- The paper introduces Diffuse-CLoC, a guided diffusion framework that integrates state-action modeling to generate realistic, steerable character motions.
- It employs a transformer-based diffusion architecture with specialized attention mechanisms to overcome limitations of previous kinematic methods.
- Experimental results demonstrate improved performance in tasks like dynamic obstacle avoidance and navigation without requiring retraining.
"Diffuse-CLoC: Guided Diffusion for Physics-based Character Look-ahead Control"
The paper introduces Diffuse-CLoC, a guided diffusion framework specifically designed for physics-based character control. This model excels in creating realistic, steerable motions by modeling the joint distribution of states and actions, overcoming the steerability and physical realism limitations of previous kinematics and diffusion policy approaches.
Motivation and Approach
The paper aims to address the shortcomings of kinematic motion diffusion models in generating physically feasible motions and the restricted adaptability of diffusion-based control policies for unseen tasks. Diffuse-CLoC effectively merges these paradigms by using a diffusion model that conditions action generation on predicted states, thus maintaining the physical realism of actions while providing intuitive steerability.
Diffuse-CLoC employs a transformer-based diffusion architecture with a specialized attention mechanism—non-causal for states and causal for actions. This design allows dynamic obstacle avoidance and task-space control without requiring a high-level planner. The system can handle a wide variety of tasks, such as static and dynamic obstacle avoidance, motion in-betweening, and more, using a single pretrained model.
Technical Implementation
Diffuse-CLoC's architecture is depicted in (Figure 1). It utilizes a decoder-only transformer, denoising a trajectory represented through separate state and action tokens. The model achieves superior performance by employing a tailored attention mask that distinguishes between states’ and actions’ attention scopes.
Attention and Rolling Scheme
The attention strategy plays a critical role. Actions use causal attention, focusing on past states to mitigate the influence of artifacts in future states, while states can attend to future states (Figure 2). The rolling inference scheme enhances consistency, assigning noise based on timestep proximity, thus improving real-time responsiveness and reducing computation by reusing information in a FIFO manner.
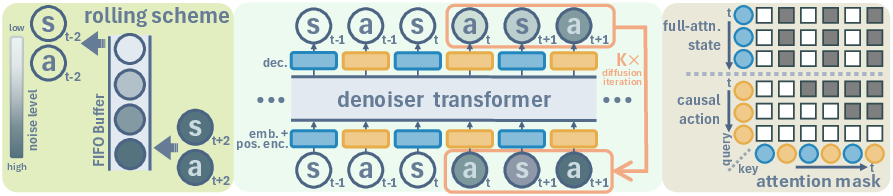
Figure 1: Framework of Diffuse-CLoC, highlighting its architecture, attention mechanism, and rolling buffer implementation.
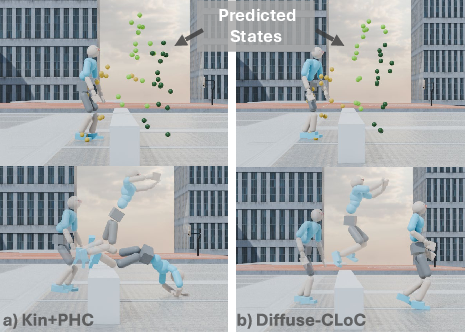
Figure 3: Rollouts in jump task: Kin+PHC (Left) faces artifacts; Diffuse-CLoC (Right) completes agile motions robustly.
Experimental Results
Experiments demonstrate Diffuse-CLoC's superiority in various tasks compared to traditional methods like Kin+PHC. On the "jump" task, Diffuse-CLoC achieves a significantly higher success rate due to its integrated state-action modeling, allowing it to respond effectively even with perturbed kinematic inputs.
In the "forest" task, longer state prediction horizons improve navigation success, as they allow for effective trajectory planning (Figure 4).
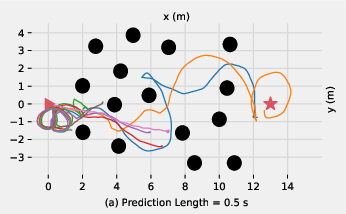
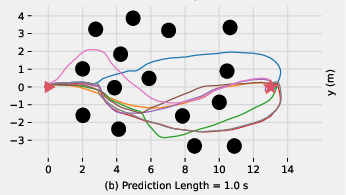
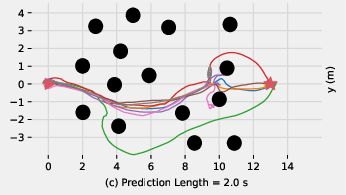
Figure 4: Trajectories in the forest task: Short horizons cause repetitive patterns; long horizons ensure diverse, successful navigation.
Application Scenarios
Diffuse-CLoC's practical applications include static and dynamic obstacle avoidance, optimizing for route path guidance through classifier inference, and seamless motion in-betweening without extra retraining requirements.

Figure 5: Downstream task rollouts demonstrating Diffuse-CLoC's planning, steering, and motion synthesis capabilities.
Conclusion
Diffuse-CLoC presents a substantial advancement in physics-based control by merging the adaptability of kinematic generation with the realism of action diffusion. The unified approach enables a broad array of tasks without retraining, fostering innovations in virtual environments and robotics.
Future research could explore data coverage to enhance model robustness and alternative attention formulations to address bias towards previously seen motion patterns. Opportunities also exist to extend this framework into object interaction domains, offering rich avenues for exploration in AI-driven animation and control systems.