- The paper presents a novel benchmark integrating memory retrieval and recognition to assess dialogue systems’ memory-injection ability and emotional support.
- It utilizes cognitive science and psychology theories to simulate human memory recall and measure aspects like intimacy and emotional improvements.
- Experimental findings reveal that while advanced models excel in natural language generation, enhancements are needed for contextually accurate memory injection.
Introduction to MADial-Bench
The paper "MADial-Bench: Towards Real-world Evaluation of Memory-Augmented Dialogue Generation" (2409.15240) introduces a novel approach for evaluating Memory-Augmented Dialogue Systems (MADS). While traditional assessment focuses on query accuracy and language metrics, this benchmark broadens the evaluation scope to encompass human-like interaction elements using cognitive science and psychology theories. A distinctive feature of this benchmark is its integration of memory recall paradigms, including both passive and proactive dimensions triggered by varied stimuli like emotions and surroundings.
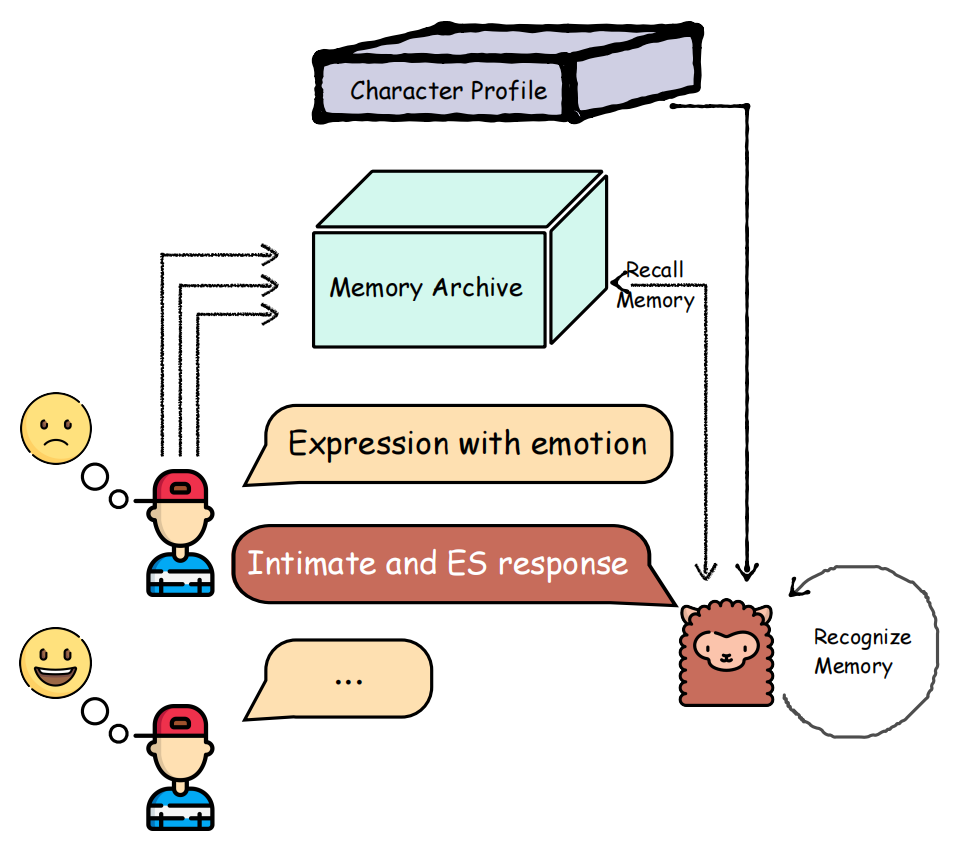
Figure 1: Memory Augmented Dialogue System with Emotion Support based on two-stage theory.
Benchmark Design
MADial-Bench is structured to assess dialogue systems across two distinct tasks: memory retrieval and recognition. It incorporates scoring metrics such as memory injection ability, proficiency in providing emotion support (ES), and intimacy levels, to offer comprehensive analyses of system responses. The benchmark is predicated on the two-stage theory of memory processes, differentiating between initial memory search and subsequent recognition phases, which simulate human memory recall.
Data Construction
The benchmark facilitates diverse memory recall scenarios through a bifurcated approach of proactive and passive recall. It curates dialogues focused on emotional states such as happiness, sadness, anxiety, and disappointment, offering a wide spectrum for emotional engagement. The dataset features dialogues detailed in multi-turn exchanges, emphasizing memory roles in imparting emotional support.
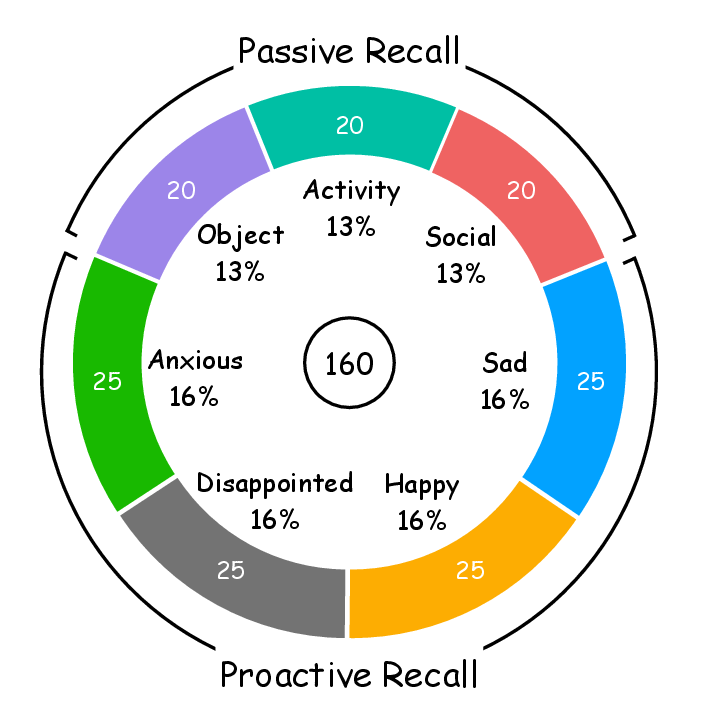
Figure 2: Data distribution of each task and category.
Evaluation Methodology
Memory Recalling and Recognition
The benchmark emphasizes the retrieval of relevant dialogue memories from a comprehensive memory bank. Embedding models are evaluated on metrics including MAP, MRR, and nDCG, showcasing a gap in retrieval effectiveness underscoring the challenge of aligning text similarity with memory recall in dialogues.
Response generation further necessitates models to select and properly integrate remembered content into active dialogue using detailed criteria reflective of memory-injection abilities. The evaluation spans multi-situation settings to replicate practical conversational climates, assessing memory utilization proficiency.
Aspect-based Evaluation
Aspect-aware scoring in human evaluations measures facets such as Naturalness, Style Coherence, Memory Injection Ability, ES Proficiency, and Emotional Improvement. The analysis reveals correlations between memory capabilities and emotional support proficiency, with intimacy metrics highlighting how well responses simulate personal connection characteristics.
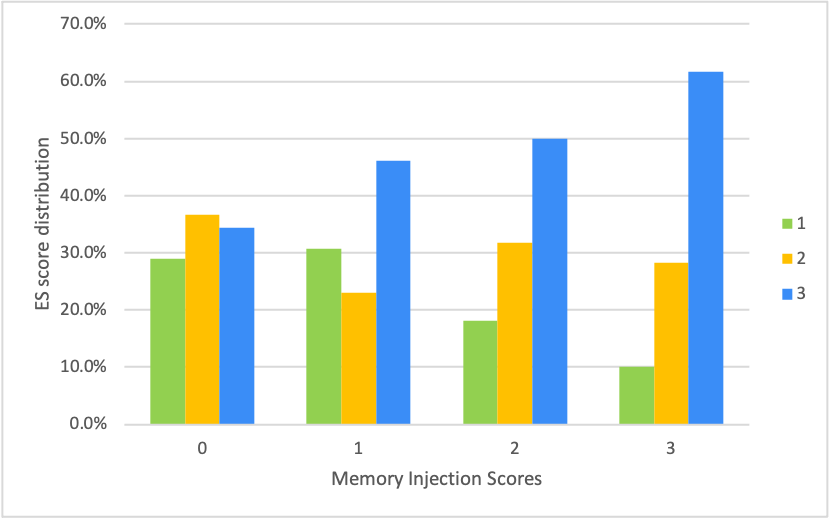
Figure 3: The relation between memory injection score and ES Proficiency. The probability of a 3.0 ES score grows as memory injection scores increases.
Experimental Findings
The experiments reveal significant insights:
- Memory Retrieval Performance: Notably, top-tier models like the OpenAI embedding model excel in retrieval tasks, yet performances remain notably underwhelming, suggesting improvement areas in enhancing contextually apt memory recalls.
- LLM Response Generation: Among vast-array tested models, GPT4-Turbo registered superior performance, particularly in language naturalness and emotional expression. However, accuracy in recognizing and aptly injecting memories suggests potential areas for model optimizations.
- Human versus Automated Evaluation: The paper delineates divergence between human assessment and automated scoring metrics, accentuating the limitations of static evaluation standards when assessing LLM-generated content.
Conclusion
The MADial-Bench establishes a robust evaluation framework for MADS, integrating human cognitive paradigms into systematic benchmarks for real-world dialogue settings. The assertions of memory-augmented dialogue capabilities elucidate future prospects to foster systems with elevated human interaction accuracy and emotional intelligence. Despite current computational limitations, the findings propound broad avenues—especially in emotional support—toward refining dialogue systems for genuinely enhanced conversational experiences.

