- The paper introduces Adam-mini, an optimizer that reduces memory usage by 45-50% while matching AdamW's performance.
- It employs Hessian-based parameter partitioning to assign unified learning rates per block, enhancing training throughput on LLMs.
- Experimental results show a 49.6% throughput increase on Llama2-7B and consistent performance across non-LLM tasks like ResNet and diffusion models.
Adam-mini: Use Fewer Learning Rates To Gain More
Introduction
The paper introduces Adam-mini, an optimization algorithm that claims to match or surpass the performance of AdamW while reducing memory usage by 45% to 50%. Adam-mini achieves this by utilizing fewer learning rate resources through careful parameter partitioning based on Hessian structure. The approach identifies that for certain parameter blocks, a single, well-chosen learning rate suffices. This results in increased throughput during training, especially evident in LLMs, as demonstrated with Llama2-7B.
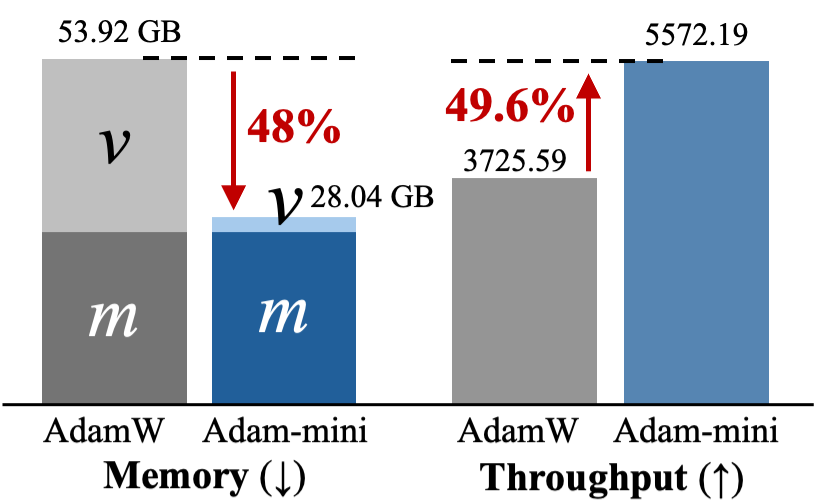
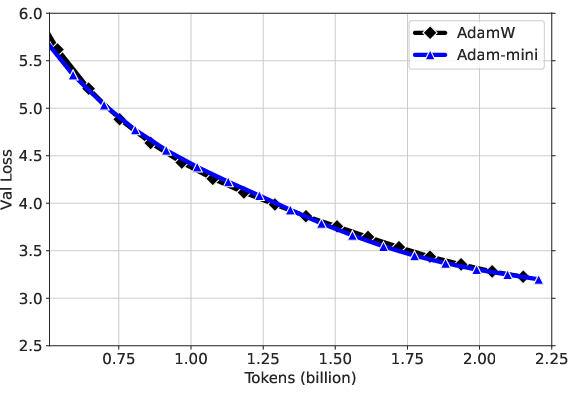
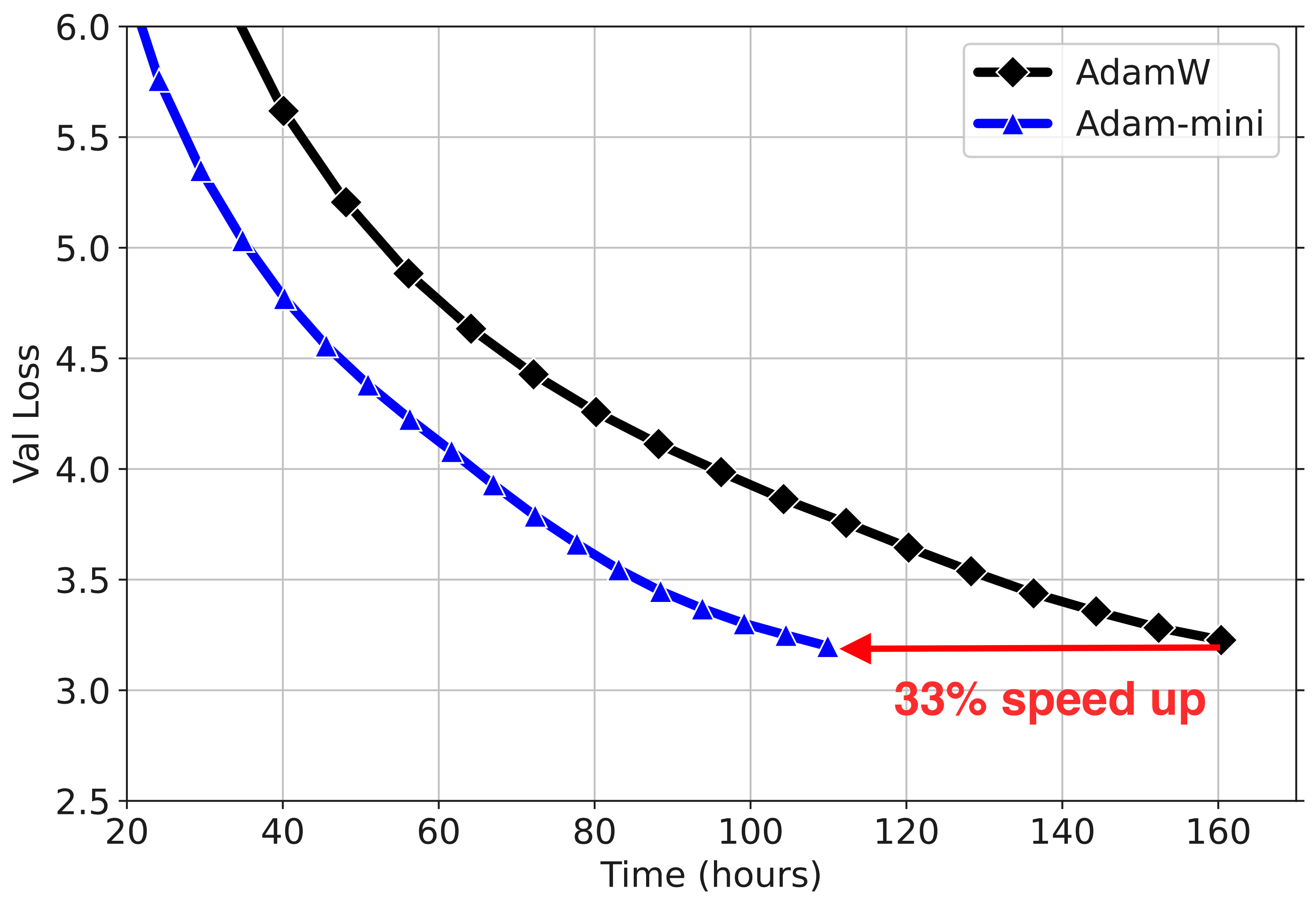
Figure 1: Results for Llama2-7B pre-training. (a) Adam-mini takes less memory and can reach higher throughput (# tokens per second). The throughput is tested on 2× A800-80GB GPUs. (b, c) Adam-mini performs on-par with AdamW, but takes 33\% less time for processing the same # tokens.
Methodology
Design Principles
Adam-mini focuses on memory reduction by partitioning the parameters into blocks and assigning a single learning rate to each block guided by the Hessian structure. The optimizer employs the average of Adam’s second-order momentum across parameter blocks to determine the learning rate, significantly reducing the memory overhead from maintaining individual learning rates for each parameter.
Implementation Steps
- Parameter Partitioning: Parameters are divided into blocks based on the smallest dense sub-blocks in the Hessian matrix. For Transformers, this involves partitioning Query and Key by heads and treating Values as dense sub-blocks.
- Learning Rate Assignment: A single learning rate is derived for each parameter block by computing the average squared gradients across the block. The resulting optimizer is Adam-mini, which effectively reduces the number of learning rate allocations from parameter count to block count.
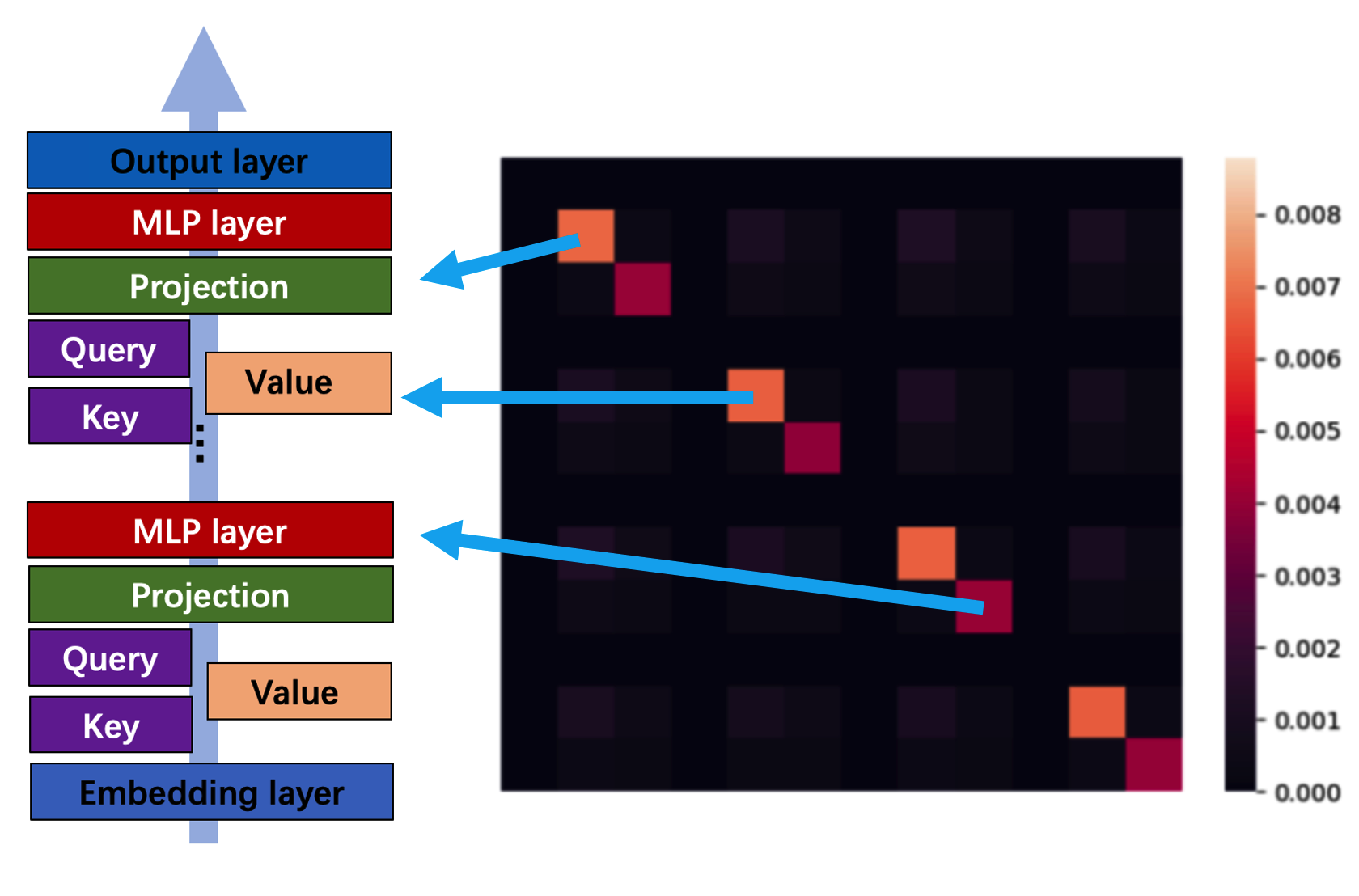

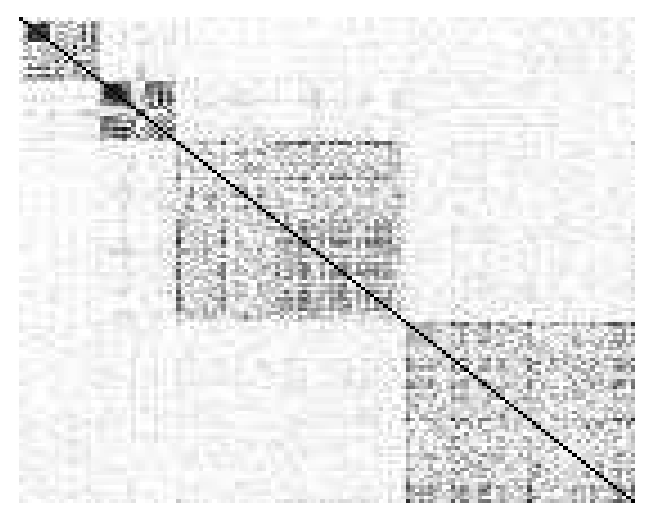

Figure 2: The Hessian of neural nets have near-block-diagonal structure. This is widely reported in the literature on Transformers (a) and various multi-layer perceptrons (MLPs) (b)(c)(d).
Experimental Analysis
The experiments highlight that Adam-mini performs comparably to AdamW in various LLM tasks, including pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), with significantly reduced memory consumption. For instance, it demonstrates a 49.6% increase in throughput during Llama2-7B pre-training on limited GPU resources.
Robustness Across Tasks
Adam-mini not only excels in LLM tasks but also shows promising results in non-LLM contexts, such as training ResNet on ImageNet and diffusion models on CelebA, maintaining or improving performance compared to AdamW while utilizing less memory.
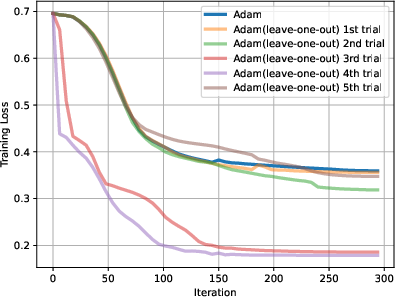
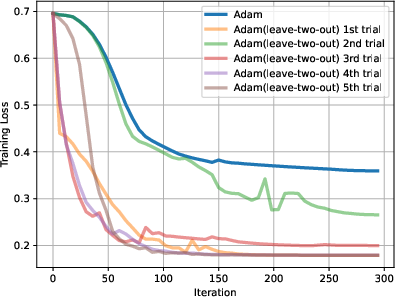
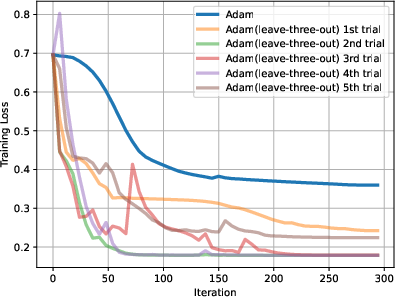
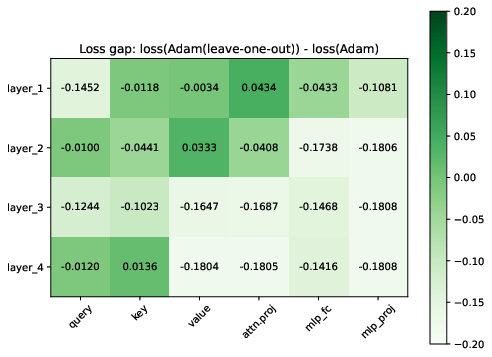
Figure 3: (a) (b) (c) Adam (leave-x-out) can reach similar or better performance than Adam for all randomly picked left-out blocks. x =1, 2,3. (d) The performance gap between Adam and Adam (leave-one-out) for all possible blocks. Adam (leave-one-out) always performs on par with Adam, often performing better.
Implications
The reduction in memory footprint without compromising performance is critical for scaling large models efficiently, reducing energy consumption, and broadening access to training LLMs. Adam-mini’s success in employing fewer learning rates while maintaining high performance encourages further research into adaptive learning rate assignments tailored to neural net structures.
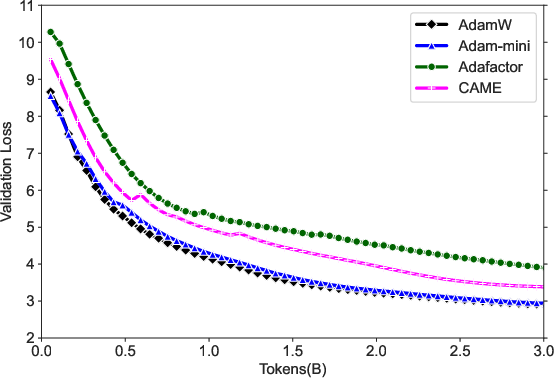
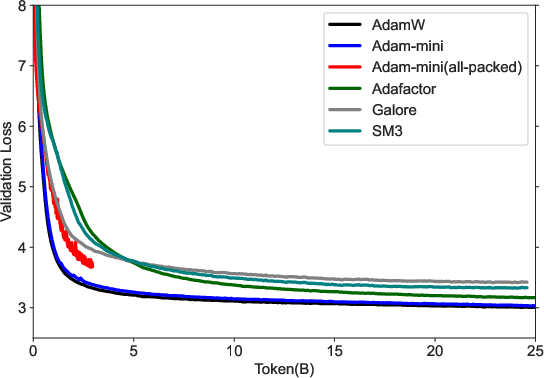
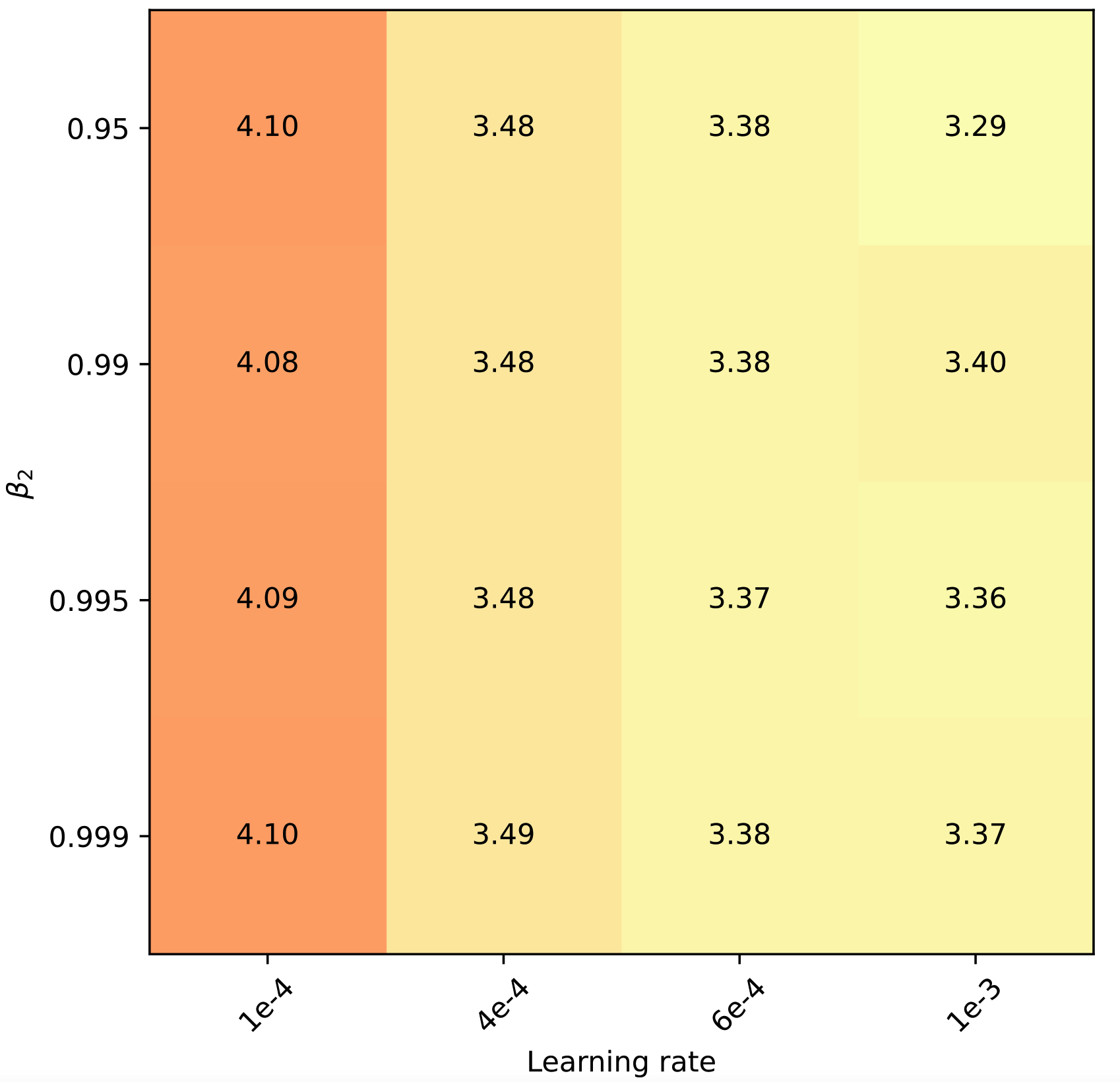
Figure 4: Training curves of (a) TinyLlama-1B. (b) GPT2-125M. Adam-mini performs on par as AdamW with less memory, while other methods perform worse on these tasks. (c): Adam-mini seems not sensitive to hyperparameters.
Conclusion
Adam-mini presents a significant step forward in optimizing LLM training by balancing performance with resource efficiency. Its novel approach to learning rate management offers a blueprint for future optimizer developments. Further exploration into fine-tuning learning rates specific to Hessian sub-blocks could enhance its efficacy, positioning Adam-mini as a versatile tool in the neural network training arsenal.