A Survey on Speech Large Language Models for Understanding
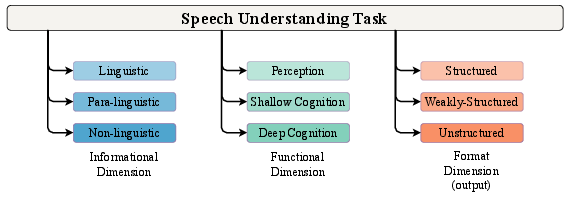
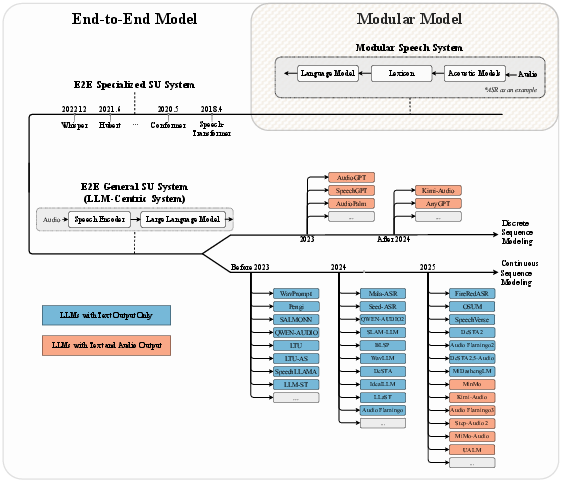
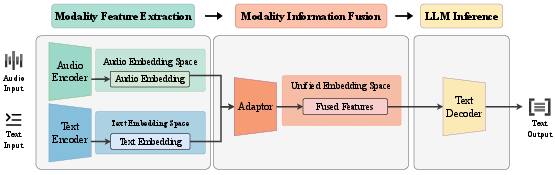
Abstract: Speech understanding is essential for interpreting the diverse forms of information embedded in spoken language, including linguistic, paralinguistic, and non-linguistic cues that are vital for effective human-computer interaction. The rapid advancement of LLMs has catalyzed the emergence of Speech LLMs (Speech LLMs), which marks a transformative shift toward general-purpose speech understanding systems. To further clarify and systematically delineate task objectives, in this paper, we formally define the concept of speech understanding and introduce a structured taxonomy encompassing its informational, functional, and format dimensions. Within this scope of definition, we present a comprehensive review of current Speech LLMs, analyzing their architectures through a three-stage abstraction: Modality Feature Extraction, Modality Information Fusion, and LLM Inference. In addition, we examine training strategies, discuss representative datasets, and review evaluation methodologies adopted in the field. Based on empirical analyses and experimental evidence, we identify two key challenges currently facing Speech LLMs: instruction sensitivity and degradation in semantic reasoning and propose concrete directions for addressing these issues. Through this systematic and detailed survey, we aim to offer a foundational reference for researchers and practitioners working toward more robust, generalizable, and human-aligned Speech LLMs.
- “Gpt-4 technical report,” arXiv preprint arXiv:2303.08774, 2023.
- “From large language models to large multimodal models: A literature review,” Applied Sciences, vol. 14, no. 12, 2024.
- “Learning transferable visual models from natural language supervision,” 2021.
- “Zero-shot text-to-image generation,” 2021.
- Spoken language understanding: Systems for extracting semantic information from speech, John Wiley & Sons, 2011.
- “A survey on spoken language understanding: Recent advances and new frontiers,” arXiv preprint arXiv:2103.03095, 2021.
- “Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 5884–5888.
- “Conformer: Convolution-augmented transformer for speech recognition,” in Proc. Interspeech, 2020, pp. 5036–5040.
- “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” in IEEE Transactions on Audio, Speech, and Language Processing, 2021.
- “Speecht5: Unified-modal encoder-decoder pre-training for spoken language processing,” arXiv preprint arXiv:2110.07205, 2021.
- “Modular end-to-end automatic speech recognition framework for acoustic-to-word model,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2174–2183, 2020.
- “Vall-e 2: Neural codec language models are human parity zero-shot text to speech synthesizers,” arXiv preprint arXiv:2406.05370, 2024.
- “Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities,” 2023.
- “Audiopalm: A large language model that can speak and listen,” 2023.
- “Pengi: An audio language model for audio tasks,” Advances in Neural Information Processing Systems, vol. 36, pp. 18090–18108, 2023.
- “Salmonn: Towards generic hearing abilities for large language models,” arXiv preprint arXiv:2310.13289, 2023.
- “Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models,” arXiv preprint arXiv:2311.07919, 2023.
- “Seed-asr: Understanding diverse speech and contexts with llm-based speech recognition,” arXiv preprint arXiv:2407.04675, 2024.
- “An embarrassingly simple approach for llm with strong asr capacity,” 2024.
- “Prompting large language models with speech recognition abilities,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 13351–13355.
- “Speechx: Neural codec language model as a versatile speech transformer,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024.
- “Deep speech 2: End-to-end speech recognition in english and mandarin,” in International conference on machine learning. PMLR, 2016, pp. 173–182.
- “Robust speech recognition via large-scale weak supervision,” in International conference on machine learning. PMLR, 2023, pp. 28492–28518.
- “Speech reallm–real-time streaming speech recognition with multimodal llms by teaching the flow of time,” arXiv preprint arXiv:2406.09569, 2024.
- “Multilingual and fully non-autoregressive asr with large language model fusion: A comprehensive study,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 13306–13310.
- “Findings of the iwslt 2023 evaluation campaign,” Association for Computational Linguistics, 2023.
- “Bigtranslate: Augmenting large language models with multilingual translation capability over 100 languages,” arXiv preprint arXiv:2305.18098, 2023.
- “Gentranslate: Large language models are generative multilingual speech and machine translators,” arXiv preprint arXiv:2402.06894, 2024.
- “Seamlessm4t-massively multilingual & multimodal machine translation,” arXiv preprint arXiv:2308.11596, 2023.
- “Uniaudio: An audio foundation model toward universal audio generation,” arXiv preprint arXiv:2310.00704, 2023.
- “Pengi: An audio language model for audio tasks,” in Advances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds. 2023, vol. 36, pp. 18090–18108, Curran Associates, Inc.
- “Mala-asr: Multimedia-assisted llm-based asr,” arXiv preprint arXiv:2406.05839, 2024.
- “Voxtlm: Unified decoder-only models for consolidating speech recognition, synthesis and speech, text continuation tasks,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 13326–13330.
- “Lauragpt: Listen, attend, understand, and regenerate audio with gpt,” arXiv preprint arXiv:2310.04673, 2023.
- “Viola: Unified codec language models for speech recognition, synthesis, and translation,” arXiv preprint arXiv:2305.16107, 2023.
- “Bat: Learning to reason about spatial sounds with large language models,” arXiv preprint arXiv:2402.01591, 2024.
- “Decoder-only architecture for speech recognition with ctc prompts and text data augmentation,” 2024.
- “Spirit-lm: Interleaved spoken and written language model,” 2024.
- “Superb: Speech processing universal performance benchmark,” in Interspeech, 2021, pp. 1194–1198.
- “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” in Advances in Neural Information Processing Systems, 2022.
- “Anygpt: Unified multimodal llm with discrete sequence modeling,” arXiv preprint arXiv:2402.12226, 2024.
- “Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities,” arXiv preprint arXiv:2402.01831, 2024.
- “Ai alignment: A comprehensive survey,” arXiv preprint arXiv:2310.19852, 2023.
- “Enhancing zero-shot text-to-speech synthesis with human feedback,” arXiv preprint arXiv:2406.00654, 2024.
- “Preference alignment improves language model-based tts,” arXiv preprint arXiv:2409.12403, 2024.
- “Librispeech: an asr corpus based on public domain audio books,” in 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015, pp. 5206–5210.
- “Prompting large language model for machine translation: A case study,” in International Conference on Machine Learning. PMLR, 2023, pp. 41092–41110.
- “Fleurs: Few-shot learning evaluation of universal representations of speech,” in 2022 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2023, pp. 798–805.
- “The flores-101 evaluation benchmark for low-resource and multilingual machine translation,” Transactions of the Association for Computational Linguistics, vol. 10, pp. 522–538, 2022.
- “No language left behind: Scaling human-centered machine translation,” arXiv preprint arXiv:2207.04672, 2022.
- “Findings of the 2020 conference on machine translation (wmt20),” in Proceedings of the Fifth Conference on Machine Translation. Association for Computational Linguistics,, 2020, pp. 1–55.
- “Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio,” arXiv preprint arXiv:2106.06909, 2021.
- “Sd-eval: A benchmark dataset for spoken dialogue understanding beyond words,” arXiv preprint arXiv:2406.13340, 2024.
- “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.
- “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” arXiv preprint arXiv:2311.05232, 2023.
- “A full-duplex speech dialogue scheme based on large language models,” arXiv preprint arXiv:2405.19487, 2024.
- “Towards achieving human parity on end-to-end simultaneous speech translation via llm agent,” arXiv preprint arXiv:2407.21646, 2024.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.