Smart-Infinity: Fast Large Language Model Training using Near-Storage Processing on a Real System
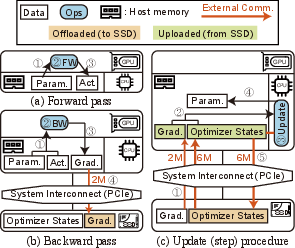
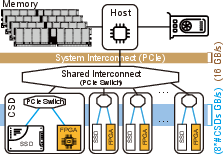
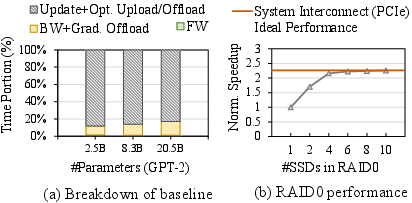
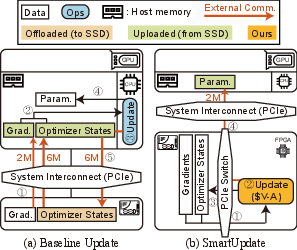
Abstract: The recent huge advance of LLMs is mainly driven by the increase in the number of parameters. This has led to substantial memory capacity requirements, necessitating the use of dozens of GPUs just to meet the capacity. One popular solution to this is storage-offloaded training, which uses host memory and storage as an extended memory hierarchy. However, this obviously comes at the cost of storage bandwidth bottleneck because storage devices have orders of magnitude lower bandwidth compared to that of GPU device memories. Our work, Smart-Infinity, addresses the storage bandwidth bottleneck of storage-offloaded LLM training using near-storage processing devices on a real system. The main component of Smart-Infinity is SmartUpdate, which performs parameter updates on custom near-storage accelerators. We identify that moving parameter updates to the storage side removes most of the storage traffic. In addition, we propose an efficient data transfer handler structure to address the system integration issues for Smart-Infinity. The handler allows overlapping data transfers with fixed memory consumption by reusing the device buffer. Lastly, we propose accelerator-assisted gradient compression/decompression to enhance the scalability of Smart-Infinity. When scaling to multiple near-storage processing devices, the write traffic on the shared channel becomes the bottleneck. To alleviate this, we compress the gradients on the GPU and decompress them on the accelerators. It provides further acceleration from reduced traffic. As a result, Smart-Infinity achieves a significant speedup compared to the baseline. Notably, Smart-Infinity is a ready-to-use approach that is fully integrated into PyTorch on a real system. We will open-source Smart-Infinity to facilitate its use.
- J. Ahn, S. Hong, S. Yoo, O. Mutlu, and K. Choi, “A scalable processing-in-memory accelerator for parallel graph processing,” in ISCA, 2015.
- J. Ahn, S. Yoo, O. Mutlu, and K. Choi, “PIM-enabled instructions: a low-overhead, locality-aware processing-in-memory architecture,” in ISCA, 2015.
- D. Alistarh, T. Hoefler, M. Johansson, S. Khirirat, N. Konstantinov, and C. Renggli, “The convergence of sparsified gradient methods,” in NeurIPS, 2018.
- H. Asghari-Moghaddam, Y. H. Son, J. H. Ahn, and N. S. Kim, “Chameleon: Versatile and practical near-DRAM acceleration architecture for large memory systems,” in MICRO, 2016.
- Y. Bengio, N. Léonard, and A. Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,” arXiv preprint arXiv:1308.3432, 2013.
- J. Bernstein, J. Zhao, K. Azizzadenesheli, and A. Anandkumar, “SignSGD with majority vote is communication efficient and fault tolerant,” arXiv preprint arXiv:1810.05291, 2018.
- A. Boroumand, S. Ghose, Y. Kim, R. Ausavarungnirun, E. Shiu, R. Thakur, D. Kim, A. Kuusela, A. Knies, P. Ranganathan, and O. Mutlu, “Google workloads for consumer devices: Mitigating data movement bottlenecks,” in ASPLOS, 2018.
- T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” in NeurIPS, 2020.
- W. Cao, Y. Liu, Z. Cheng, N. Zheng, W. Li, W. Wu, L. Ouyang, P. Wang, Y. Wang, R. Kuan, Z. Liu, F. Zhu, and T. Zhang, “POLARDB meets computational storage: Efficiently support analytical workloads in cloud-native relational database,” in FAST, 2020.
- C.-C. Chen, C.-L. Yang, and H.-Y. Cheng, “Efficient and robust parallel DNN training through model parallelism on multi-gpu platform,” arXiv preprint arXiv:1809.02839, 2018.
- C.-Y. Chen, J. Choi, D. Brand, A. Agrawal, W. Zhang, and K. Gopalakrishnan, “AdaComp : Adaptive residual gradient compression for data-parallel distributed training,” in AAAI, 2018.
- C.-Y. Chen, J. Ni, S. Lu, X. Cui, P.-Y. Chen, X. Sun, N. Wang, S. Venkataramani, V. V. Srinivasan, W. Zhang, and K. Gopalakrishnan, “ScaleCom: Scalable sparsified gradient compression for communication-efficient distributed training,” in NeurIPS, 2020.
- T. Chen, B. Xu, C. Zhang, and C. Guestrin, “Training deep nets with sublinear memory cost,” arXiv preprint arXiv:1604.06174, 2016.
- M. Cho, V. Muthusamy, B. Nemanich, and R. Puri, “Gradzip: Gradient compression using alternating matrix factorization for large-scale deep learning,” in NeurIPS, 2019.
- S. Cho, C. Park, H. Oh, S. Kim, Y. Yi, and G. R. Ganger, “Active disk meets flash: A case for intelligent ssds,” in ICS, 2013.
- J. Choi, S. Venkataramani, V. V. Srinivasan, K. Gopalakrishnan, Z. Wang, and P. Chuang, “Accurate and efficient 2-bit quantized neural networks,” in MLSys, 2019.
- A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y. Tay, N. Shazeer, V. Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghemawat, S. Dev, H. Michalewski, X. Garcia, V. Misra, K. Robinson, L. Fedus, D. Zhou, D. Ippolito, D. Luan, H. Lim, B. Zoph, A. Spiridonov, R. Sepassi, D. Dohan, S. Agrawal, M. Omernick, A. M. Dai, T. S. Pillai, M. Pellat, A. Lewkowycz, E. Moreira, R. Child, O. Polozov, K. Lee, Z. Zhou, X. Wang, B. Saeta, M. Diaz, O. Firat, M. Catasta, J. Wei, K. Meier-Hellstern, D. Eck, J. Dean, S. Petrov, and N. Fiedel, “PaLM: Scaling language modeling with pathways,” arXiv preprint arXiv:2204.02311, 2022.
- V. Codreanu, D. Podareanu, and V. Saletore, “Scale out for large minibatch SGD: Residual network training on ImageNet-1K with improved accuracy and reduced time to train,” arXiv preprint arXiv:1711.04291, 2017.
- J. Cong, J. Lau, G. Liu, S. Neuendorffer, P. Pan, K. Vissers, and Z. Zhang, “FPGA HLS today: Successes, challenges, and opportunities,” ACM TRETS, vol. 15, no. 4, pp. 1–42, 2022.
- J. Cong and J. Wang, “PolySA: Polyhedral-based systolic array auto-compilation,” in ICCAD, 2018.
- C. Consortium, “Compute express link.” [Online]. Available: https://www.computeexpresslink.org
- “CSD 3000.” [Online]. Available: https://scaleflux.com/products/csd-3000/
- J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, M. Mao, M. a. Ranzato, A. Senior, P. Tucker, K. Yang, Q. Le, and A. Ng, “Large scale distributed deep networks,” in NeurIPS, 2012.
- “Deepspeed.” [Online]. Available: https://github.com/microsoft/DeepSpeed
- Q. Deng, L. Jiang, Y. Zhang, M. Zhang, and J. Yang, “DrAcc: A DRAM based accelerator for accurate CNN inference,” in DAC, 2018.
- F. Devaux, “The true processing in memory accelerator,” in HCS, 2019.
- J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- “Distutils.” [Online]. Available: https://docs.python.org/3.9/library/distutils.html
- J. Do, Y.-S. Kee, J. M. Patel, C. Park, K. Park, and D. J. DeWitt, “Query processing on smart ssds: Opportunities and challenges,” in SIGMOD, 2013.
- Z. Dong, Z. Yao, A. Gholami, M. Mahoney, and K. Keutzer, “HAWQ: Hessian aware quantization of neural networks with mixed-precision,” in ICCV, 2019.
- A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” in ICLR, 2021.
- J. Draper, J. Chame, M. Hall, C. Steele, T. Barrett, J. LaCoss, J. Granacki, J. Shin, C. Chen, C. W. Kang, I. Kim, and G. Daglikoca, “The architecture of the DIVA processing-in-memory chip,” in ICS, 2002.
- J. Duchi, E. Hazan, and Y. Singer, “Adaptive subgradient methods for online learning and stochastic optimization,” Journal of machine learning research, vol. 12, no. Jul, pp. 2121–2159, 2011.
- “Falcon 4109.” [Online]. Available: https://www.h3platform.com/product-detail/overview/25
- A. Farmahini-Farahani, J. H. Ahn, K. Morrow, and N. S. Kim, “NDA: Near-dram acceleration architecture leveraging commodity dram devices and standard memory modules,” in HPCA, 2015.
- M. Gao, J. Pu, X. Yang, M. Horowitz, and C. Kozyrakis, “Tetris: Scalable and efficient neural network acceleration with 3d memory,” in ASPLOS, 2017.
- P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, and K. He, “Accurate, large minibatch SGD: Training imagenet in 1 hour,” arXiv preprint arXiv:1706.02677, 2017.
- B. Gu, A. S. Yoon, D.-H. Bae, I. Jo, J. Lee, J. Yoon, J.-U. Kang, M. Kwon, C. Yoon, S. Cho, J. Jeong, and D. Chang, “Biscuit: A framework for near-data processing of big data workloads,” in ISCA, 2016.
- Y. Gu, X. Han, Z. Liu, and M. Huang, “PPT: Pre-trained prompt tuning for few-shot learning,” in ACL, 2022.
- S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,” in ICLR, 2016.
- S. Han, J. Pool, J. Tran, and W. J. Dally, “Learning both weights and connections for efficient neural networks,” in NeurIPS, 2015.
- M. He, C. Song, I. Kim, C. Jeong, S. Kim, I. Park, M. Thottethodi, and T. Vijaykumar, “Newton: A DRAM-maker’s accelerator-in-memory (AiM) architecture for machine learning,” in MICRO, 2020.
- Y. Huang, Y. Cheng, A. Bapna, O. Firat, D. Chen, M. Chen, H. Lee, J. Ngiam, Q. V. Le, Y. Wu, and z. Chen, “GPipe: Efficient training of giant neural networks using pipeline parallelism,” in NeurIPS, 2019.
- “Hugging Face.” [Online]. Available: https://huggingface.co/docs/hub/index
- H. Jang, J. Jung, J. Song, J. Yu, Y. Kim, and J. Lee, “Pipe-BD: Pipelined parallel blockwise distillation,” in DATE, 2023.
- Y. Jang, S. Kim, D. Kim, S. Lee, and J. Kung, “Deep partitioned training from near-storage computing to DNN accelerators,” IEEE CAL, vol. 20, no. 1, pp. 70–73, 2021.
- L. Jiang, M. Kim, W. Wen, and D. Wang, “XNOR-POP: A processing-in-memory architecture for binary convolutional neural networks in wide-io2 DRAMs,” in ISLPED, 2017.
- S.-W. Jun, M. Liu, S. Lee, J. Hicks, J. Ankcorn, M. King, S. Xu, and Arvind, “BlueDBM: An appliance for big data analytics,” in ISCA, 2015.
- S.-W. Jun, A. Wright, S. Zhang, S. Xu, and Arvind, “GraFBoost: Using accelerated flash storage for external graph analytics,” in ISCA, 2018.
- L. Kang, Y. Xue, W. Jia, X. Wang, J. Kim, C. Youn, M. J. Kang, H. J. Lim, B. Jacob, and J. Huang, “Iceclave: A trusted execution environment for in-storage computing,” in MICRO, 2021.
- S. Kang, J. An, J. Kim, and S.-W. Jun, “Mithrilog: Near-storage accelerator for high-performance log analytics,” in MICRO, 2021.
- Y. Kang, Y.-s. Kee, E. L. Miller, and C. Park, “Enabling cost-effective data processing with smart SSD,” in MSST, 2013.
- Y. Kang, W. Huang, S.-M. Yoo, D. Keen, Z. Ge, V. Lam, P. Pattnaik, and J. Torrellas, “FlexRAM: Toward an advanced intelligent memory system,” in ICCD, 1999.
- L. Ke, X. Zhang, J. So, J.-G. Lee, S.-H. Kang, S. Lee, S. Han, Y. Cho, J. H. Kim, Y. Kwon, K. Kim, J. Jung, I. Yun, S. J. Park, H. Park, J. Song, J. Cho, K. Sohn, N. S. Kim, and H.-H. S. Lee, “Near-memory processing in action: Accelerating personalized recommendation with AxDIMM,” IEEE Micro, vol. 42, no. 1, pp. 116–127, 2022.
- B. Kim, J. Chung, E. Lee, W. Jung, S. Lee, J. Choi, J. Park, M. Wi, S. Lee, and J. H. Ahn, “Mvid: Sparse matrix-vector multiplication in mobile DRAM for accelerating recurrent neural networks,” IEEE TC, vol. 69, no. 7, pp. 955–967, 2020.
- D. Kim, J. Kung, S. Chai, S. Yalamanchili, and S. Mukhopadhyay, “Neurocube: A programmable digital neuromorphic architecture with high-density 3D memory,” in ISCA, 2016.
- H. Kim, H. Park, T. Kim, K. Cho, E. Lee, S. Ryu, H.-J. Lee, K. Choi, and J. Lee, “GradPIM: A practical processing-in-DRAM architecture for gradient descent,” in HPCA, 2021.
- J. Kim, M. Kang, Y. Han, Y.-G. Kim, and L.-S. Kim, “OptimStore: In-storage optimization of large scale DNNs with on-die processing,” in HPCA, 2023.
- D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” ICLR, 2015.
- G. Kirsch, “Active memory: Micron’s yukon,” in IPDPS, 2003.
- P. M. Kogge, “EXECUBE-A new architecture for scaleable MPPs,” in ICPP, 1994.
- G. Koo, K. K. Matam, T. I, H. K. G. Narra, J. Li, H.-W. Tseng, S. Swanson, and M. Annavaram, “Summarizer: Trading communication with computing near storage,” in MICRO, 2017.
- A. Krizhevsky, “One weird trick for parallelizing convolutional neural networks,” arXiv preprint arXiv:1404.5997, 2014.
- Y. Kwon, K. Vladimir, N. Kim, W. Shin, J. Won, M. Lee, H. Joo, H. Choi, G. Kim, B. An, J. Kim, J. Lee, I. Kim, J. Park, C. Park, Y. Song, B. Yang, H. Lee, S. Kim, D. Kwon, S. Lee, K. Kim, S. Oh, J. Park, G. Hong, D. Ka, K. Hwang, J. Park, K. Kang, J. Kim, J. Jeon, M. Lee, M. Shin, M. Shin, J. Cha, C. Jung, K. Chang, C. Jeong, E. Lim, I. Park, J. Chun, and S. Hynix, “System architecture and software stack for GDDR6-AiM,” in HCS, 2022.
- Y. Kwon, Y. Lee, and M. Rhu, “TensorDIMM: A practical near-memory processing architecture for embeddings and tensor operations in deep learning,” in MICRO, 2019.
- J. Lee, J. H. Ahn, and K. Choi, “Buffered compares: Excavating the hidden parallelism inside DRAM architectures with lightweight logic,” in DATE, 2016.
- J. Lee, H. Kim, S. Yoo, K. Choi, H. P. Hofstee, G.-J. Nam, M. R. Nutter, and D. Jamsek, “ExtraV: Boosting graph processing near storage with a coherent accelerator,” pVLDB, vol. 10, no. 12, p. 1706–1717, 2017.
- J. H. Lee, H. Zhang, V. Lagrange, P. Krishnamoorthy, X. Zhao, and Y. S. Ki, “SmartSSD: FPGA accelerated near-storage data analytics on SSD,” IEEE CAL, vol. 19, no. 2, pp. 110–113, 2020.
- S. Lee, S.-h. Kang, J. Lee, H. Kim, E. Lee, S. Seo, H. Yoon, S. Lee, K. Lim, H. Shin, J. Kim, O. Seongil, A. Iyer, D. Wang, K. Sohn, and N. S. Kim, “Hardware architecture and software stack for PIM based on commercial DRAM technology: Industrial product,” in ISCA, 2021.
- Y. Lee, J. Chung, and M. Rhu, “SmartSAGE: Training large-scale graph neural networks using in-storage processing architectures,” in ISCA, 2022.
- S. Li, D. Niu, K. T. Malladi, H. Zheng, B. Brennan, and Y. Xie, “Drisa: A dram-based reconfigurable in-situ accelerator,” in MICRO, 2017.
- J. Lin, L. Liang, Z. Qu, I. Ahmad, L. Liu, F. Tu, T. Gupta, Y. Ding, and Y. Xie, “INSPIRE: In-storage private information retrieval via protocol and architecture co-design,” in ISCA, 2022.
- Y. Lin, S. Han, H. Mao, Y. Wang, and B. Dally, “Deep gradient compression: Reducing the communication bandwidth for distributed training,” in ICLR, 2018.
- I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in ICLR, 2019.
- K. Mai, T. Paaske, N. Jayasena, R. Ho, W. Dally, and M. Horowitz, “Smart Memories: a modular reconfigurable architecture,” in ISCA, 2000.
- V. S. Mailthody, Z. Qureshi, W. Liang, Z. Feng, S. G. De Gonzalo, Y. Li, H. Franke, J. Xiong, J. Huang, and W.-m. Hwu, “Deepstore: In-storage acceleration for intelligent queries,” in MICRO, 2019.
- N. Mansouri Ghiasi, J. Park, H. Mustafa, J. Kim, A. Olgun, A. Gollwitzer, D. Senol Cali, C. Firtina, H. Mao, N. Almadhoun Alserr, R. Ausavarungnirun, N. Vijaykumar, M. Alser, and O. Mutlu, “GenStore: A high-performance in-storage processing system for genome sequence analysis,” in ASPLOS, 2022.
- K. K. Matam, G. Koo, H. Zha, H.-W. Tseng, and M. Annavaram, “GraphSSD: graph semantics aware SSD,” in ISCA, 2019.
- P. Mehra, “Samsung smartssd: Accelerating data-rich applications,” Flash Memory Summit, 2019.
- P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh, and H. Wu, “Mixed precision training,” in ICLR, 2018.
- Microsoft, “Turing-nlg: A 17-billion-parameter language model by microsoft,” 2020. [Online]. Available: https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
- L. Nai, R. Hadidi, J. Sim, H. Kim, P. Kumar, and H. Kim, “Graphpim: Enabling instruction-level pim offloading in graph computing frameworks,” in HPCA, 2017.
- D. Narayanan, A. Harlap, A. Phanishayee, V. Seshadri, N. R. Devanur, G. R. Ganger, P. B. Gibbons, and M. Zaharia, “PipeDream: Generalized pipeline parallelism for DNN training,” in SOSP, 2019.
- D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V. Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro, A. Phanishayee, and M. Zaharia, “Efficient large-scale language model training on GPU clusters using Megatron-LM,” in SC, 2021.
- “NGD systems newport computational storage platform.” [Online]. Available: https://www.ssdcompute.com/Newport-Platform.asp
- “NoLoad computational storage processor.” [Online]. Available: https://www.eideticom.com/products.html
- J. Park, B. Kim, S. Yun, E. Lee, M. Rhu, and J. H. Ahn, “Trim: Enhancing processor-memory interfaces with scalable tensor reduction in memory,” in MICRO, 2021.
- D. Patterson, T. Anderson, N. Cardwell, R. Fromm, K. Keeton, C. Kozyrakis, R. Thomas, and K. Yelick, “A case for intelligent RAM,” IEEE Micro, vol. 17, no. 2, pp. 34–44, 1997.
- J. T. Pawlowski, “Hybrid memory cube (HMC),” in HCS, 2011.
- B. Pudipeddi, M. Mesmakhosroshahi, J. Xi, and S. Bharadwaj, “Training large neural networks with constant memory using a new execution algorithm,” arXiv preprint arXiv:2002.05645, 2020.
- “pybind11.” [Online]. Available: https://github.com/pybind/pybind11
- Z. Qureshi, V. S. Mailthody, I. Gelado, S. Min, A. Masood, J. Park, J. Xiong, C. J. Newburn, D. Vainbrand, I.-H. Chung, M. Garland, W. Dally, and W.-m. Hwu, “GPU-initiated on-demand high-throughput storage access in the BaM system architecture,” in ASPLOS, 2023.
- A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” OpenAI blog, 2019.
- C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” arXiv preprint arXiv:1910.10683, 2019.
- S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He, “ZeRO: Memory optimizations toward training trillion parameter models,” in SC, 2020.
- S. Rajbhandari, O. Ruwase, J. Rasley, S. Smith, and Y. He, “ZeRO-Infinity: Breaking the GPU memory wall for extreme scale deep learning,” in SC, 2021.
- A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” in ICML, 2021.
- J. Ren, S. Rajbhandari, R. Y. Aminabadi, O. Ruwase, S. Yang, M. Zhang, D. Li, and Y. He, “ZeRO-Offload: Democratizing billion-scale model training,” in USENIX ATC, 2021.
- Z. Ruan, T. He, and J. Cong, “INSIDER: Designing in-storage computing system for emerging high-performance drive,” in USENIX ATC, 2019.
- S. Salamat, A. Haj Aboutalebi, B. Khaleghi, J. H. Lee, Y. S. Ki, and T. Rosing, “NASCENT: Near-storage acceleration of database sort on SmartSSD,” in FPGA, 2021.
- S. Salamat, H. Zhang, Y. S. Ki, and T. Rosing, “NASCENT2: Generic near-storage sort accelerator for data analytics on SmartSSD,” ACM TRETS, 2022.
- T. L. Scao, A. Fan, C. Akiki, E. Pavlick, S. Ilić, D. Hesslow, R. Castagné, A. S. Luccioni, F. Yvon, M. Gallé et al., “Bloom: A 176b-parameter open-access multilingual language model,” arXiv preprint arXiv:2211.05100, 2022.
- R. Schmid, M. Plauth, L. Wenzel, F. Eberhardt, and A. Polze, “Accessible near-storage computing with fpgas,” in EuroSys, 2020.
- V. Seshadri, Y. Kim, C. Fallin, D. Lee, R. Ausavarungnirun, G. Pekhimenko, Y. Luo, O. Mutlu, P. B. Gibbons, M. A. Kozuch, and T. C. Mowry, “RowClone: fast and energy-efficient in-DRAM bulk data copy and initialization,” in MICRO, 2013.
- V. Seshadri, D. Lee, T. Mullins, H. Hassan, A. Boroumand, J. Kim, M. A. Kozuch, O. Mutlu, P. B. Gibbons, and T. C. Mowry, “Ambit: In-memory accelerator for bulk bitwise operations using commodity DRAM technology,” in MICRO, 2017.
- S. Shi, X. Chu, K. C. Cheung, and S. See, “Understanding Top-k sparsification in distributed deep learning,” arXiv preprint arXiv:1911.08772, 2019.
- M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism,” arXiv preprint arXiv:1909.08053, 2019.
- M. Singh and B. Leonhardi, “Introduction to the IBM Netezza warehouse appliance,” in CASCON, 2011.
- M. Soltaniyeh, V. Lagrange Moutinho Dos Reis, M. Bryson, X. Yao, R. P. Martin, and S. Nagarakatte, “Near-storage processing for solid state drive based recommendation inference with smartssds®,” in ICPE, 2022.
- J. Song, J. Yim, J. Jung, H. Jang, H.-J. Kim, Y. Kim, and J. Lee, “Optimus-CC: Efficient large NLP model training with 3D parallelism aware communication compression,” in ASPLOS, 2023.
- Storage Networking Industry Association, “What is computational storage?” [Online]. Available: https://www.snia.org/sites/default/files/SSSI/Computational_Storage_What_Is_Computational_Storage_final_PDF.pdf
- X. Sun, W. Wang, S. Qiu, R. Yang, S. Huang, J. Xu, and Z. Wang, “Stronghold: Fast and affordable billion-scale deep learning model training,” in SC, 2022.
- X. Sun, H. Wan, Q. Li, C.-L. Yang, T.-W. Kuo, and C. J. Xue, “RM-SSD: In-storage computing for large-scale recommendation inference,” in HPCA, 2022.
- M. Tan and Q. Le, “EfficientNet: Rethinking model scaling for convolutional neural networks,” in ICML, 2019.
- H. Tang, S. Gan, A. A. Awan, S. Rajbhandari, C. Li, X. Lian, J. Liu, C. Zhang, and Y. He, “1-bit Adam: Communication efficient large-scale training with Adam’s convergence speed,” in ICML, 2021.
- D. Tiwari, S. Boboila, S. Vazhkudai, Y. Kim, X. Ma, P. Desnoyers, and Y. Solihin, “Active flash: Towards energy-efficient, in-situ data analytics on extreme-scale machines,” in FAST, 2013.
- A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is all you need,” in NeurIPS, 2017.
- T. Vogels, S. P. Karimireddy, and M. Jaggi, “PowerSGD: Practical low-rank gradient compression for distributed optimization,” in NeurIPS, 2019.
- A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman, “GLUE: A multi-task benchmark and analysis platform for natural language understanding,” in ICLR, 2019.
- H. Wang, S. Agarwal, and D. Papailiopoulos, “Pufferfish: Communication-efficient models at no extra cost,” in MLSys, 2021.
- J. Wang, L. Guo, and J. Cong, “AutoSA: A polyhedral compiler for high-performance systolic arrays on FPGA,” in FPGA, 2021.
- R. Weiss, “A technical overview of the oracle exadata database machine and exadata storage server,” Oracle White Paper, 2012.
- M. Wilkening, U. Gupta, S. Hsia, C. Trippel, C.-J. Wu, D. Brooks, and G.-Y. Wei, “RecSSD: near data processing for solid state drive based recommendation inference,” in ASPLOS, 2021.
- “Xilinx OpenCL extension.” [Online]. Available: https://xilinx.github.io/XRT/master/html/opencl_extension.html
- W. Xiong, L. Ke, D. Jankov, M. Kounavis, X. Wang, E. Northup, J. Yang, B. Acun, C. Wu, P. P. Tang, G. E. Suh, X. Zhang, and H. S. Lee, “SecNDP: Secure Near-Data Processing with Untrusted Memory,” in HPCA, 2022.
- B. Yang, J. Zhang, J. Li, C. Re, C. Aberger, and C. De Sa, “PipeMare: Asynchronous Pipeline Parallel DNN Training,” in MLSys, 2021.
- D. Zhang, N. Jayasena, A. Lyashevsky, J. L. Greathouse, L. Xu, and M. Ignatowski, “TOP-PIM: throughput-oriented programmable processing in memory,” in HPDC, 2014.
- M. Zhang, Y. Zhuo, C. Wang, M. Gao, Y. Wu, K. Chen, C. Kozyrakis, and X. Qian, “GraphP: Reducing communication for pim-based graph processing with efficient data partition,” in HPCA, 2018.
- S. Zhang, A. E. Choromanska, and Y. LeCun, “Deep Learning with Elastic Averaging SGD,” in NeurIPS, 2015.
- Y. Zhuo, C. Wang, M. Zhang, R. Wang, D. Niu, Y. Wang, and X. Qian, “GraphQ: Scalable pim-based graph processing,” in MICRO, 2019.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

