- The paper proposes a novel contrastive learning approach to adapt multimodal embeddings efficiently without full model fine-tuning.
- The methodology trains a compact, task-specific nonlinear projection on frozen embeddings using both single and per-modality paradigms, reducing computational overhead.
- Experimental results show up to a 20% increase in test F1 scores in clinical applications, highlighting its practicality for resource-limited environments.
Efficient Domain Adaptation of Multimodal Embeddings using Contrastive Learning
Introduction
The paper entitled "Efficient Domain Adaptation of Multimodal Embeddings using Contrastive Learning" (2502.02048) addresses an essential problem in deploying machine learning models in resource-constrained environments such as healthcare. In these settings, the adoption of machine learning techniques has faced challenges due to the limited computational resources available on-site, which restricts the ability to perform task-specific adaptation or fine-tuning of foundational models. This paper proposes a novel approach to adapt multimodal embeddings without the need for extensive computational resources, thus bridging a critical gap between high-performance ML models and their accessibility in such environments.
Methodology
The proposed approach utilizes contrastive learning to adapt foundational embeddings from LLMs and Vision Models. The method involves training a small, task-specific nonlinear projection on top of frozen embeddings, thereby avoiding the need to fine-tune entire foundational models. This contrastive learning technique effectively maps embeddings into a lower-dimensional space, aligning embeddings with similar labels while differentiating those with different labels.
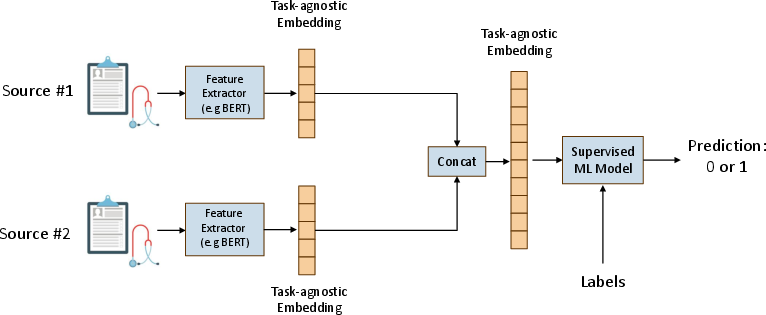
Figure 1: Multimodal prediction with task-agnostic embeddings.
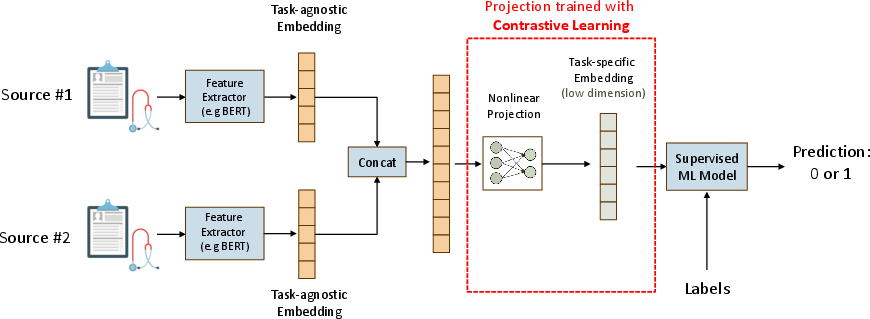
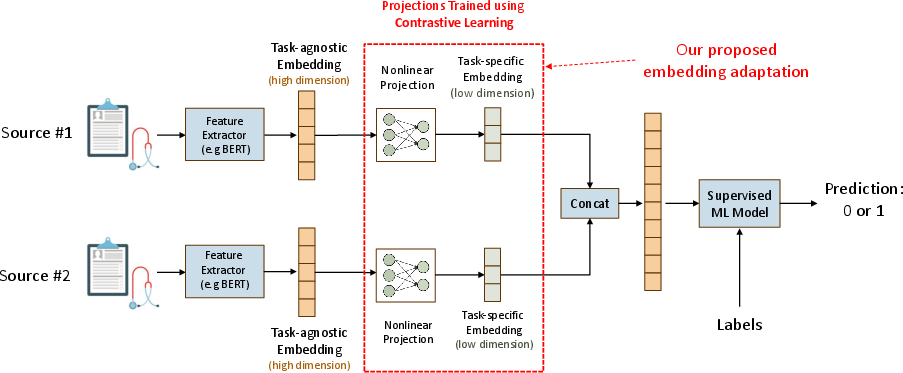
Figure 2: Single Projection.
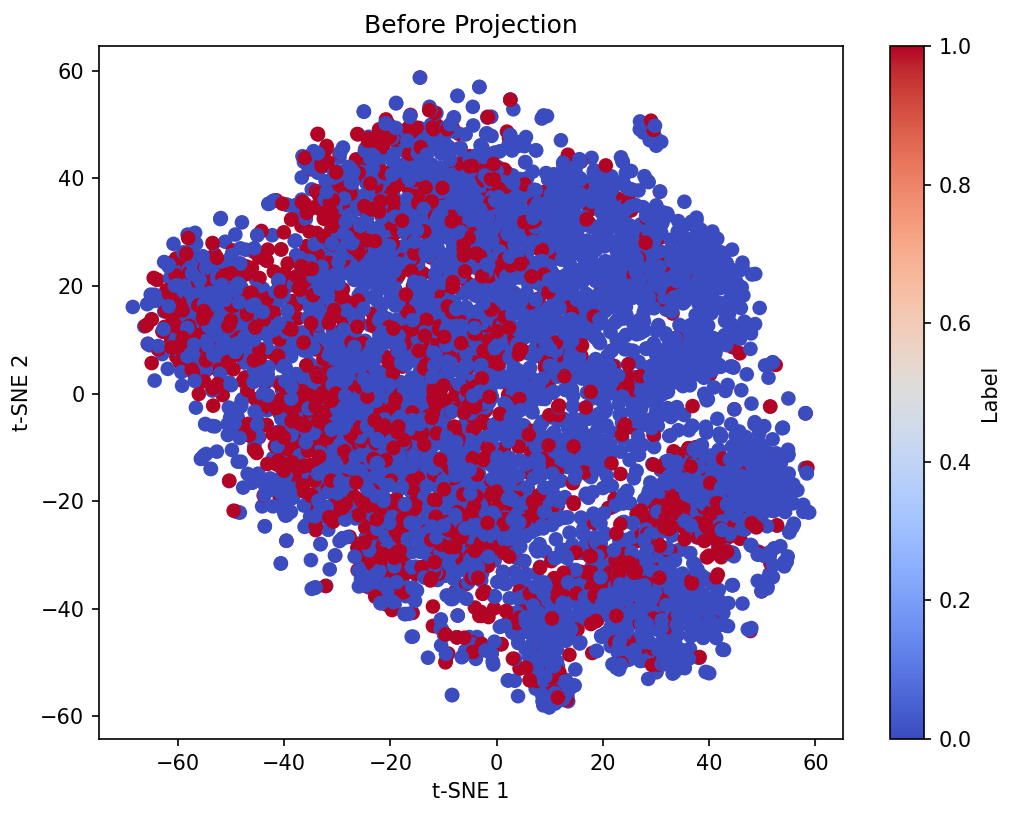
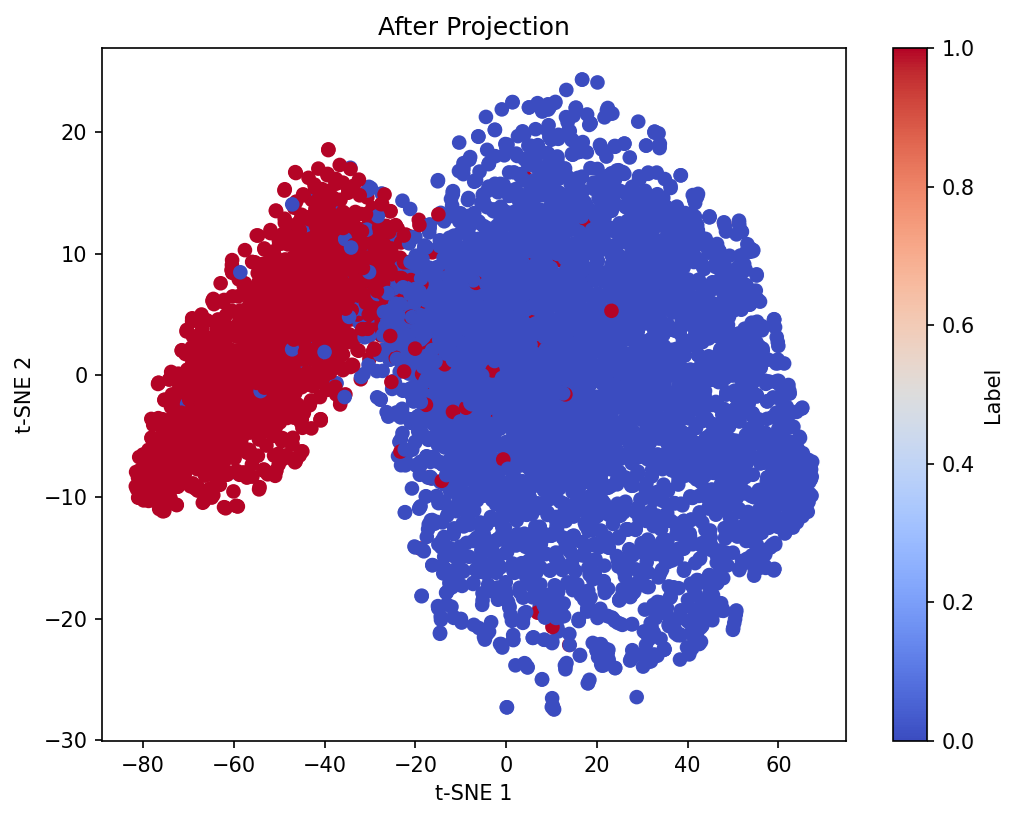
Figure 3: Original embedding.
The methodology is particularly beneficial in healthcare settings where computational resources are scarce, but high accuracy and reliability are imperative. The approach involves two paradigms: Single Projection, where concatenated embeddings are processed through a single projection function, and Per-modality Projection, where each modality is projected separately, then concatenated.
Experimental Results
The paper reports significant improvements in performance across various downstream tasks, notably demonstrating increases in test F1 scores of up to 20% in clinical applications. The experiments conducted on real-world clinical notes underscore the practicality of the method, showing that advanced ML models can be effectively utilized in environments with limited computational resources. Furthermore, the approach is shown to be modality-agnostic, facilitating the integration of additional modalities seamlessly.
Through extensive experiments, the paper illustrates the efficacy of contrastive learning in improving embedding quality without the previously necessary computational overhead associated with full model fine-tuning.
Implications and Future Directions
The research presented has profound implications for the deployment of machine learning models in low-resource settings. By significantly reducing the computational demands of task-specific adaptation, this method opens up opportunities for wider adoption of ML technologies in critical real-world applications such as healthcare diagnosis and treatment planning. The paper lays the groundwork for future research to explore enhancements in projection techniques and the potential integration of even more diverse modalities.
In terms of future developments, further exploration into optimizing projection sizes and investigating the potential for applying this approach in other domains outside healthcare could yield exciting advancements. The adaptability and efficiency demonstrated by the proposed methodology suggest that it could be extended to other resource-constrained environments which require high-performance ML systems.
Conclusion
This paper provides a viable solution to a longstanding problem in machine learning deployment, namely adapting foundational, multimodal embeddings to specific tasks in resource-constrained environments. By leveraging contrastive learning, the authors present a method that markedly improves performance outcomes with minimal computational overhead, thus ensuring that powerful ML tools can be accessible and effective even where resources are limited. This work positions the research community favorably for future explorations into efficient domain adaptation strategies in machine learning.