- The paper critically evaluates various summarisation metrics by comparing automatic measures with human judgments to identify performance discrepancies.
- It highlights the gap between system-level and summary-level evaluations, stressing the need for standardized annotation practices and diverse benchmarks.
- The study advocates for incorporating domain-specific quality dimensions and user-centric evaluations to enhance faithfulness and practical applicability in NLP.
Introduction
The evaluation of summarisation metrics is pivotal in the development and assessment of NLP systems. This paper explores the practices of meta-evaluation for summarisation metrics, identifies prevailing trends, and advocates for more diverse benchmarks and methodologies. Notably, the study emphasizes the increasing focus on faithfulness in summary generation and the necessity for benchmarks that accurately reflect the domain-specific needs and user interactions with summarised content.
Summarisation Evaluation Metrics
Summarisation metrics primarily fall into categories such as summary-only, similarity-based, entailment-based, QA-based, learning-based, and LLM-based metrics. Each category utilizes different aspects of the input data (e.g., source text, generated summary) and employs varied methodologies to assess the quality of summarisation. These metrics are crucial for evaluating summarisation systems for clarity, coherence, and factual consistency.
Meta-evaluation seeks to assess the reliability and validity of summarisation metrics by comparing them against human judgments. Typically, this involves calculating the correlation between the evaluation results of automatic metrics and human judgements across a set of generated summaries. The findings highlight the discrepancy between system-level and summary-level evaluations, underscoring the complexity of accurately reflecting human judgements in automatic evaluations.
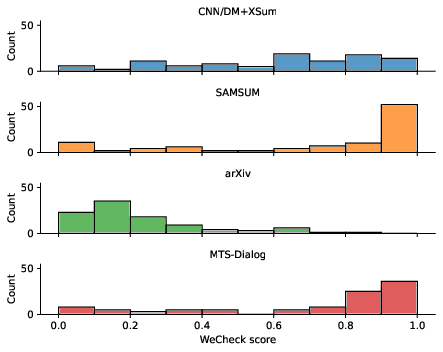
Figure 1: The distribution of consistency scores, measured using WeCheck, between source text and reference summary from different datasets.
Choosing Data to Annotate
Current benchmarks frequently rely on datasets from news and dialogue summarisation, potentially limiting the generalization of evaluation metrics to other domains. This raises concerns about the adaptability and domain-specific effectiveness of summarisation metrics. The paper calls for benchmarks that encompass a wider array of domains and summarisation constraints to enhance the robustness and applicability of these metrics.
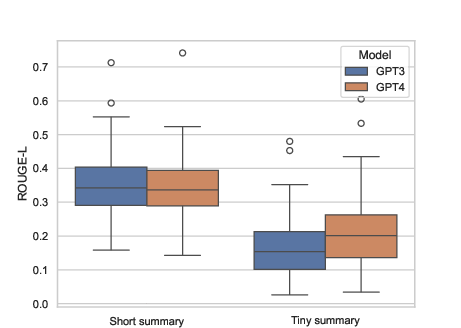
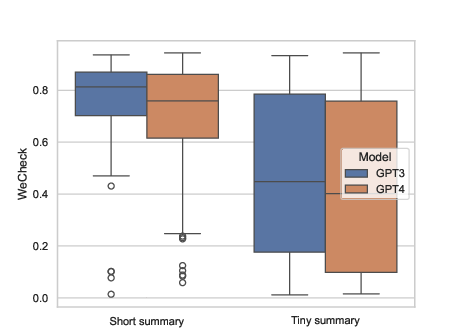
Figure 2: Evaluation results using ROUGE-L, where higher scores indicate more overlap between generated and reference summaries.
Defining Quality Dimensions
While recent efforts predominantly focus on intrinsic evaluation metrics like coherence and faithfulness, extrinsic evaluations considering user-centric quality dimensions remain underexplored. Such an approach acknowledges the variability in user preferences and application scenarios, which is essential for developing user-aligned summarisation systems.
Collecting Human Judgements
The efficacy of summarisation metrics significantly hinges on the quality of human annotations used for meta-evaluation. The paper highlights the need for improved annotation guidelines and involvement of end-users in the annotation process, which could better reflect real-world applications and expectations. It also suggests standardizing practices to ensure consistency and reliability across evaluations.
Comparing Automatic Metrics Against Human Judgements
Assessing the correlation between automatic metrics and human judgments remains a key component of meta-evaluation. However, the paper argues that high correlation alone may not suffice to certify the effectiveness of a metric. Factors such as the metric's ability to detect errors in similar-quality systems, statistical power, and the impact of reference summaries play crucial roles in comprehensive evaluations.
Figure 3: Evaluation results using WeCheck, where higher scores indicate higher consistency levels between source texts and generated summaries.
Conclusion
The paper advocates for the development of more diverse and standardised benchmarks that cater to varied domains and capture the nuances of user-centric quality dimensions. By refining evaluation methodologies, including data selection, quality dimension definition, and annotation practices, the field can advance towards more reliable and applicable summarisation metrics. This progress is vital for fostering robust systems that align with users' diverse and evolving needs.
In summary, the paper posits that enhancing the generality and domain-specific applicability of summarisation metrics, alongside standardised meta-evaluation practices, will lead to effective and user-aligned summarisation systems in NLP.