- The paper demonstrates that enforcing sparsity in Transformers leads to precise local causal graph learning.
- It introduces a methodology combining hard attention with the Gumbel-softmax trick for differentiable binary adjacency matrix learning.
- Experimental results show robust, sample-efficient adaptation and improved predictive accuracy in both simulated and real-world scenarios.
Introduction
The paper "SPARTAN: A Sparse Transformer Learning Local Causation" introduces SPARTAN, a Transformer-based world model aimed at learning local causal structures among entities by leveraging sparsity regularization on attention patterns. This approach addresses challenges inherent in dynamic environments where traditional methods often struggle to capture accurate local causal relationships due to the complexity of the interactions and the necessity for data efficiency in adaptation.
SPARTAN posits that utilizing sparsity is essential for the discovery of local causal graphs, particularly in complex settings where interactions are typically sparse and time-dependent (Figure 1).
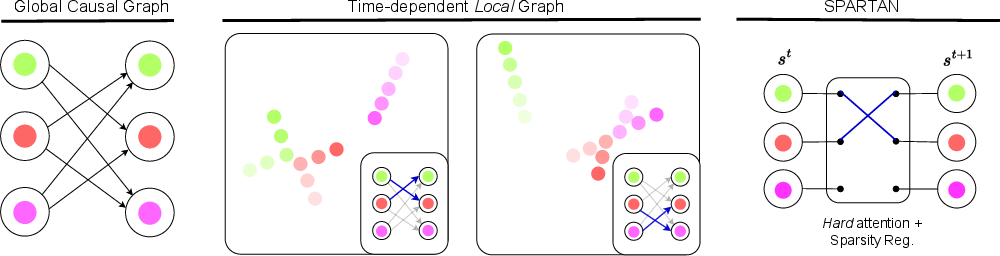
Figure 1: In the context of modelling physical interactions, a global causal graph is often uninformative and close to fully-connected. A time-dependent local causal graph better captures the sparse nature of interactions between entities.
Methodology
The implementation of SPARTAN starts with a standard Transformer architecture but incorporates sparsity through a mechanism that inhibits non-essential edges. In doing so, it learns binary adjacency matrices that dictate the flow of information between object-factored tokens in a scene, offering a state-dependent local causal graph. This approach makes use of hard attention combined with the Gumbel-softmax trick to enable differentiability in the learning process.
Key methodological innovations include:
- Sparse Attention Mechanism: SPARTAN applies sparsity regularization to the attention patterns in Transformers to prune non-essential connections dynamically, ensuring that only causal relationships pertinent to local interactions are retained.
- Interventions and Adaptation: The model can identify intervention targets within a scene, enhancing its adaptability in environments where dynamics change due to unknown interventions. Adaptation is guided by adjusting intervention tokens, trained based on observed trajectories.
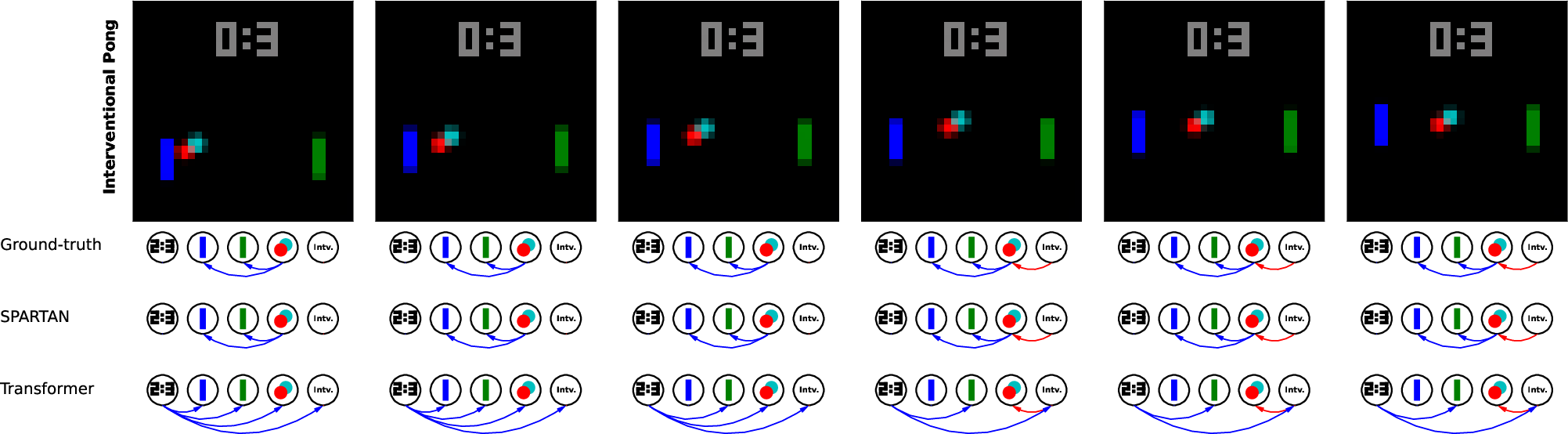
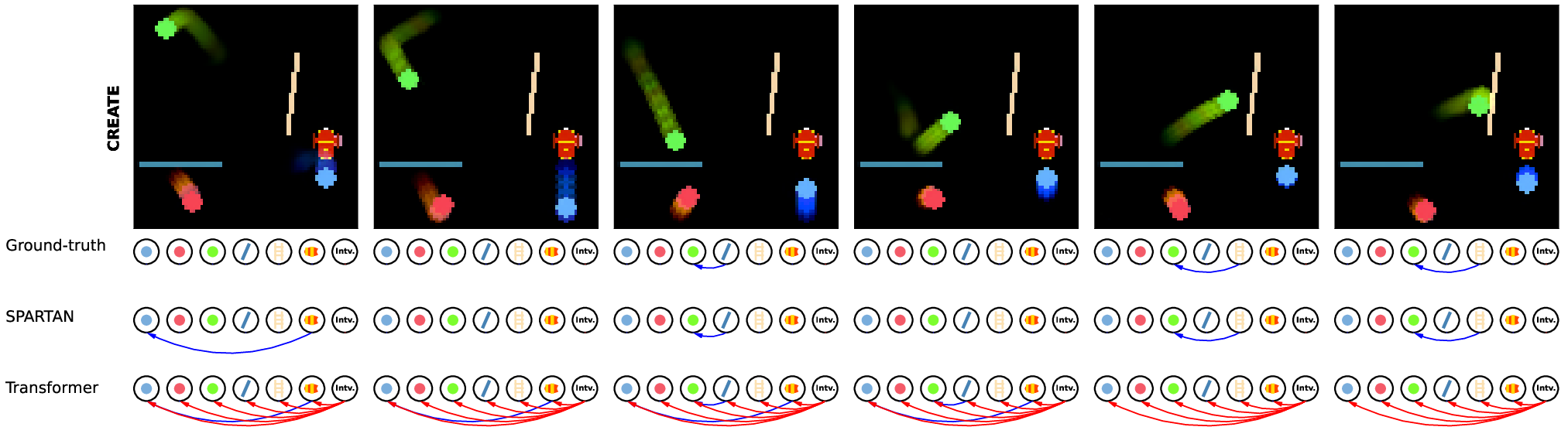
Figure 2: Example rollouts in two simulated environments with the learned local causal graph visualized. SPARTAN identifies causal dependencies accurately compared to a Transformer baseline.
Experiments and Results
The paper presents extensive experimental validation across different domains, including simulated environments like Interventional Pong and CREATE, as well as real-world datasets such as the Waymo Open Dataset for traffic scenarios. SPARTAN demonstrates superior performance in learning accurate local causal graphs and adapting to environment changes with fewer data resources than state-of-the-art Transformer-based models.
- Predictive Accuracy: SPARTAN consistently achieves prediction errors comparable to or better than fully-connected transformer models, proving its efficacy in maintaining predictive accuracy while enforcing sparsity.
- Causal Discovery: The Structural Hamming Distance (SHD) metric highlights that SPARTAN can infer causal graphs more accurately than baseline models. This is crucial for effectively identifying true causal relationships in the tested environments.
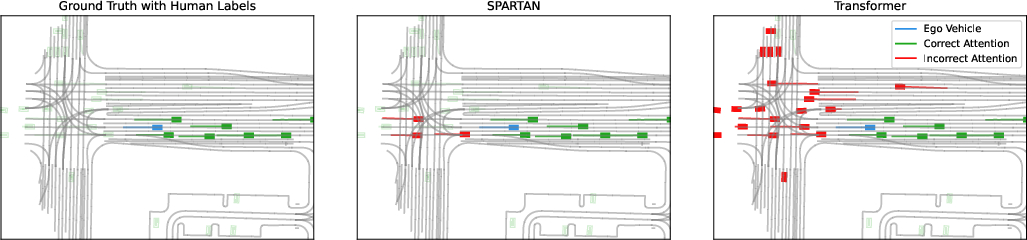
Figure 3: Visualisation of the causal relationships learned by the models compared to human-labeled data, emphasizing SPARTAN's focus on meaningful causal edges.
- Robustness and Adaptation: SPARTAN's ability to maintain low prediction errors even when non-causal entities are removed from scenes evidences its robustness. Moreover, its sample-efficient adaptation to previously unseen interventions showcases its generalization capabilities, marking a significant advancement over baseline models in few-shot adaptation scenarios.
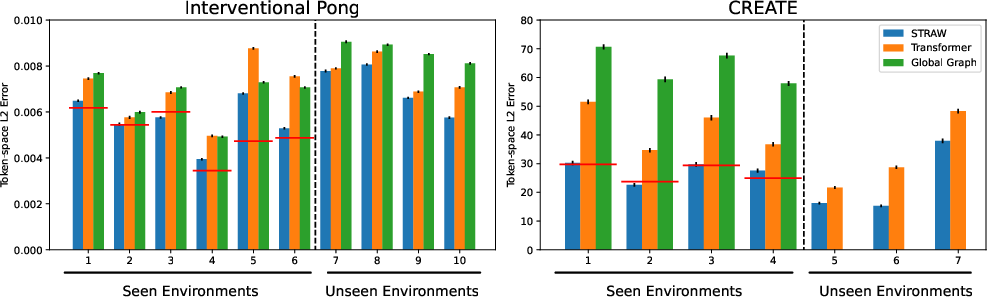
Figure 4: Adaptation errors on two datasets with SPARTAN achieving consistently low errors, reaching near lower bounds with few observed trajectories.
Discussion
SPARTAN leverages sparsity as a novel regularization paradigm to enforce meaningful causal graph learning in dynamic settings. By incorporating local causality into the architectural design of Transformers, SPARTAN not only accelerates inference through reduced complexity but also enhances interpretability owing to its sparse outputs. As a result, this approach efficiently tackles the challenges of dynamic and complex environments where causal relationships vary temporally and spatially.
The implications of this work extend to various AI applications requiring dynamic adaptation and inference accuracy, such as autonomous driving, where understanding causal relationships in traffic scenarios is critical for predicting and responding to changes effectively. Future research may focus on exploring extensions of the SPARTAN architecture for unsupervised learning scenarios or integrating domain knowledge to further enhance its robustness.
Conclusion
SPARTAN represents an important step forward in the development of models capable of learning and adapting within dynamic environments. Its ability to discover sparse, locally-accurate causal relationships offers a promising avenue for future AI systems requiring adaptability and precision in complex, dynamic scenarios. The framework shows the potential to synergize with emerging techniques in causal learning and object-centric modeling, offering rich possibilities for advancing AI research and application.