- The paper introduces ATDS, a novel metric leveraging acoustic pseudo-tokens to predict positive transfer in ASR by mixing target and donor language data.
- Experiments show that supplementing minimal target data with similar high-resource language data, such as Hindi for Punjabi, significantly improves word error rates.
- The approach outperforms existing methods like lang2vec, achieving a strong correlation (r = 0.89) to relative word error rate reduction and demonstrating broad applicability.
Acoustic Pseudo-Tokens for Predicting Positive Transfer in Low-Resource ASR
This paper introduces a method for predicting positive transfer in low-resource ASR by leveraging acoustic pseudo-tokens. It addresses the challenge of adapting multilingual speech models like wav2vec 2.0 XLSR-128 for languages under-represented in pre-training data. The core idea involves supplementing target language data with data from similar, higher-resource donor languages and introducing a novel metric, Acoustic Token Distribution Similarity (ATDS), to select the best donor.
Background on wav2vec 2.0
The wav2vec 2.0 architecture (Figure 1) comprises a convolutional feature extractor, a quantizer, and a transformer attention network [Baevski et al., 2020]. Self-supervised pre-training optimizes the model using a contrastive loss and a diversity loss. The transformer network learns representations useful for fine-grained comparisons of acoustic-phonetic content, encoded as vectors at a rate of 49 Hz. The diversity loss ensures a many-to-many relationship between phonetic categories and these vectors.
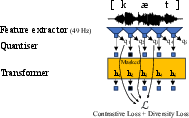
Figure 1: Illustration of the wav2vec 2.0 architecture. Adapted from \newcite{baevski2020wav2vec}
Systematic Study of Pairwise Transfer
The paper investigates whether supplementing target language data with data from another language can improve ASR performance via continued pre-training (CPT). Using Punjabi as the target language, the study compares CPT with 70 hours of Punjabi to a baseline with only 10 hours, and to supplementing the 10 hours with 60 hours of data from eight other Indic languages. The results indicate that adding data from unrelated Dravidian languages or dissimilar Indo-Aryan languages yields no better than baseline performance, while more similar languages improve WERs. Specifically, adding Hindi data approaches the 70-hour Punjabi top-line performance.
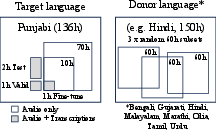
Figure 2: Data selection for transfer experiments
Acoustic Token Distribution Similarity
The authors propose ATDS to measure the similarity between untranscribed speech corpora based on frequencies of recurring acoustic-phonetic sequences. ATDS extends Token Distribution Similarity (TDS) [Gogoulou et al., 2023] and uses wav2seq [Wu et al., 2023] to induce pseudo-tokens from pre-trained speech embeddings. The process involves extracting speech representations, clustering them using k-means, converting cluster indices to characters, deduplicating, and training a subword model to discover frequent sound sequences (Figure 3).
(Figure 3)
Figure 3: Derivation of the Acoustic Token Distribution Similarity (ATDS) measure for predicting positive transfer between two languages resulting from continued pre-training (CPT) of a pre-trained speech model (e.g. XLSR-128).
Analyses using Common Voice Punjabi and Hindi datasets demonstrate that the induced pseudo-tokens exhibit within- and cross-language consistency, corresponding to phoneme labels.
Experimental Results and Analysis
The study evaluates ATDS by comparing its predictions with ASR performance in Indic languages. ATDS is compared against lang2vec and embeddings from a pre-trained spoken language identification model (SpeechBrain). Results indicate that ATDS provides a finer-grained ranking than lang2vec measures and accurately selects Hindi as the most suitable donor. The correlation of ATDS to WERR is r = 0.89, demonstrating its effectiveness.
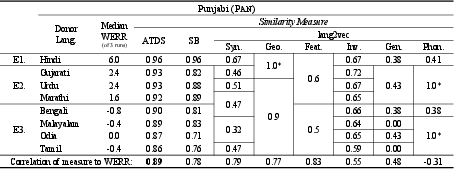
Figure 4: Acoustic Token Distribution Similarity (ATDS) measure between Punjabi and donor language predicts downstream speech recognition performance as measured by relative word error rate (WERR) when fine-tuning the wav2vec 2.0 XLSR-128 model adapted using continued pre-training (CPT) on 10 hours of target and 60 hours of donor language speech.
Further experiments on Galician, Iban, and Setswana validate the generalizability of ATDS. The results show that larger improvements in target language ASR performance are observed when supplementing target language data with data from a more similar language, as measured by ATDS (Figure 5).

Figure 5: Validation of the Acoustic Token Distribution Similarity (ATDS) measure for predicting target language automatic speech recognition (ASR) performance as a result of continued pre-training (CPT) of the wav2vec 2.0 XLSR-128 model using mix target and donor language data.
The family trees of languages studied in the paper are shown in Figure 6.
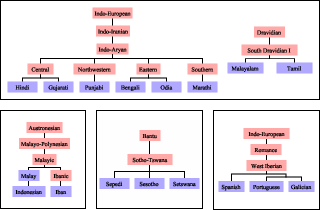
Figure 6: Family trees of the languages studied in this paper. Language families are in red and languages are in blue.
Conclusion
The paper demonstrates that adapting multilingual pre-trained models via continued pre-training, using a mix of target language data and supplemental data from a similar, higher-resource donor language, is effective for low-resource ASR. The proposed ATDS measure accurately predicts positive transfer between donor and target languages, attributed to leveraging the knowledge of the pre-trained model, its inductive biases, training objectives, and the distributions within the candidate datasets. The successful transfer observed in language pairs with significant contact suggests that understanding linguistic and non-linguistic factors that yield high cross-lingual similarity is crucial for developing inclusive speech technologies.