduces an mLSTM variant with sigmoid input gates. This amendment simplifies the computation by minimizing the necessity of additional states for gating functions, specifically eliminating the need for the max state, thus reducing execution time and complexity without compromising model performance. The sigmoid input gate allows for faster computations while maintaining competitive performance against models with more complex gating mechanisms.

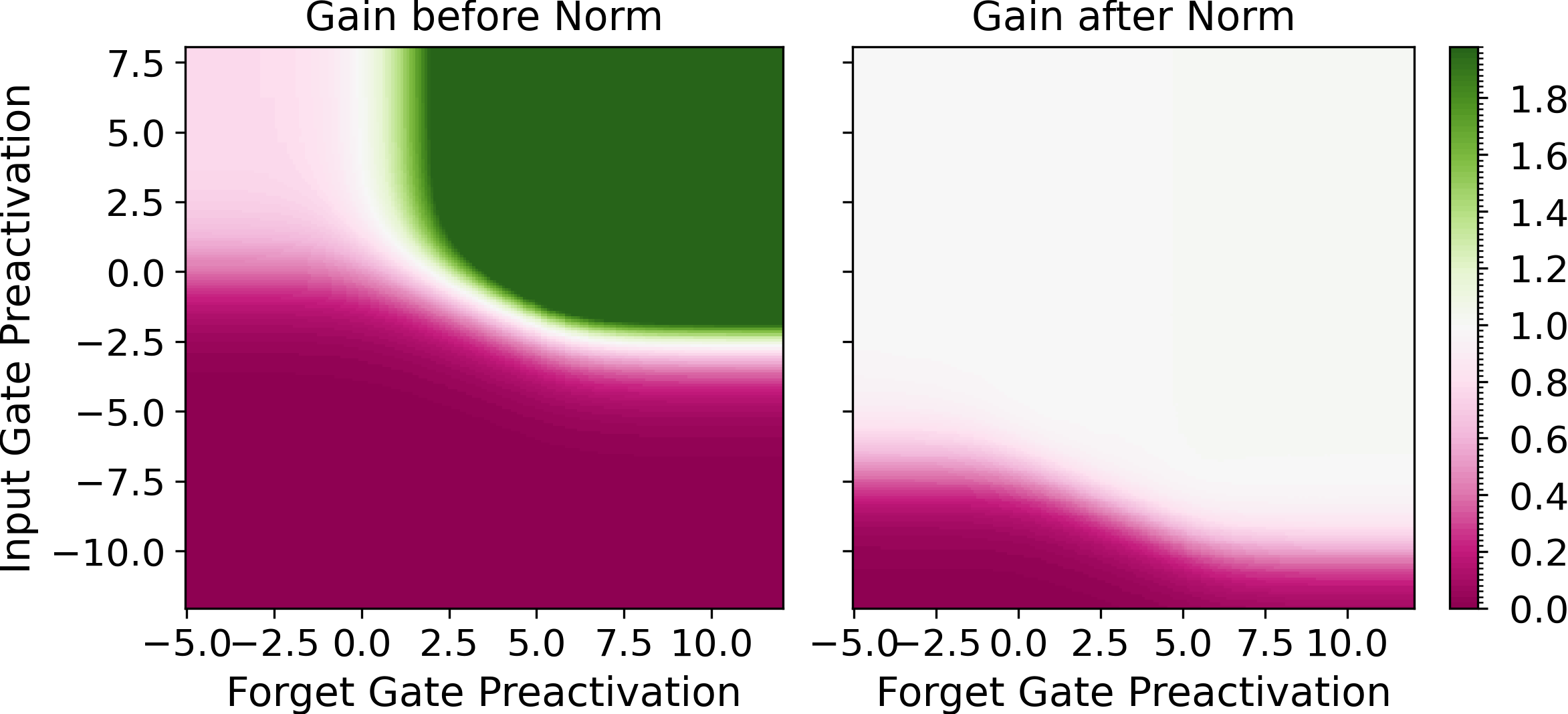
Figure 3: Transfer behavior of the mLSTM before and after the RMS-norm layer (epsilon=1e-6) for different input and forget gate values. The color shows the gain of the mLSTM defined, indicating consistent behavior across gate variants.
Results and Benchmarking
Empirical evaluations confirm that TFLA-based mLSTM kernels outperform existing attention and linear attention implementations across various runtime and memory usage benchmarks. The flexibility of chunk size configuration alongside robust kernel implementations secures a new state-of-the-art for efficient long-context sequence modeling.
Extensive testing reveals mLSTMsig's equivalence in performance to traditional methods, at scales up to 1.4 billion parameters, validating the removal of unnecessary complexity in gating mechanisms. Additionally, grid searches over norm layer parameters and input gate biases highlight the interplay between learning dynamics and architecture settings, crucial for optimizing model training stability.
Conclusion
TFLA offers significant advancements in sequence modeling efficiency, particularly for linear RNNs and xLSTM architectures like the mLSTM. By introducing strategic sequence parallelism and optimizing gating mechanics, TFLA facilitates the deployment of large models on modern computing architectures while maintaining a balance between runtime and memory requirements.
Future work may explore further optimizations leveraging recent hardware advancements, including asynchronous memory operations and advanced tiling strategies, presenting an exciting platform for developing more efficient and scalable neural network models.

