- The paper presents a unified framework where quantum agents, equipped with parameterized circuits, autonomously rediscover optimal quantum algorithms such as QFT and Grover’s search.
- It leverages modular, hardware-efficient circuit architectures and nearest-neighbor gate constraints to enable adaptive learning in complex quantum environments.
- Experimental results validate the approach by matching theoretical optima in fidelity and success rates across tasks including quantum coin flipping and nonlocal games.
Quantum Agents for Algorithmic Discovery
Introduction and Framework
The paper presents a unified agent-environment formalism for quantum algorithmic discovery, leveraging reinforcement learning (RL) with quantum agents whose policies are parameterized quantum circuits (PQCs). The framework generalizes both single-agent and multi-agent quantum tasks, supporting shared and private quantum registers, multi-round interactions, and episodic, measurement-defined rewards. Agents interact with quantum environments or other agents by applying learnable unitaries to their registers, with the environment preparing initial states and computing rewards based on measurement outcomes.

Figure 1: General framework for quantum environments involving two agents, A and B, with private and shared registers and episodic reward computation.
The agent policies are implemented as PQCs, constructed from hardware-efficient gates: single-qubit rotations and phase shifts (U(θ,ϕ)), matchgates (M(θ,ϕ1,ϕ2)), and controlled-RY rotations (CRY(θ)). The circuit architecture is modular, with layers for local rotations, entangling ladders, matchgate pyramids, and SWAP operations, all constrained to nearest-neighbor connectivity for hardware compatibility.
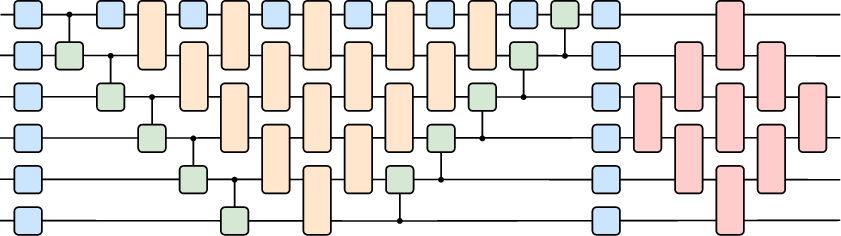
Figure 2: Example parameterized quantum circuit architecture for agent policies, balancing expressivity and hardware constraints.
Training proceeds via direct policy search, optimizing circuit parameters to maximize expected episodic rewards, with no access to target solutions or analytic gradients. The framework is agnostic to the choice of circuit architecture and scales naturally from classical simulators to quantum hardware as problem size increases.
Rediscovery of Quantum Algorithms
Agents were trained to discover efficient QFT circuits for n=4 and n=6 qubits, using only basis state inputs and fidelity-based rewards. The learned circuits achieved fidelity $0.999999$ for both cases, matching the optimal QFT implementation. Notably, only the enhanced matchgate pyramid layer contained non-zero parameters, indicating that the agent autonomously identified the minimal structure required for QFT under nearest-neighbor constraints.
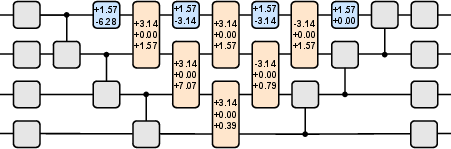
Figure 3: Learned QFT circuit for n=4; only the matchgate pyramid layer is non-trivial.
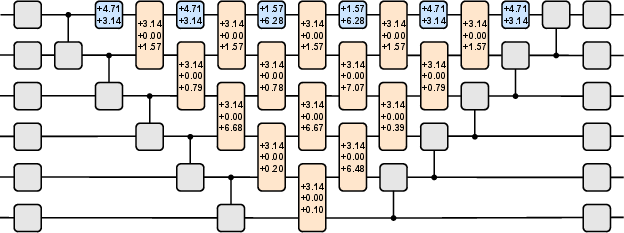
Figure 4: Learned QFT circuit for n=6.
The agent's solution generalizes to arbitrary n, implementing the QFT with O(n2) gates and O(n) depth, using a pattern of Hadamard gates, controlled-Z rotations with cascading phases, and SWAP operations.
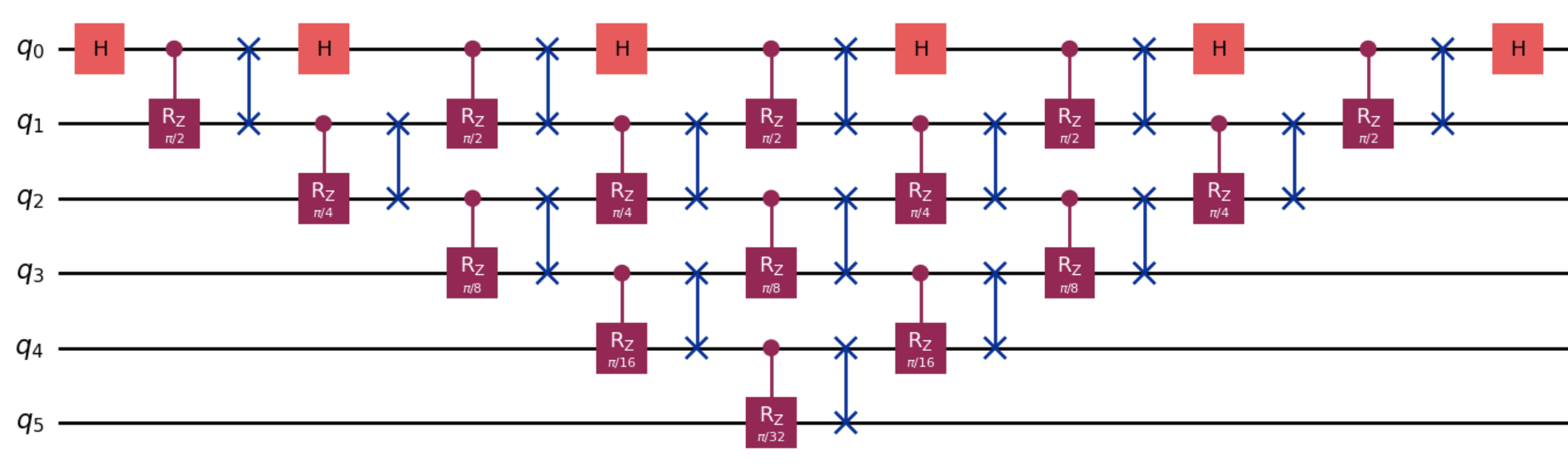
Figure 5: General QFT algorithm optimized for nearest-neighbor connectivity, as learned by the agent.
Grover's Search Algorithm
Agents were trained to rediscover Grover's search for N=4 and N=8 database sizes, with varying numbers of oracle calls. The learned circuits achieved success probabilities $0.999999$ (N=4, 1 query), $0.781249$ (N=8, 1 query), and $0.944770$ (N=8, 2 queries), all matching theoretical optima to numerical precision. The agent autonomously constructed the uniform superposition and the diffusion operator using only nearest-neighbor two-qubit gates, avoiding multi-controlled gates.

Figure 6: Trained circuit for Grover's search (N=4, one oracle call); pre-oracle block is equivalent to Hadamards.

Figure 7: Trained circuit for Grover's search (N=4, one oracle call) with fixed Hadamards; post-oracle block implements the diffusion operator.
Quantum Coin Flipping Protocols
The framework was applied to strong quantum coin flipping, with agents learning optimal cheating strategies against honest protocols. The trained agents achieved cheating probabilities PA∗=0.749992 and PB∗=0.749985, matching the known optimal bias of $0.75$. The parameterized circuits were expressive enough to capture both honest and adversarial strategies, demonstrating the ability to discover cryptographic attacks in multi-round interactive protocols.
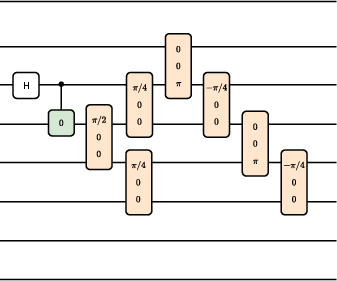
Figure 8: Circuit implementing the honest protocol's main unitary operation for quantum coin flipping.
CHSH and Conflicting-Interest Nonlocal Games
Agents were trained in both cooperative (CHSH) and competitive (conflicting-interest) nonlocal games. The learned strategies achieved average payoffs F=0.853553 (CHSH, matching Tsirelson's bound) and F=0.640154 (conflicting-interest, matching the quantum equilibrium). Circuit simplification revealed that only RYPhaseShift layers and CRY ladders were necessary, with agents autonomously discovering entanglement generation and optimal measurement settings.
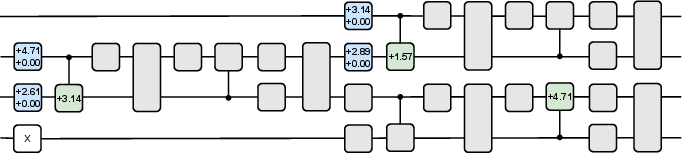
Figure 9: Trained quantum agents for CHSH and conflicting-interest games, using minimal circuit layers.
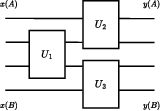
Figure 10: Interaction architecture for nonlocal games, enforcing input-independent entanglement generation.
Implementation and Scaling Considerations
All experiments were conducted on quantum simulators with training durations under 10 minutes and circuit sizes up to 12 qubits. The framework is explicitly designed for scalability: as problem size increases beyond classical simulability, the same learning loop transitions seamlessly to quantum hardware, with reward evaluation performed via quantum execution and finite-shot sampling. The PQC architecture is modular and can be adapted to different hardware topologies, gate sets, and depth constraints.
The agent-environment formalism supports arbitrary reward functions, enabling exploration of algorithmic primitives, cryptographic protocols, and quantum games. The direct policy search approach is compatible with gradient-based and gradient-free optimization, and the learned circuits are human-readable and interpretable, facilitating post-training analysis and generalization.
Theoretical and Practical Implications
The results demonstrate that quantum intelligent agents can autonomously rediscover foundational quantum algorithms and protocols solely from interaction and reward feedback, without prior knowledge of optimal solutions. This establishes quantum RL as a viable tool for algorithmic discovery, complementing analytic approaches and enabling exploration of algorithmic spaces inaccessible to classical learning systems.
The framework's reliance on quantum execution for reward evaluation is a critical distinction: classical agents cannot feasibly simulate quantum evolution for large-scale tasks, making quantum agents uniquely positioned for discovery in regimes where quantum resources are indispensable. The methodology is applicable to a wide range of domains, including quantum error correction, hardware co-design, and quantitative finance, where sequential decision-making under uncertainty is central.
Future Directions
Potential future developments include:
- Automated discovery of novel quantum algorithms and protocols for tasks where optimal solutions are unknown.
- Application to large-scale problems in finance, optimization, and error correction, leveraging quantum hardware for reward evaluation.
- Hardware co-design informed by agent-discovered circuit structures, enabling development of application-specific quantum processors.
- Extension to competitive and cooperative multi-agent environments, benchmarking quantum hardware and exploring game-theoretic strategies.
The integration of quantum computing and AI via quantum RL agents is poised to advance both theoretical understanding and practical deployment of quantum technologies, with implications for algorithmic innovation and hardware design.
Conclusion
The paper establishes a general, scalable framework for quantum algorithmic discovery via reinforcement learning with quantum agents. Through direct policy search and episodic reward optimization, agents autonomously rediscover optimal circuits for QFT, Grover's search, quantum coin flipping, and nonlocal games, matching theoretical performance bounds and generalizing to larger instances. The approach is hardware-aligned, interpretable, and extensible, providing a foundation for automated quantum algorithm design and opening new directions for quantum intelligence in scientific and industrial applications.