LDP: A Local Diffusion Planner for Efficient Robot Navigation and Collision Avoidance
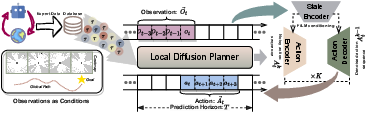
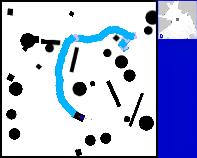
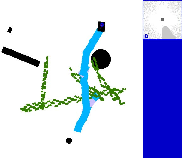
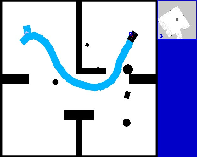
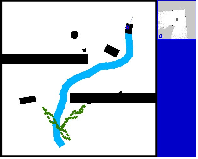
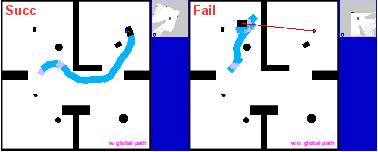
Abstract: The conditional diffusion model has been demonstrated as an efficient tool for learning robot policies, owing to its advancement to accurately model the conditional distribution of policies. The intricate nature of real-world scenarios, characterized by dynamic obstacles and maze-like structures, underscores the complexity of robot local navigation decision-making as a conditional distribution problem. Nevertheless, leveraging the diffusion model for robot local navigation is not trivial and encounters several under-explored challenges: (1) Data Urgency. The complex conditional distribution in local navigation needs training data to include diverse policy in diverse real-world scenarios; (2) Myopic Observation. Due to the diversity of the perception scenarios, diffusion decisions based on the local perspective of robots may prove suboptimal for completing the entire task, as they often lack foresight. In certain scenarios requiring detours, the robot may become trapped. To address these issues, our approach begins with an exploration of a diverse data generation mechanism that encompasses multiple agents exhibiting distinct preferences through target selection informed by integrated global-local insights. Then, based on this diverse training data, a diffusion agent is obtained, capable of excellent collision avoidance in diverse scenarios. Subsequently, we augment our Local Diffusion Planner, also known as LDP by incorporating global observations in a lightweight manner. This enhancement broadens the observational scope of LDP, effectively mitigating the risk of becoming ensnared in local optima and promoting more robust navigational decisions.
- X. Xiao, B. Liu, G. Warnell, and P. Stone, “Motion planning and control for mobile robot navigation using machine learning: A survey,” Autonomous Robots, 2022.
- Z. J. Cui, Y. Wang, N. M. M. Shafiullah, and L. Pinto, “From play to policy: Conditional behavior generation from uncurated robot data,” arXiv preprint arXiv:2210.10047, 2022.
- C. Chi, S. Feng, Y. Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” arXiv preprint arXiv:2303.04137, 2023.
- M. Wang and J. N. Liu, “Fuzzy logic-based real-time robot navigation in unknown environment with dead ends,” RAS, 2008.
- W. Yu, J. Peng, Q. Qiu, H. Wang, L. Zhang, and J. Ji, “Pathrl: An end-to-end path generation method for collision avoidance via deep reinforcement learning,” arXiv preprint arXiv:2310.13295, 2023.
- J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in NIPS, 2020.
- J. Peng, Y. Chen, Y. Duan, Y. Zhang, J. Ji, and Y. Zhang, “Towards an online rrt-based path planning algorithm for ackermann-steering vehicles,” in IEEE ICRA, 2021.
- K. Kurzer, “Path planning in unstructured environments: A real-time hybrid a* implementation for fast and deterministic path generation for the kth research concept vehicle,” Master’s thesis, 2016.
- D. Harabor and A. Grastien, “Online graph pruning for pathfinding on grid maps,” in AAAI, 2011.
- L. E. Kavraki, P. Svestka, J.-C. Latombe, and M. H. Overmars, “Probabilistic roadmaps for path planning in high-dimensional configuration spaces,” IEEE TRO, 1996.
- S. M. LaValle, J. J. Kuffner, B. Donald, et al., “Rapidly-exploring random trees: Progress and prospects,” Algorithmic and computational robotics: new directions, 2001.
- C. Rösmann, W. Feiten, T. Wösch, F. Hoffmann, and T. Bertram, “Trajectory modification considering dynamic constraints of autonomous robots,” in ROBOTIK, 2012.
- S. Yao, G. Chen, Q. Qiu, J. Ma, X. Chen, and J. Ji, “Crowd-aware robot navigation for pedestrians with multiple collision avoidance strategies via map-based deep reinforcement learning,” in IEEE/RSJ IROS, 2021.
- Q. Qiu, S. Yao, J. Wang, J. Ma, G. Chen, and J. Ji, “Learning to socially navigate in pedestrian-rich environments with interaction capacity,” arXiv preprint arXiv:2203.16154, 2022.
- C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song, “Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots,” in arXiv, 2024.
- D. A. Pomerleau, “Alvinn: An autonomous land vehicle in a neural network,” Advances in NIPS, 1988.
- G. You, X. Chu, Y. Duan, J. Peng, J. Ji, Y. Zhang, and Y. Zhang, “P 3 o: Transferring visual representations for reinforcement learning via prompting,” in IEEE ICME, 2023.
- B. et al., “End to end learning for self-driving cars,” arXiv:1604.07316 [cs], 2016.
- Y. Du and I. Mordatch, “Implicit generation and generalization in energy-based models,” arXiv preprint arXiv:1903.08689, 2019.
- J. Carvalho, A. T. Le, M. Baierl, D. Koert, and J. Peters, “Motion planning diffusion: Learning and planning of robot motions with diffusion models,” in IEEE/RSJ IROS, 2023.
- A. Sridhar, D. Shah, C. Glossop, and S. Levine, “Nomad: Goal masked diffusion policies for navigation and exploration,” arXiv preprint arXiv:2310.07896, 2023.
- M. Janner, Y. Du, J. B. Tenenbaum, and S. Levine, “Planning with diffusion for flexible behavior synthesis,” arXiv preprint arXiv:2205.09991, 2022.
- Z. Zhu, H. Zhao, H. He, Y. Zhong, S. Zhang, Y. Yu, and W. Zhang, “Diffusion models for reinforcement learning: A survey,” arXiv preprint arXiv:2311.01223, 2023.
- H. He, C. Bai, K. Xu, Z. Yang, W. Zhang, D. Wang, B. Zhao, and X. Li, “Diffusion model is an effective planner and data synthesizer for multi-task reinforcement learning,” Advances in NIPS, 2024.
- J. Ho and T. Salimans, “Classifier-free diffusion guidance,” arXiv preprint arXiv:2207.12598, 2022.
- A. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, and M. Chen, “Glide: Towards photorealistic image generation and editing with text-guided diffusion models,” arXiv preprint arXiv:2112.10741, 2021.
- A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y. Zhu, and R. Martín-Martín, “What matters in learning from offline human demonstrations for robot manipulation,” arXiv preprint arXiv:2108.03298, 2021.
- P. Florence, C. Lynch, A. Zeng, O. A. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mordatch, and J. Tompson, “Implicit behavioral cloning,” in CoRL. PMLR, 2022.
- L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch, “Decision transformer: Reinforcement learning via sequence modeling,” Advances in NIPS, 2021.
- N. Yokoyama, S. Ha, and D. Batra, “Success weighted by completion time: A dynamics-aware evaluation criteria for embodied navigation,” in IEEE/RSJ IROS, 2021.
- X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,” arXiv preprint arXiv:2209.03003, 2022.
- Y. Song, P. Dhariwal, M. Chen, and I. Sutskever, “Consistency models,” 2023.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

