- The paper presents a five-level roadmap for advancing speech LLMs and introduces the SAGI Benchmark to standardize evaluation.
- It demonstrates that current models excel in basic ASR but struggle with integrating paralinguistic cues and abstract acoustic knowledge.
- The study identifies challenges like limited training data diversity and weak LLM backbones, urging innovations in model architecture for improved speech understanding.
Roadmap Towards Superhuman Speech Understanding using LLMs
Introduction
The paper "Roadmap towards Superhuman Speech Understanding using LLMs" (2410.13268) addresses the integration of speech and audio data into LLMs to develop general foundation models that can process both textual and non-textual inputs. Leveraging recent advancements in models like GPT-4o, the study explores the potential of end-to-end speech LLMs, which preserve non-semantic and world knowledge for more profound speech understanding. The authors propose a five-level roadmap for developing speech LLMs, introducing a benchmark—SAGI Benchmark—to standardize evaluation across these levels, illuminating gaps such as handling paralinguistic cues and integrating abstract acoustic knowledge.
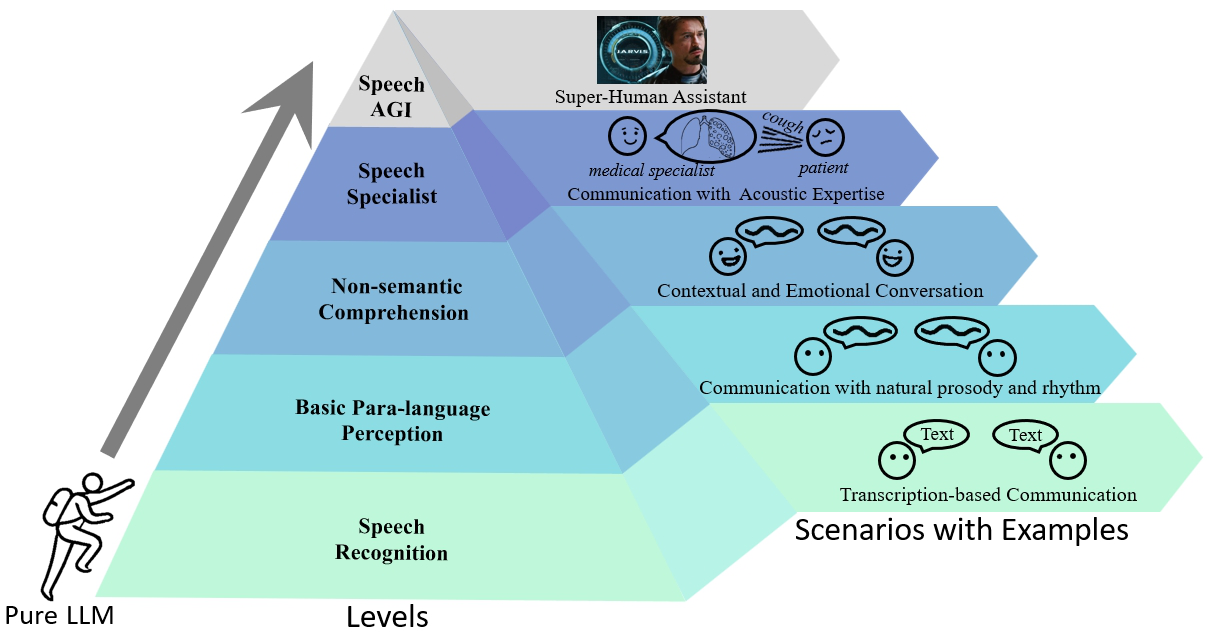
Five-Level Speech Understanding Framework
The proposed framework categorizes the progression of speech LLMs into five levels, with each level indicating a more sophisticated capability of understanding and processing speech.
The SAGI Benchmark
The SAGI Benchmark is designed to provide a comprehensive evaluation framework that aligns with the five-level roadmap. It assesses speech LLMs across a spectrum of tasks, including speech recognition, language distinction, volume perception, emotion recognition, and specialized tasks like medical diagnostics. This benchmark is crucial for understanding the current capabilities of speech LLMs and the challenges and limitations they face, particularly in handling diverse and complex tasks.
The study conducted extensive evaluations using both human participants and speech LLMs on various tasks categorized under each level. The findings indicate that humans generally perform well on tasks up to Level 3, but struggle with tasks requiring abstract acoustic knowledge. In contrast, current speech LLMs demonstrate strengths in specific tasks but lack the comprehensiveness to achieve higher-level capabilities. Notably, the models exhibit deficiencies in non-semantic perception, instruction following, and integration with weak LLM backbones.
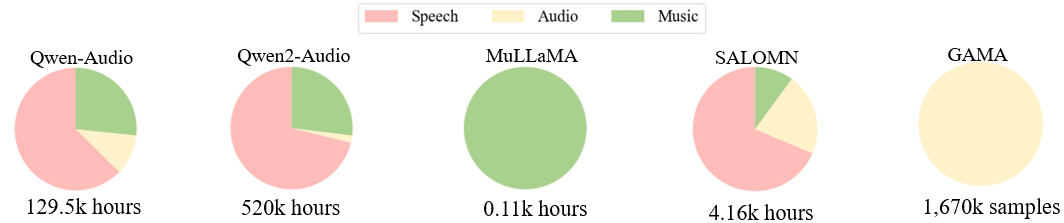
Figure 2: Distribution of three types of training data used by various models.
Challenges and Future Directions
Several critical challenges identified include:
- Data Diversity and Completeness: The training data for current speech LLMs is insufficiently diverse and complete, limiting their ability to generalize across different tasks.
- Acoustic Information Perception: Current end-to-end models fail to encode comprehensive acoustic information due to losses in representation and information transfer between modules.
- Instruction Following: Poor adherence to instructions highlights a need for more robust models that can comprehend and execute complex task requirements.
- LLM Backbone Limitations: The LLM backbones used in existing models are relatively weak in dealing with audio-related tasks, emphasizing the need for more powerful text LLMs that can process audio inputs effectively.
Conclusion
This paper presents a structured approach to advancing speech LLMs towards superhuman speech understanding. By defining a clear roadmap and developing the SAGI Benchmark, it offers a comprehensive framework for evaluating and guiding the progression of these models. The outlined challenges and future prospects underscore the necessity for innovations in training data diversity, model architecture, and foundational LLM capabilities to fully realize the potential of speech LLMs in understanding and interacting with human speech at a superhuman level.
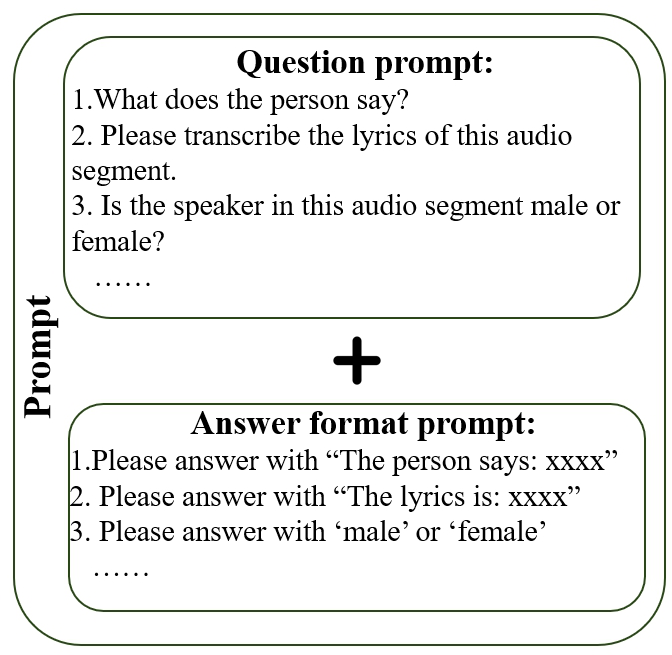
Figure 3: The method to generate text instructions for the problems.