- The paper demonstrates that 14 evaluation metrics show variable correlations with human judgments, especially for coherence and relevance.
- It leverages a large collection of CNN/DailyMail model outputs with expert and crowd-sourced annotations to benchmark 23 neural summarization models.
- The study introduces an adaptable API and standardized protocol, encouraging future improvements in summarization evaluation practices.
SummEval: Re-evaluating Summarization Evaluation
Introduction
The paper "SummEval: Re-evaluating Summarization Evaluation" presents a comprehensive and consistent re-evaluation of automatic evaluation metrics for text summarization. It leverages outputs from various neural summarization models, coupled with expert and crowd-sourced human annotations. The study is motivated by limitations in existing summarization evaluation methods and introduces several improvements across five dimensions, including re-evaluation of 14 automatic metrics and providing a benchmark for 23 recent summarization models.
Evaluation Metrics and Summarization Models
Evaluation Metrics
The study examines 14 evaluation metrics, notably ROUGE, BertScore, MoverScore, and others like S3, CHRF, and CIDEr. These metrics are evaluated for their ability to correlate with human judgments acroos four quality dimensions: coherence, consistency, fluency, and relevance.
Summarization Models
The paper evaluates outputs from 23 summarization models using these metrics. The models are categorized into extractive and abstractive methods, including BART, Pegasus, and T5. These models are indicative of recent advancements in neural summarization approaches.
Methodology
The authors assemble the largest collection of model-generated summaries trained on the CNN/DailyMail dataset, complemented by expert and crowd-sourced human judgments. They introduce a toolkit providing an extensible API for evaluating summarization models across various metrics, promoting a standardized evaluation protocol.
Human Annotation Analysis
The paper highlights significant discrepancies between expert and crowd-source annotations. Krippendorff's alpha coefficients indicate low inter-annotator agreement within both groups initially, with subsequent rounds of expert annotation improving agreement substantially. These results underline the challenges in achieving consistent human evaluations, primarily when distinguishing between coherence, consistency, and relevance.
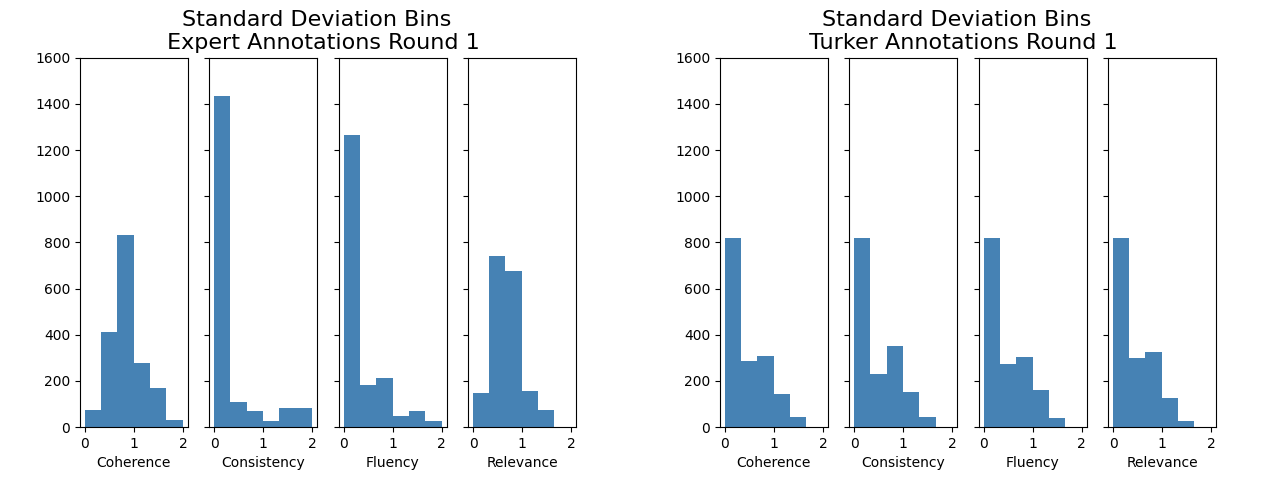
Figure 1: Histogram of standard deviations of expert annotations and annotations from the first round of annotations across the four quality dimensions.
Metric Correlation Analysis
Findings reveal moderate to strong correlations for most metrics with consistency and fluency, whereas coherence and relevance show lower correlations. These tendencies suggest inherent limitations in current metrics for capturing coherence and relevance effectively.
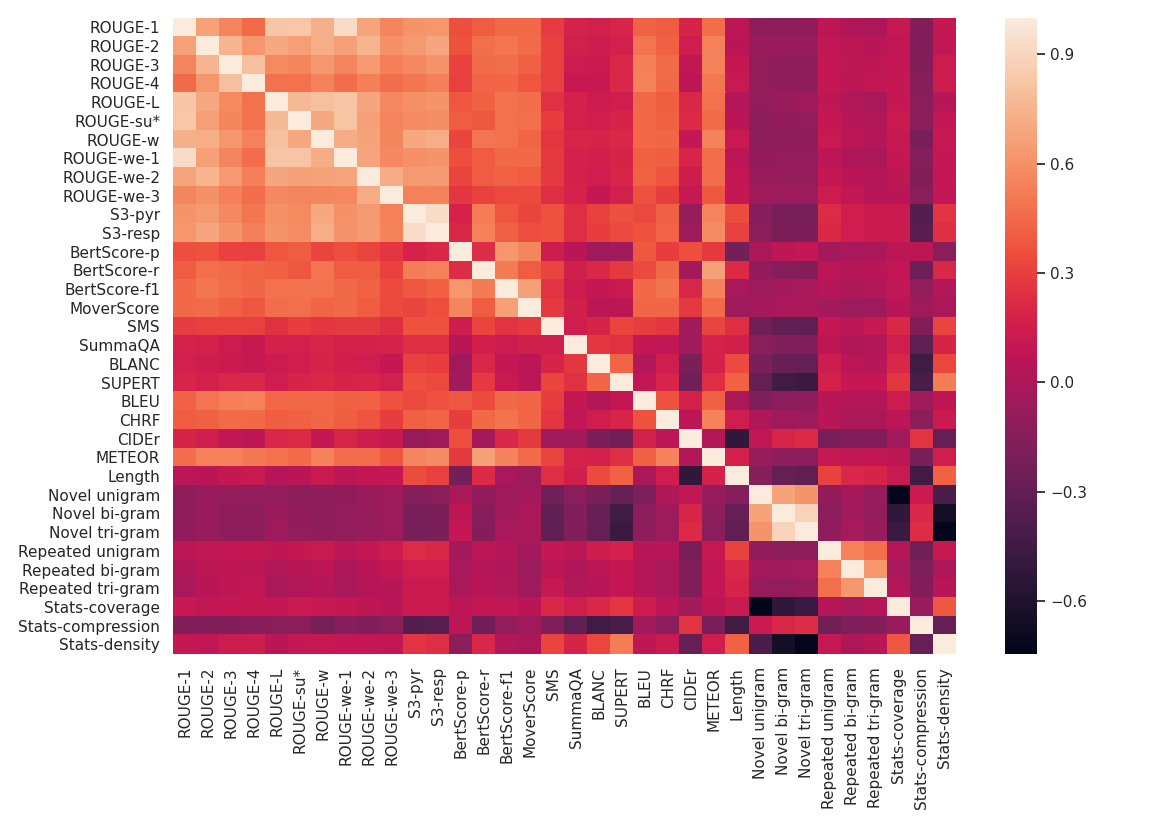
Figure 2: Pairwise Kendall's Tau correlations for all automatic evaluation metrics.
Model Re-evaluation
Through human and automatic evaluations, the study observes that models like Pegasus, BART, and T5 consistently achieve higher scores, suggesting progress in model quality over time. Furthermore, reference summaries in the CNN/DailyMail dataset received relatively low scores, attributed to issues like extraneous information and lack of coherence. These insights highlight areas for improvement in summarization model benchmarking and dataset quality.
Conclusion
The study underscores a comprehensive re-evaluation framework for summarization metrics and models. It advocates for improved evaluation protocols, addressing limitations in current methods, and urges future research towards more coherent and relevant metric designs. The resources and findings presented aim to propel advancements in summarization evaluation practices, encouraging engagement from the research community to refine these processes.