- The paper demonstrates that a hybrid training approach, combining gradient descent and CMA-ES, significantly reduces forecasting errors in quantum recurrent neural networks.
- CMA-ES outperforms standard gradient descent by effectively escaping local minima and handling non-convex landscapes, despite higher computational costs.
- Experimental results on real-world chaotic datasets show up to a 10x reduction in forecast error when using a hybrid method over conventional optimization.
Evolutionary Algorithms for Training Quantum Recurrent Neural Networks in Time-Series Forecasting
Introduction
This work addresses the optimization challenges in variational quantum algorithms (VQAs), specifically for time-series forecasting tasks using quantum recurrent neural networks (QRNNs). The core contribution is a comparative analysis of gradient-based optimization (Adam), evolutionary optimization (CMA-ES), and their hybridization for training the parameters of QRNNs on diverse real-world datasets. The study is motivated by the prevalence of barren plateaus and local minima in the VQA training landscape, where standard gradient-descent methods frequently underperform. The focus is on benchmarking evolutionary strategies for their capacity to escape local minima and provide superior forecast accuracy.
Model Architecture and Quantum Circuit Ansatz
The QRNN employed in the experiments closely mimics the architecture of a classical RNN, featuring three input/output (I/O) qubits for encoding the input at timestep t and three memory (M) qubits for capturing sequence history. Angle encoding is used for the data, with x<t> loaded into the I/O qubits via RY rotations. Memory transfer and recurrent computation are mediated by a parameterized circuit (ansatz) with 24 variational parameters and cyclic entangling gates between I/O and M qubits.
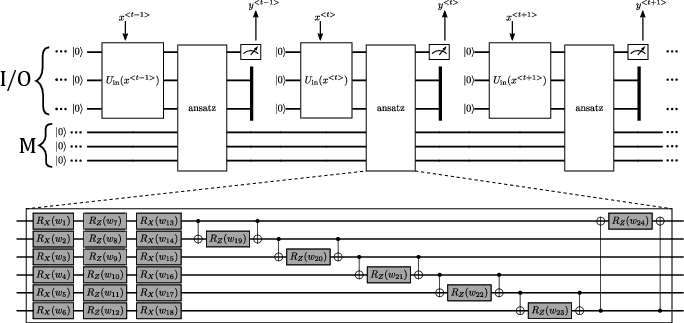
Figure 1: The quantum recurrent neural network (QRNN) architecture utilized for time-series learning, showing data encoding, recurrent block structure, and parameterization based on [Li2023].
The architecture is chosen to isolate the impact of classical optimization strategies on the quantum model's training dynamics rather than to compare different quantum circuit ansatzes.
Optimization Strategies: Gradient Descent, Evolutionary Algorithms, and Hybridization
Three training protocols are benchmarked:
- Gradient Descent (GD): The Adam optimizer is used with a fixed learning rate, following standard practices in both classical and quantum machine learning.
- Covariance Matrix Adaptation Evolution Strategy (CMA-ES): This global search method samples from a multivariate normal distribution, updating the mean and covariance based on fitness rankings of parameter sets evaluated on the quantum circuit.
- Hybrid Approach: Training is initialized with Adam until loss plateaus, then switched to CMA-ES. The intent is to leverage the speed and efficiency of GD for local search, using evolutionary algorithms to explore and escape suboptimal basins in the loss landscape.
Experimental Design
The evaluation comprises four univariate time-series datasets, each with chaotic or nonlinear dynamics:
- Gold-price dataset (financial data)
- Santa Fe A laser time series (benchmark chaotic sequence)
- Mackey-Glass (chaotic system with delayed feedback)
- Delhi weather (meteorological data: daily air pressure)
Forecasts are performed for a prescribed number of timesteps (7, 1, 4, 9, respectively). For each experiment, the first 100 points of each dataset are split into training/testing, maintaining uniformity across protocols. Comparisons focus on the relative root mean square (RMS) prediction error, averaged over five runs.
Results and Analysis
The training curves for each approach across the four datasets reveal consistent patterns:
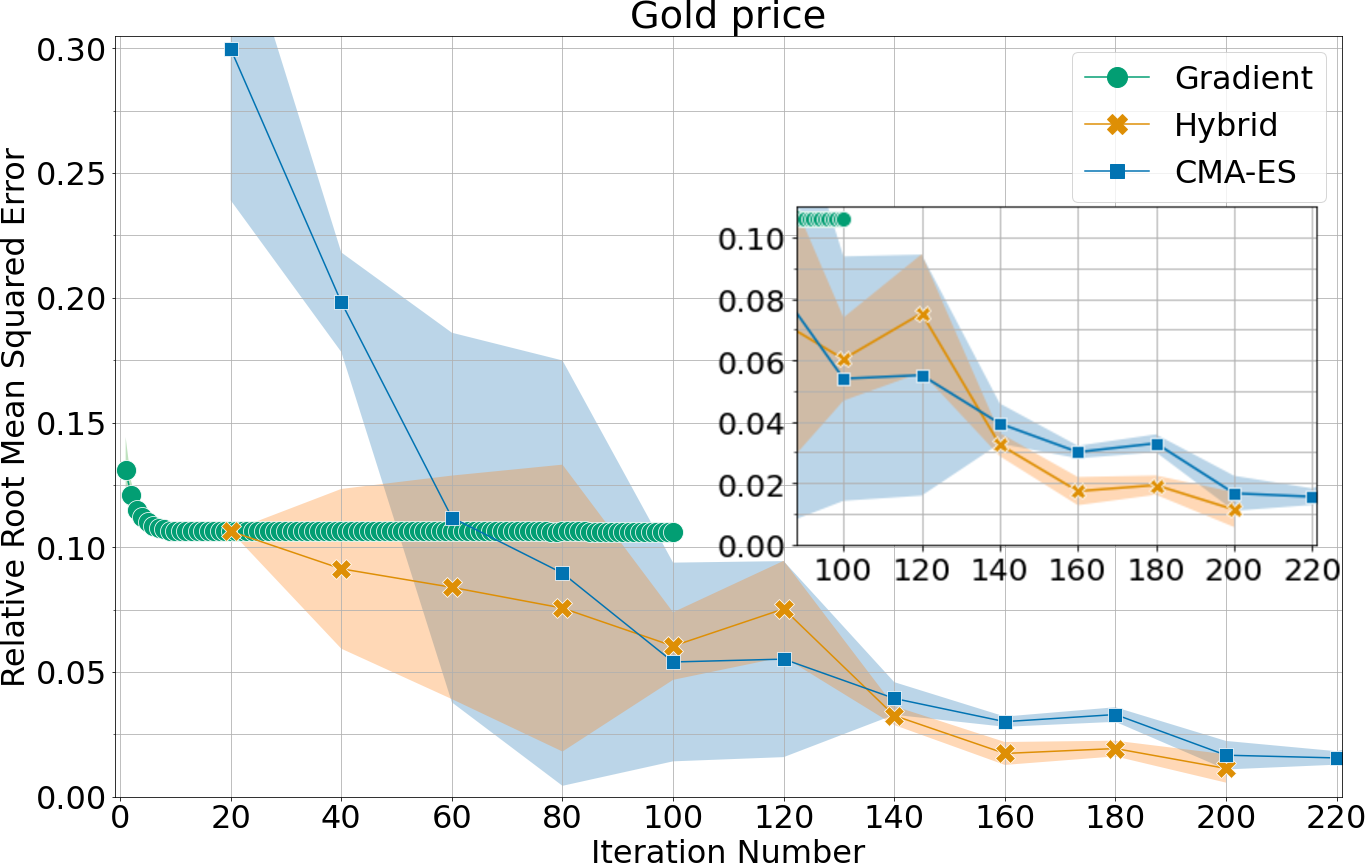
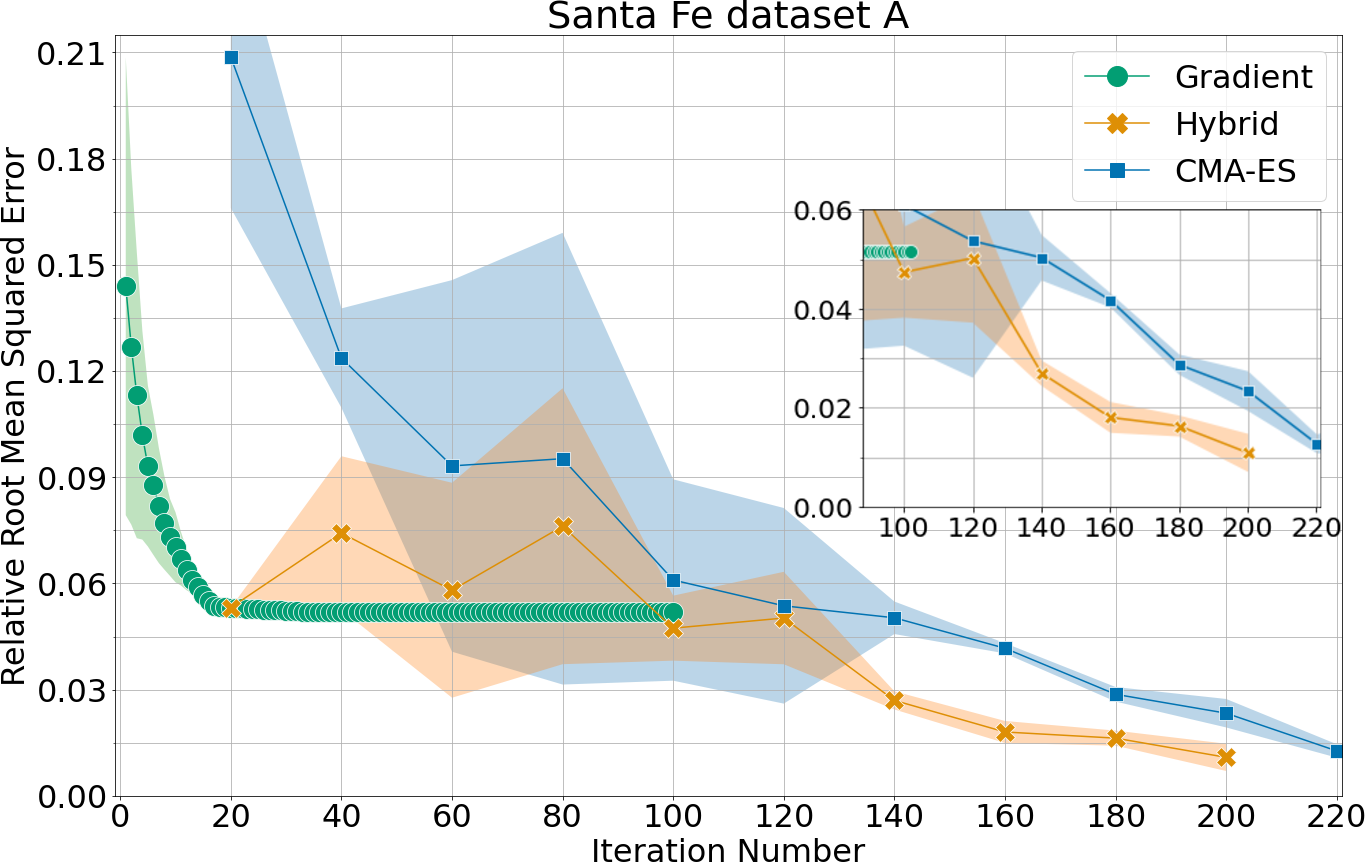
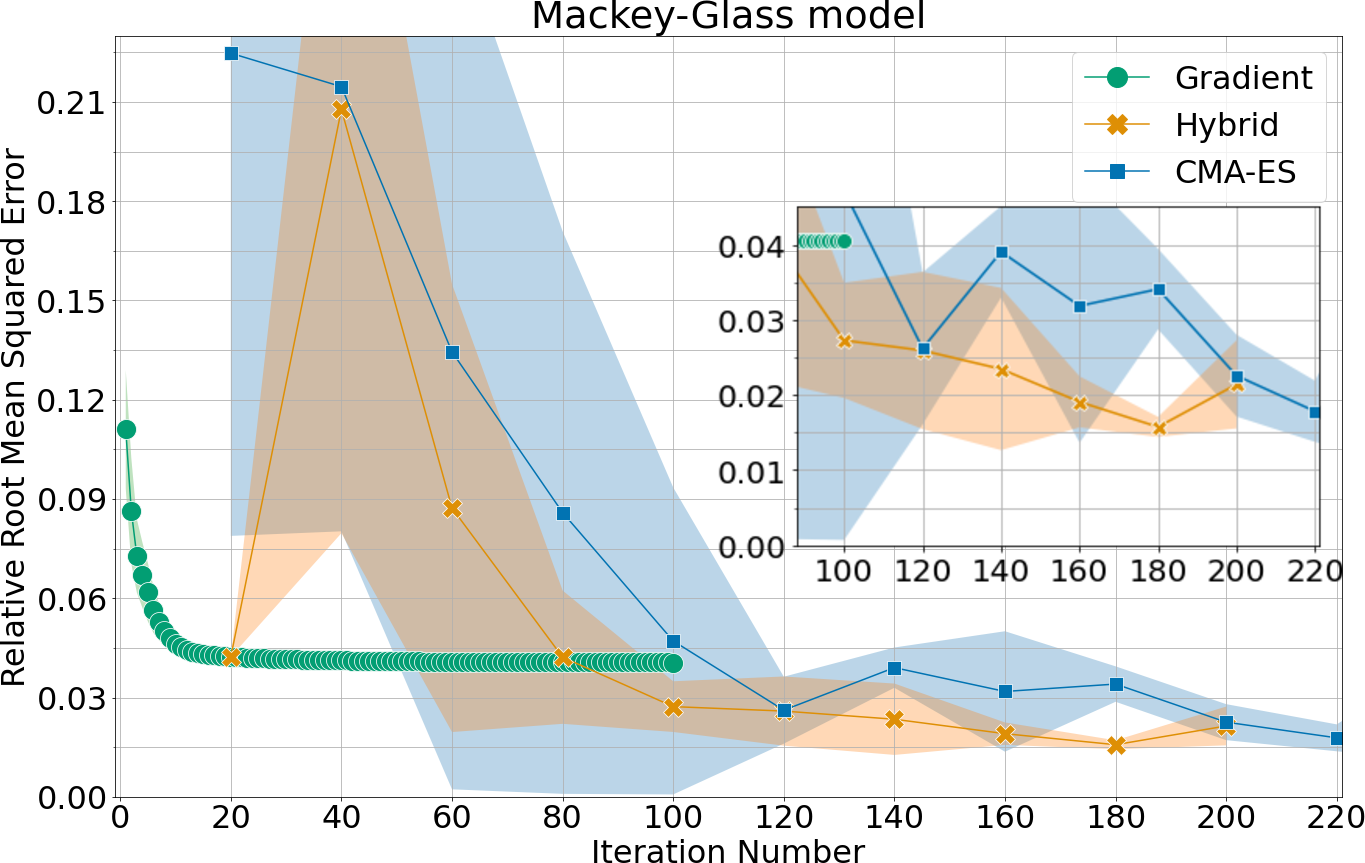
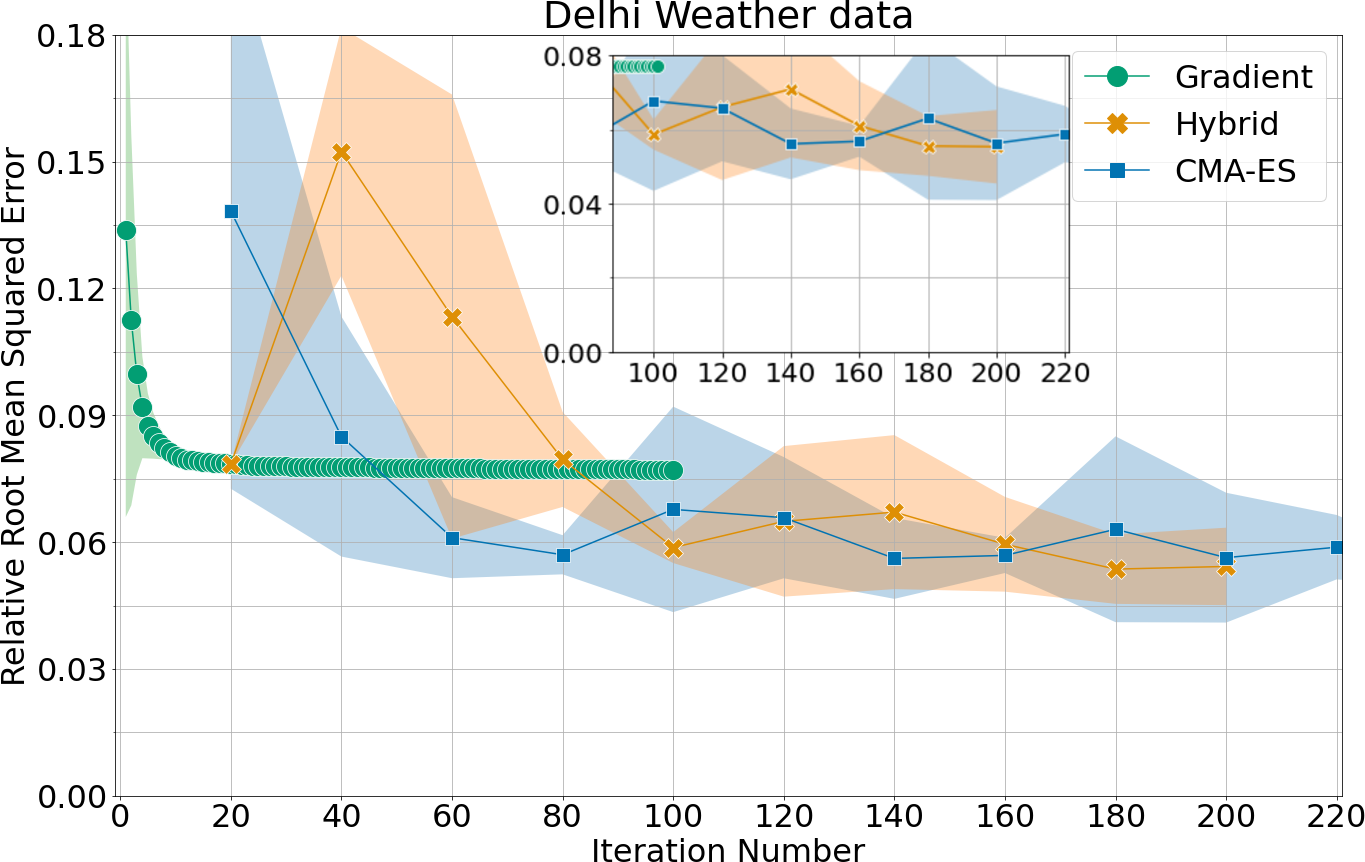
Figure 2: Forecast error (relative RMS) for four datasets across epochs, comparing GD (Adam), CMA-ES, and the hybrid method; CMA-ES epochs are plotted with delay reflecting increased per-epoch computational cost.
Key empirical findings:
- Gradient Descent is consistently observed to plateau at suboptimal error rates, indicative of entrapment in local minima.
- CMA-ES consistently finds lower-error solutions, reducing test errors by up to a factor of six compared to GD (e.g., gold-price and Santa Fe datasets).
- Hybrid training yields the most pronounced improvements, with error reductions approaching a factor of ten over gradient descent (on gold-price), while also requiring fewer evolutionary epochs to reach best performance.
The observed superiority of evolutionary strategies is most pronounced when the gradient-descent baseline has substantial room for improvement, i.e., when the forecast task difficulty exposes limitations of local search. On the Delhi weather dataset, however, both CMA-ES and GD converge to similar suboptimal solutions, suggesting nontrivial non-convexity or noise structure in the fitness landscape that is challenging even for global search methods.
Notably, the computational requirements of CMA-ES are significantly higher—each epoch of CMA-ES involves approximately 20x the computational expense of a GD epoch, due to population sampling and repeated circuit evaluation.
Theoretical and Practical Implications
This study underscores the vulnerability of VQA training to local minima and demonstrates that evolutionary strategies, such as CMA-ES, function effectively as global optimizers in the context of quantum neural time-series forecasting. The hybrid approach, integrating fast local descent with broader global search, emerges as the most powerful, both in terms of accuracy gains and training efficiency.
These findings imply that, particularly as practical QRNN deployments become feasible and larger-scale quantum hardware matures, optimization protocol selection will be critical in extracting performance benefits from VQAs. This work demonstrates that default reliance on gradient-based methods may leave substantial accuracy untapped, especially in noisy, highly non-convex loss landscapes.
From a theoretical standpoint, the results lend further support to the conceptual separation between VQA optimization and circuit design, highlighting the need for advanced, possibly hybrid, classical-quantum training pipelines. Moreover, the demonstrated hybridization opens avenues for more adaptive, meta-level strategies such as switching based on online loss metrics or applying population-based training across both circuit parameters and model architectures.
Future work could extend this paradigm by allowing not only parameter but also ansatz evolution, exploring discrete and continuous search spaces in tandem. In addition, transfer learning between classical and quantum models, exploiting evolutionary and local search heuristics, remains unexplored.
Conclusion
This paper provides compelling evidence that evolutionary optimization, particularly in hybrid with gradient-based methods, substantially improves the accuracy of quantum time-series forecasting networks relative to standard first-order optimization. These advances are directly relevant for NISQ-era and future fault-tolerant quantum machine learning applications where parameter landscapes are both high-dimensional and rife with local minima. Continued application and refinement of global optimization heuristics are expected to play a pivotal role in successful VQA deployment in time-sensitive, high-accuracy domains.
Reference:
"Quantum Time-Series Learning with Evolutionary Algorithms" (2412.17580).

