- The paper establishes that multi-turn feedback—combining compilation, execution, and verbal cues—is crucial for realistic code generation evaluation.
- It demonstrates that weaker LLMs can rival state-of-the-art performance through iterative refinement with expert-level feedback.
- The study reveals a trade-off between rapid solution generation (MRR) and overall task completion (Recall), informing model selection based on specific deployment needs.
Benchmarking Conversational Code Generation with ConvCodeWorld
Introduction
The ConvCodeWorld benchmark represents a systematic advance in evaluating interactive code generation using LLMs. Traditional code generation evaluation protocols primarily target single-turn performance and fail to reflect the diversity and complexity of real-world human-AI code development. ConvCodeWorld addresses this gap through a comprehensive, reproducible experimental environment that enables controlled yet realistic experimentation over the feedback channel—considering compilation, execution, and critical verbal modalities, both at novice and expert levels. Complementing this, ConvCodeBench offers a static and cost-effective alternative for scalable, high-fidelity benchmarking, validated by extremely high rank correlations (0.82–0.99) with ConvCodeWorld.
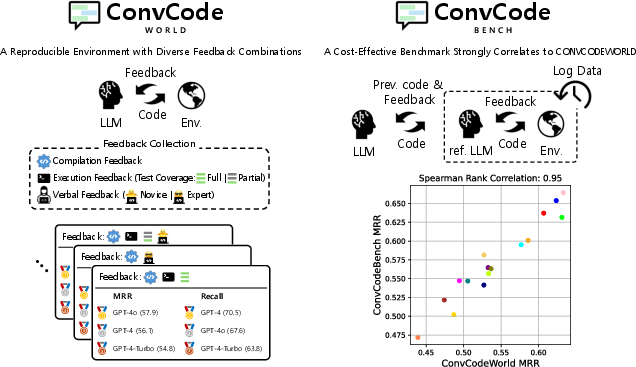
Figure 1: ConvCodeWorld and ConvCodeBench: dynamic and static benchmark frameworks enabling scalable, feedback-diverse code generation evaluation.
Feedback Combinatorics: Simulation of Real-world Pair Programming
ConvCodeWorld formalizes interactive code generation as a sequence of (problem, solution, feedback) tuples, iterated over at most 10 turns. Each step incorporates feedback in three orthogonal axes:
- Compilation Feedback (fc): Syntax/type error diagnostics from the compiler, offering minimal and always-available guidance.
- Execution Feedback: Either partial (fe) or full (f∗) test coverage. The test suite's coverage is carefully controlled for branch comprehensiveness, isolating test generalization versus test utilization ability.
- Verbal Feedback (fv): Synthesized using a powerful LLM (GPT-4o), with differentiation between novice (potentially noisy and paraphrastic) and expert (targeted, reference-based analysis) modalities.
Combining these axes, ConvCodeWorld spans 9 distinct feedback settings, each corresponding to a plausible real-world scenario (e.g., novice feedback only, full test cases with expert coaching, etc.), allowing targeted model dissection and robustness stress-testing.
ConvCodeBench: Efficient and Reproducible Static Benchmark
Dynamic LLM-in-the-loop benchmarks incur significant monetary and latency costs, especially at scale or under closed API constraints. ConvCodeBench mitigates these by leveraging pre-generated feedback logs with a fixed reference model (CodeLlama-7B-Instruct), covering all settings where LLM participation is non-trivial (i.e., those involving verbal feedback). Extensive experiments demonstrate that rankings and metric differentials (MRR, Recall) on ConvCodeBench closely track those of ConvCodeWorld, validating its use as a reliable and efficient proxy, with Spearman’s ρ routinely in the 0.9–0.99 range.
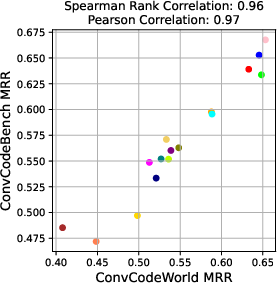

Figure 2: Correlation between MRR on ConvCodeBench and ConvCodeWorld across feedback settings—demonstrating high-fidelity proxy behavior.
Experimental Protocol and Metrics
The authors employ an extensive experimental grid:
- Models: 21 open- and closed-source LLMs, including GPT-4o, Llama-3.1-70B, DeepSeek-Coder-V2, ReflectionCoder-DS, and R1-Distill models.
- Dataset: An extended version of BigCodeBench-Full-Instruct (1,140 Python tasks, high branch/test coverage).
- Evaluation: Core focus on Pass@1 at each turn, with overall assessment via Mean Reciprocal Rank (MRR, efficiency of problem completion in fewer turns) and Recall (task completion rate within 10 turns). These two metrics provide insight into both the model’s proficiency per attempt and total coverage across diverse benchmarks.
Key Results
Impact of Feedback Diversity
Model performance is highly sensitive to the specific feedback scenario. Ranking order among LLMs varies significantly depending on the available signals (compilation, execution, verbal). This heterogeneity directly challenges the validity of single-turn or single-feedback-point evaluations.
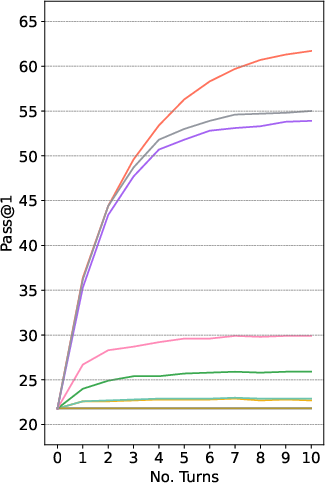
Figure 3: Iterative Pass@1 of multiple LLMs on ConvCodeWorld, for various feedback combinations.
Exploiting Feedback: Weaker LLMs Surpass SOTA with Sufficient Feedback
A critical empirical claim is that relatively weak LLMs (e.g., DeepSeek-Coder-6.7B, CodeQwen1.5-7B) can achieve or even exceed the single-turn performance of state-of-the-art LLMs (GPT-4o, GPT-4-Turbo) via multi-turn refinement, provided they have access to rich, high-quality feedback (in particular, expert-level verbal feedback in addition to test feedback).
Generalization Limits
Specialization to a single feedback regime during fine-tuning harms adaptability to new ones. The ReflectionCoder-DS family, explicitly optimized for a single feedback setting, fails to generalize as effectively when evaluated outside of its training scenario. This suggests that coverage of feedback axes during training is critical for robust model deployment in the wild.
MRR-Recall Tradeoff
The study finds a notable MRR-Recall trade-off: LLMs able to complete tasks rapidly (high MRR) are not always those that maximize the number of tasks solved overall (high Recall), and vice versa. Model selection should thus be feedback-regime and downstream-deployment-objective aware.

Figure 4: LLM-specific iterative Pass@1 trajectories, highlighting model-specific feedback utilization characteristics.
Cost and Reproducibility
ConvCodeWorld can scale benchmarking efficiently: LLM-simulated feedback (via strong expert LLMs) costs approximately 1.5% of equivalent human annotation while maintaining high reproducibility and systematization. ConvCodeBench further reduces costs by eliminating dynamic LLM rollout, yet maintains robust rank fidelity with the dynamic benchmark.
Implications and Future Outlook
The paradigm established by ConvCodeWorld makes several clear contributions:
- Benchmark Design: Demonstrates that a high-fidelity code generation benchmark must account for the combinatorics of feedback, especially verbal feedback from simulated users of varying expertise.
- Model Development Guidance: Encourages future code LLMs to be robust not just to program synthesis but to the full diversity of feedback channels encountered in real developer environments, likely incentivizing multitask/few-shot and feedback-adaptive model designs.
- Evaluation Protocols: ConvCodeBench's static architecture points to a future where benchmarks can efficiently scale to hundreds of models or RL policy rollouts without cost prohibitions or API bottlenecks.
- Limitations and Future Directions: Feedback “utility curves” and model adaptability to out-of-domain feedback types remain open research problems. Further, as LLMs increasingly serve as both code generators and feedback providers, co-evolutionary approaches and adversarial benchmarks (e.g., noisy/hallucinated or malicious verbal feedback) could reveal model limitations and align with real-world robustness objectives.
Conclusion
ConvCodeWorld and ConvCodeBench collectively advance the methodological rigor with which multi-turn, feedback-driven conversational code generation is evaluated. The diversity and granularity of feedback supported by this benchmark enable robust and nuanced model comparison, reflecting requirements for real-world deployment. High correlation between the static and dynamic benchmarks indicates that practical, cost-effective large-scale evaluation is within reach, even for the broader research community. This framework sets a new standard for multi-turn code generation evaluation, and calls for future models explicitly adapted to feedback-heterogeneous scenarios.