- The paper demonstrates that integrating variational quantum KANs with adversarial training yields superior sample efficiency and mitigates overfitting.
- It shows that GAVQKAN achieves lower mean-squared error and sliced Wasserstein distance in early training compared to classical GANs and QGANs.
- The architecture maintains a fixed parameter budget regardless of data resolution, proving robust across MNIST, CIFAR-10, and Fashion-MNIST benchmarks.
Generative Adversarial Variational Quantum Kolmogorov-Arnold Network: Architecture, Training Dynamics, and Comparative Evaluation
Introduction
The Generative Adversarial Variational Quantum Kolmogorov-Arnold Network (GAVQKAN) (2512.11014) constitutes an overview of Kolmogorov-Arnold Networks (KANs), variational quantum algorithms, and the adversarial paradigm from GANs, with a focus on generative modeling under quantum constraints. This approach leverages a variational quantum implementation of the KAN as a generator and combines Born machine sampling with adversarial feedback to realize datagen in the quantum domain. The core motivation is to achieve improved accuracy–data compression trade-offs versus classical neural networks (NNs) and quantum GANs (QGANs), particularly for small training sets, while maintaining the parameter efficiency of the KAN architecture within a quantum computational framework.
Model Architecture: Variational Quantum KANs in an Adversarial GAN Setting
GAVQKAN frames the generator as a variational quantum circuit inspired by the KAN architecture. The quantum generator processes patches of latent variables via a sequence of Ry rotations, parameterized by modified KAN-style gates, followed by C-Z entangling operations. Each quantum circuit outputs probability distributions over sizable vector representations, patched together to synthesize complete data instances (images). The generator is trained in the Born machine regime, directly sampling from the quantum output state as a generative distribution.
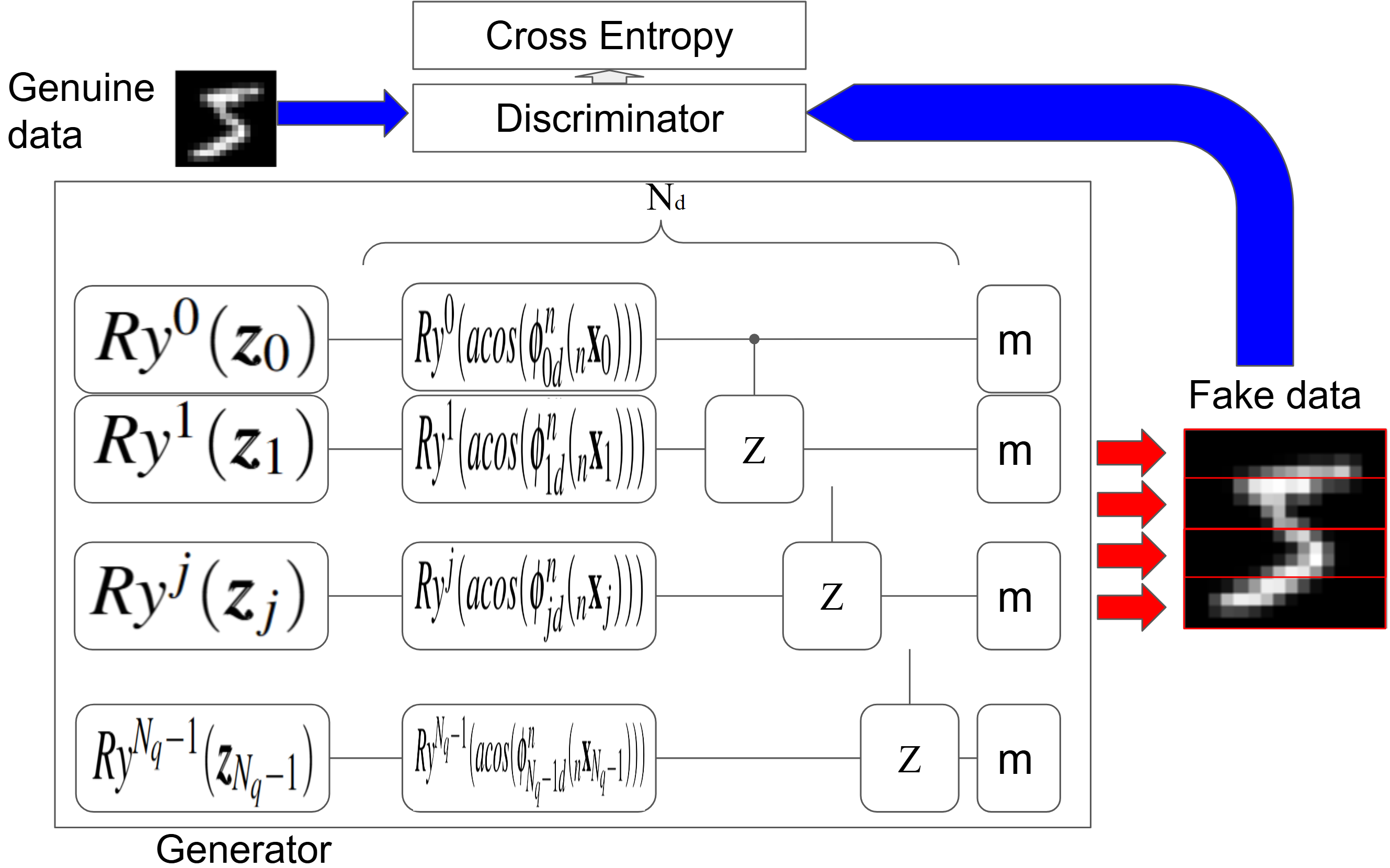
Figure 1: Schematic overview of GAVQKAN, showing qubit initialization, layerwise parameterization (Ry, C-Z gates), and patch-based quantum Born machine sampling as input to loss evaluation.
The adversarial optimization follows the standard GAN min-max formulation, with generator and discriminator losses formed by cross-entropy between real and generated data. The discriminator utilizes a classical CNN. Distinctively, the variational quantum KAN generator’s trainable parameters are not scaled with data resolution but instead exploit the quantum state’s exponential representational capacity for patch-wise aggregation.
Training Dynamics and Convergence Analysis
Extensive empirical evaluation is performed on MNIST (handwritten digits), CIFAR-10, and Fashion-MNIST benchmarks. The generator is implemented with Nq=8 qubits and a depth-1 layered ansatz, with B-spline parameterization for the KAN gates. Training utilizes stochastic gradient descent with learning rates decoupled across the generator and discriminator.
The comparative convergence behavior of GAVQKAN, QGAN, and classical CNN-GAN is reported using loss metrics, mean-squared error (MSE), and sliced Wasserstein distance (SWD). Key findings are:
- The GAVQKAN generator loss achieves a high value rapidly, but the discriminator converges more slowly relative to QGAN and CNN.
- In the initial 400 training steps, GAVQKAN produces lower SWD and MSE, particularly in low-data regimes.
- Beyond ∼400 steps, QGAN can achieve improved sample sharpness at greater computational cost, but GAVQKAN remains more statistically stable and consistent with less overfitting.
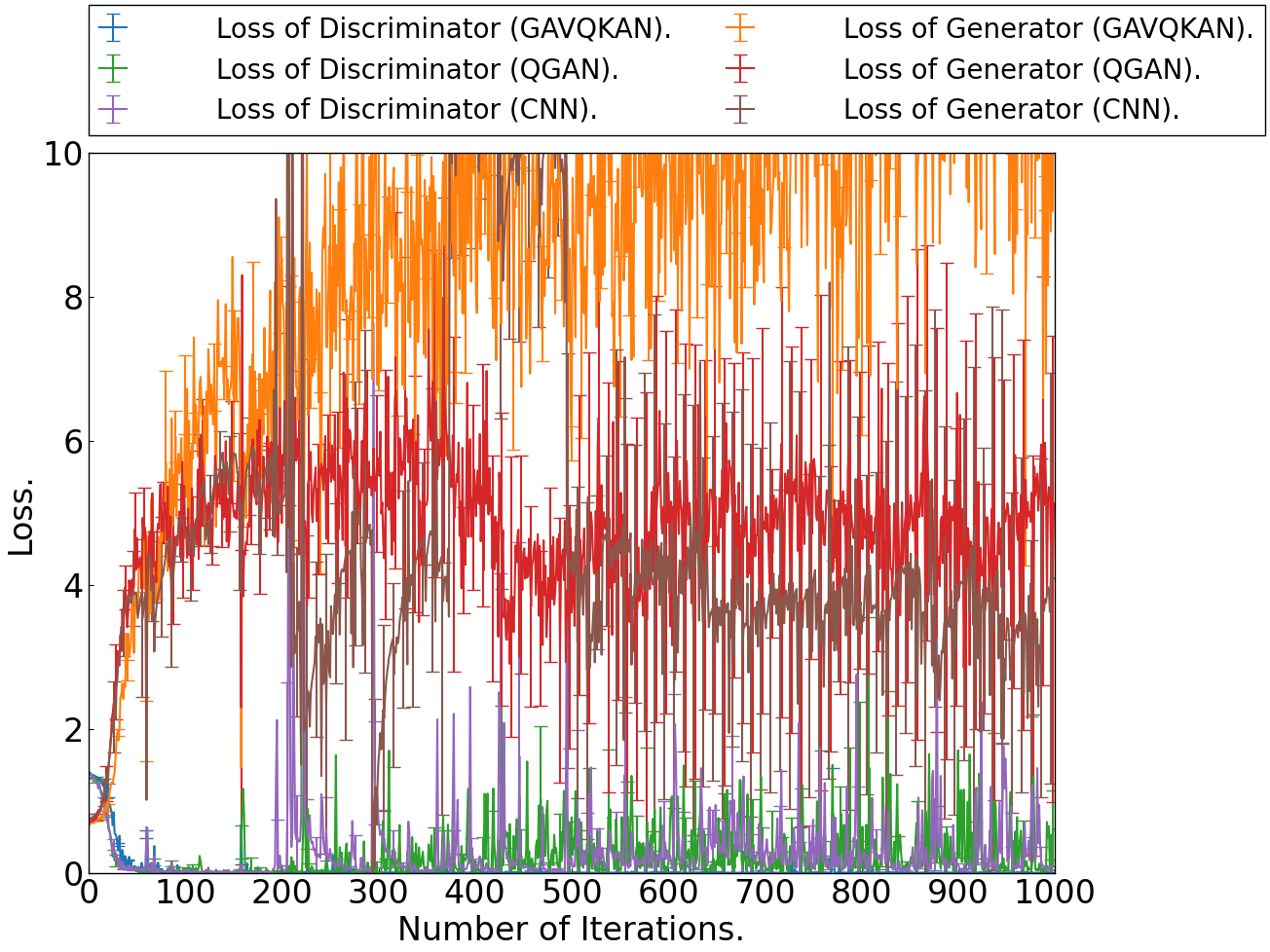
Figure 2: Generator and discriminator loss convergence across 10 runs for GAVQKAN, QGAN, and CNN on MNIST.
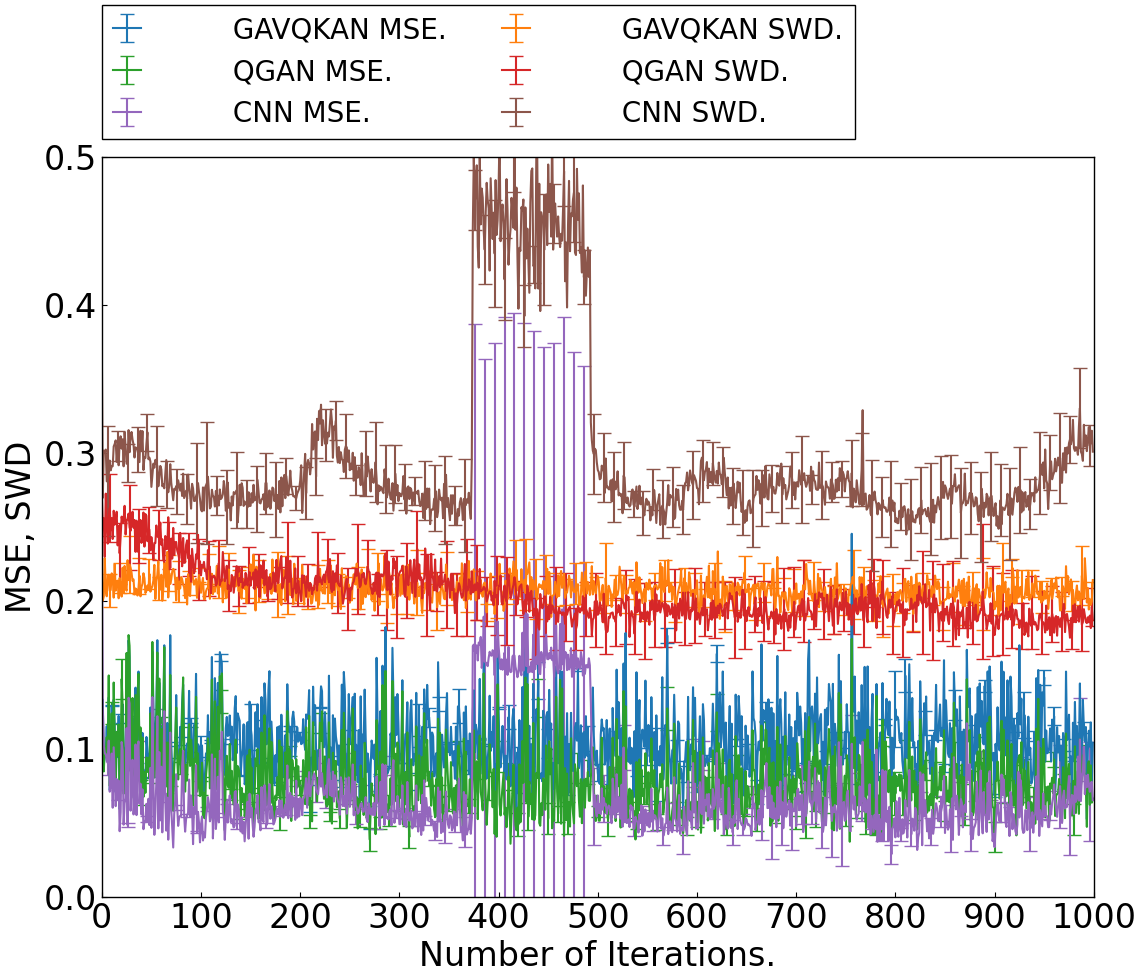
Figure 3: MSE and SWD evolution for GAVQKAN, QGAN, and CNN on the MNIST generation task.
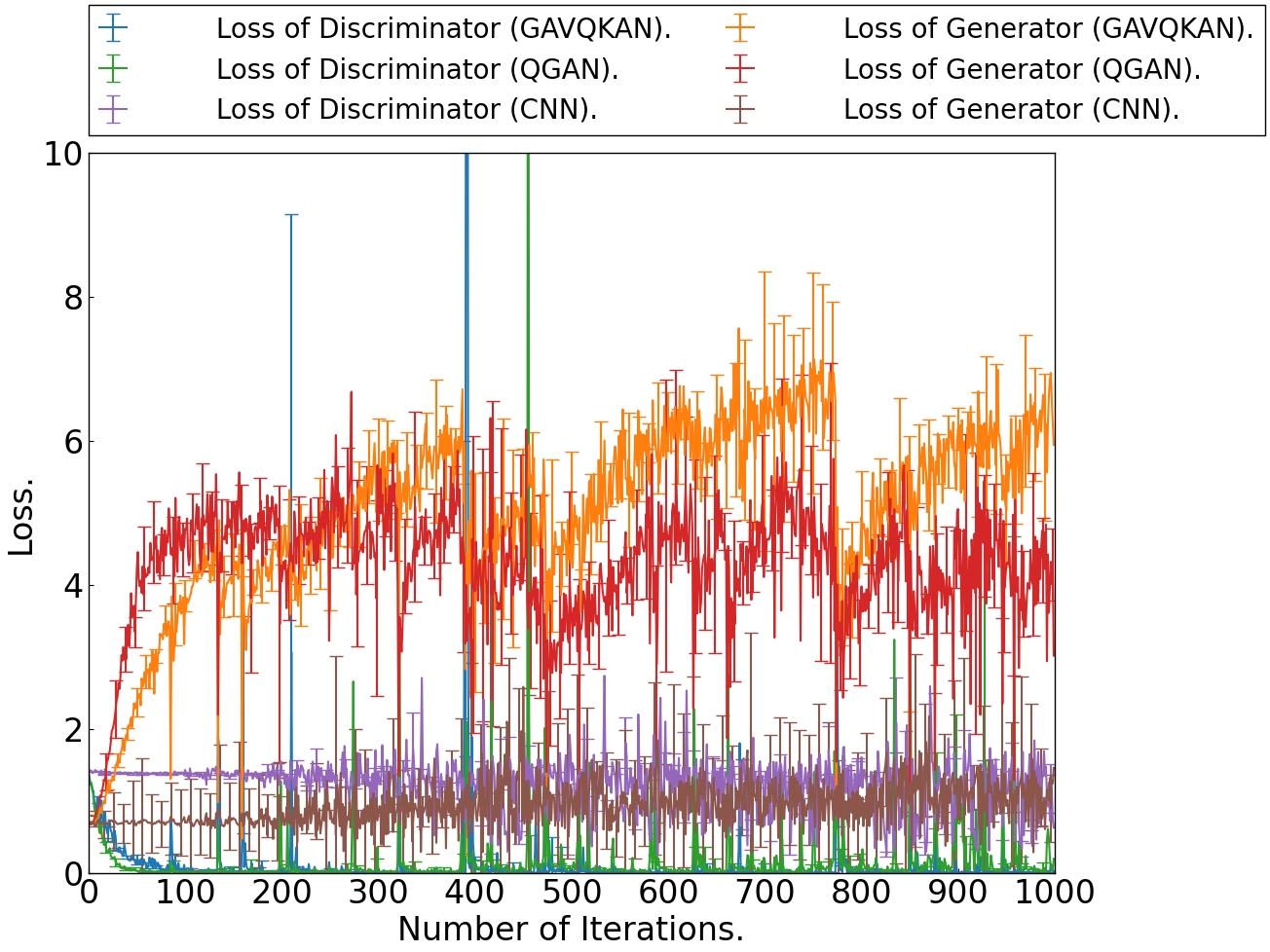
Figure 4: Discriminator/generator loss evolution for 5 attempts on the CIFAR10 dataset.
Output Quality and Statistical Assessment
Qualitative evaluation demonstrates that GAVQKAN can reproduce recognizable class samples from MNIST and CIFAR-10 with as few as 100 training iterations, with visual results competitive with or superior to QGANs in early training, and with much smaller network size than conventional GANs.

Figure 5: Qualitative comparison of digit synthesis by GAVQKAN, QGAN, and CNN as a function of training iteration.
The generator’s sample quality, as quantified by SWD, evidences superior statistical faithfulness to the data distribution in small-data, low-iteration contexts. Result robustness is further validated (on Fashion-MNIST) with statistical significance testing (Bonferroni tests on SWD across 16 seeds), evidencing stable generalization and moderate sensitivity to latent input variation.

Figure 6: CIFAR-10 sample outputs for GAVQKAN, QGAN, and CNN after training.
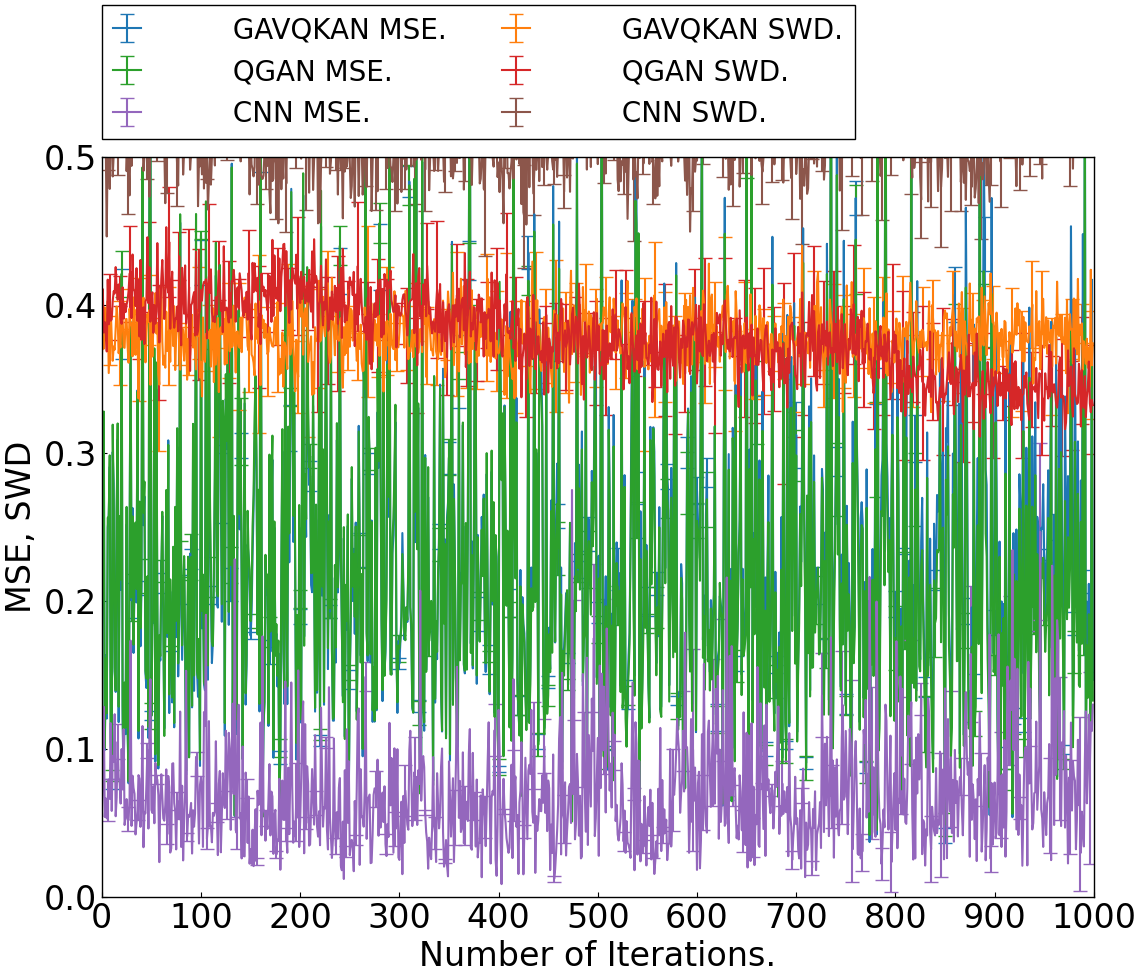
Figure 7: MSE/SWD for image synthesis tasks on CIFAR-10.
Model and Training Variants
The authors explore multiple ablations affecting ansatz selection, gate parameterization (B-spline vs. RBF), optimizer choice (SGD vs. Adam), and depth/qubit count. Rapid convergence can be achieved with canonical ansatz or radial-based functions, at the expense of slight drops in SWD. Increasing ansatz depth or width improves SWD toward or below that achieved by QGAN, highlighting the model’s configurability for accuracy-runtime tradeoff.
Notably, the principal computational bottleneck is calculation time per epoch, with GAVQKAN being 6–11× slower than QGAN/CNN for Nq=8, though parameter efficiency is markedly improved and overfitting is mitigated.
Discussion and Implications
The evidence points to substantial sample efficiency and parameter compression in quantum KAN-based generators: GAVQKAN exceeds QGAN and CNN when training data is limited, confirming the theoretical representational advantage of Kolmogorov–Arnold style architectures fused with quantum sampling. GAVQKAN’s robustness to seed and input perturbations, lower susceptibility to overfitting, and consistent convergence profile contribute to greater reliability in generative quantum modeling.
Nevertheless, overall per-iteration runtime remains a practical constraint, dictated by the complexity of quantum circuit simulation and the use of hybrid quantum-classical loop structures. The extension to real quantum hardware and scalability for more expressive ansatz remains an open area, as is the deployment of adaptive optimization methods (e.g., APA, AAGAN) to accelerate convergence. Accuracy improvement also hinges on circuit optimization and hyperparameter tuning, which is critical for moving toward practical quantum generative modeling.
Conclusion
The GAVQKAN framework establishes that variational quantum KANs embedded in adversarial training pipelines yield highly sample-efficient quantum generators, achieving statistical fidelity with small data and parameter budgets. This model advances the intersection of quantum machine learning and generative models, indicating the practicality of hybrid quantum-classical architectures for distribution learning under resource constraints. Future research must interrogate scaling with increased circuit complexity, adaptation to real quantum processing units, and integration with advanced GAN training techniques to fully realize the potential of quantum-accelerated generative modeling.