Finding AI-Generated Faces in the Wild
Abstract: AI-based image generation has continued to rapidly improve, producing increasingly more realistic images with fewer obvious visual flaws. AI-generated images are being used to create fake online profiles which in turn are being used for spam, fraud, and disinformation campaigns. As the general problem of detecting any type of manipulated or synthesized content is receiving increasing attention, here we focus on a more narrow task of distinguishing a real face from an AI-generated face. This is particularly applicable when tackling inauthentic online accounts with a fake user profile photo. We show that by focusing on only faces, a more resilient and general-purpose artifact can be detected that allows for the detection of AI-generated faces from a variety of GAN- and diffusion-based synthesis engines, and across image resolutions (as low as 128 x 128 pixels) and qualities.











































































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about telling the difference between real photos of people and faces made by AI. The goal is to spot fake profile pictures used by scammers or bots on big online platforms.
What questions the researchers asked
They focused on a few simple questions:
- Can a computer reliably tell a real face from an AI-made face?
- Will this work across different AI tools (like GANs and diffusion models) and across different image sizes and qualities?
- Is the computer picking up deep, face-related clues (like how a face is structured) instead of shallow “glitches” that are easy to hide?
(Quick definitions:
- GANs: A kind of AI that learns to “draw” things by competing two networks—one generates images, the other tries to spot fakes—until the results look realistic.
- Diffusion models: A newer kind of AI that starts with random noise and learns to “remove” it step by step to make an image, often guided by text prompts.)
How they did it (in everyday terms)
Think of their system like a photo spam filter specialized for faces:
- They collected lots of images: about 120,000 real LinkedIn profile photos and about 105,900 AI-generated images from many popular tools (both GAN-based and diffusion-based).
- They trained a neural network (a computer program that learns patterns) to give each image a score from 0 (likely real) to 1 (likely AI-made). The base of the network is a known model called EfficientNet, which they fine-tuned for this task.
- They kept things realistic:
- They included many different AI tools (so the model wouldn’t overfit to one tool’s “signature”).
- They tested different image sizes and compression levels (like the blurry, squished quality you see after downloading an image many times).
In simple terms: they showed the computer tons of real and AI faces, taught it to spot the difference, and then checked if it could still do this on new, different images.
What they found and why it matters
Here are the key results, stated simply:
- High accuracy on known AI tools:
- With settings tuned so only about 0.5% of real photos get wrongly flagged, the system correctly caught about 98% of AI-made faces from the same tools it trained on.
- Decent accuracy on new AI tools:
- On AI faces from tools it hadn’t seen during training, it caught about 85% at the same strict setting. It did great on some (near 100%) and struggled on others (some much lower), which means adding those newer tools into training would likely improve results.
- Focused on faces, not random images:
- It didn’t falsely call non-face images “AI” (even when those non-face images were AI-generated). This shows the model is really tuned to faces specifically—which is good for catching fake profile photos.
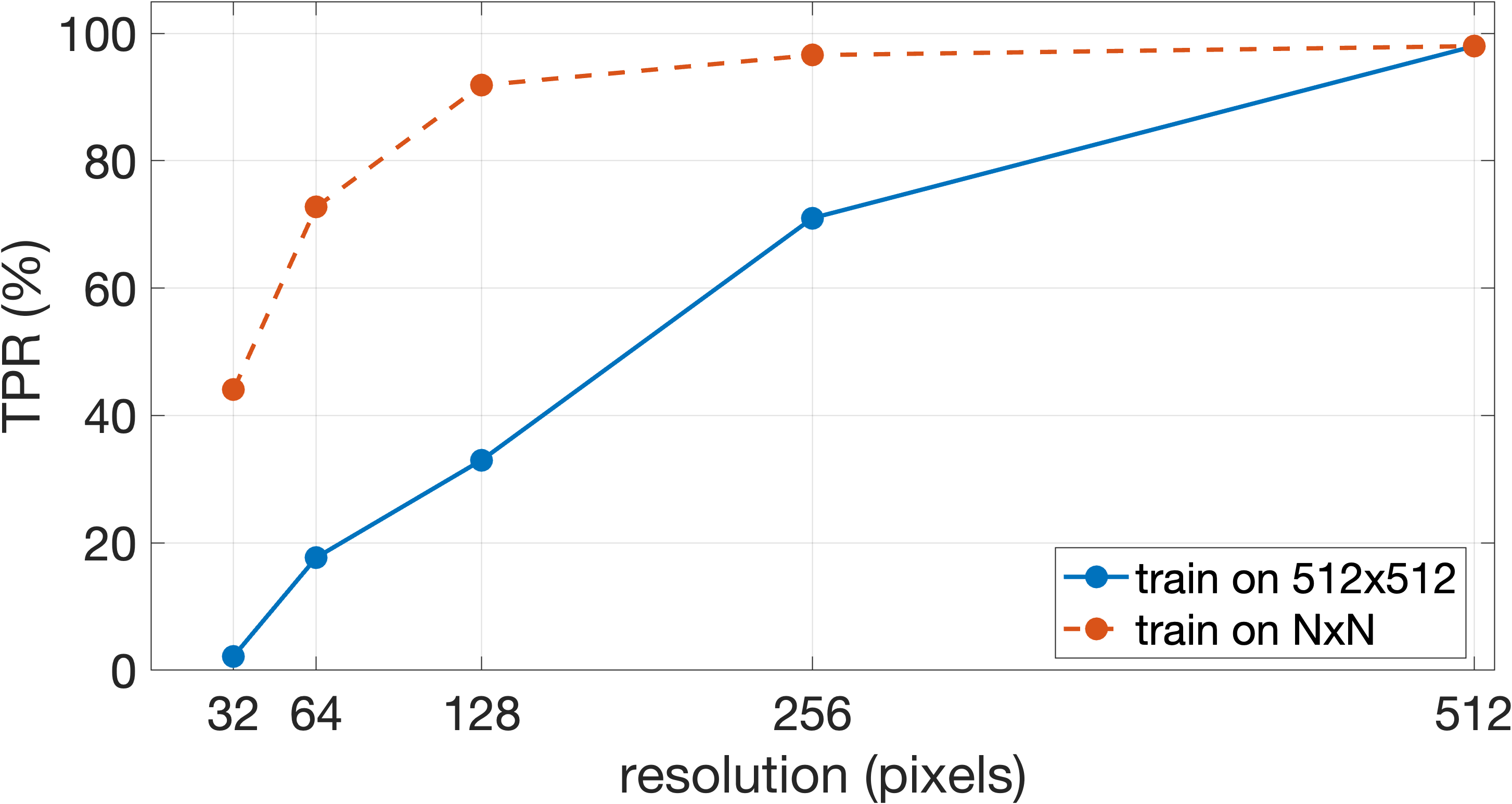
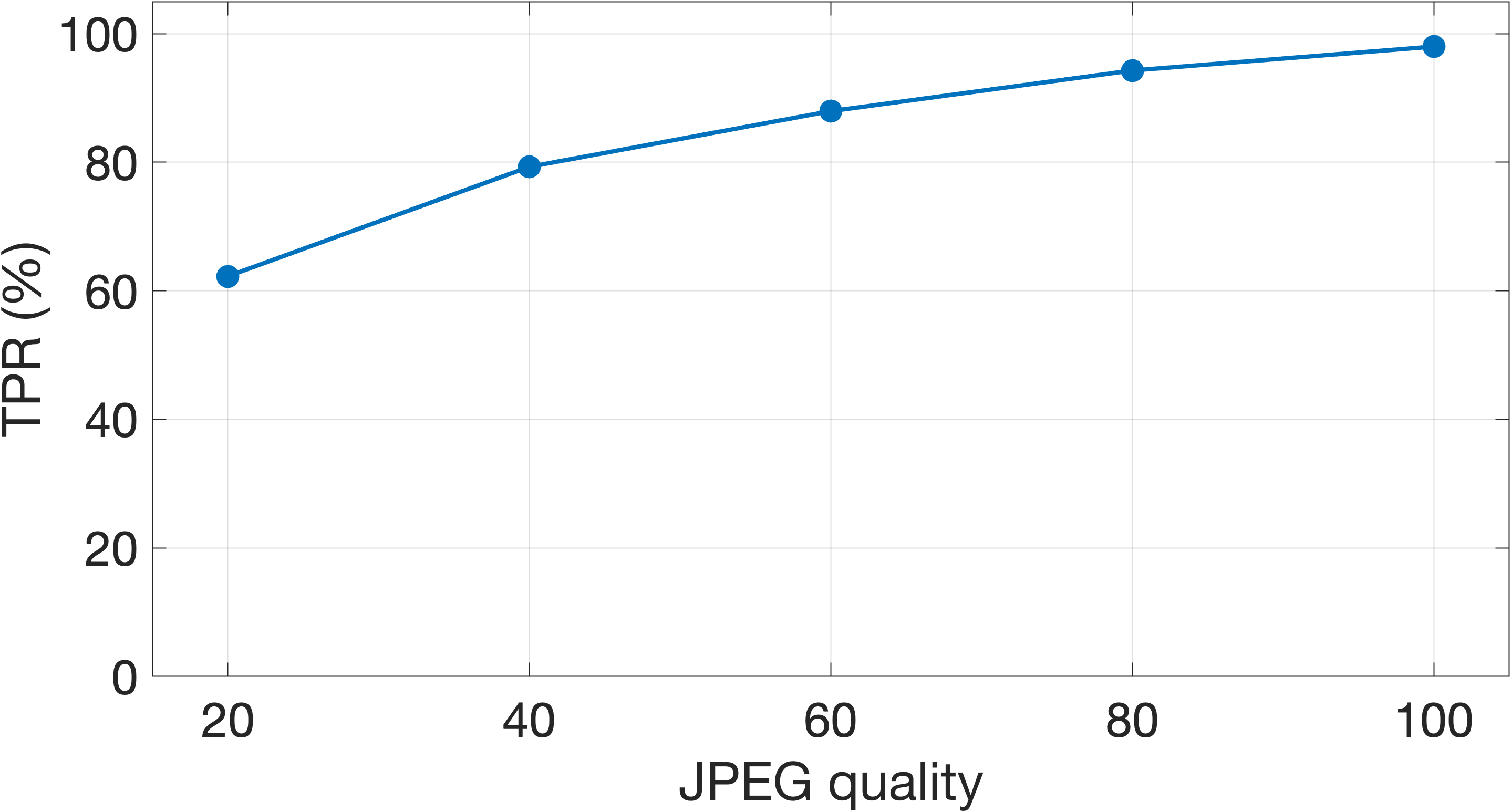
- Works on small and compressed images:
- It still worked well on small images (down to 128×128 pixels), and stayed strong even when images were saved at lower JPEG quality. That suggests it’s not relying on tiny, fragile “noise patterns,” but on more meaningful face features.
- Signs it learned a “face concept,” not a cheap trick:
- When faces were flipped upside down, performance dropped (similar to how humans find upside-down faces harder to read). Also, a method called “integrated gradients” showed the model pays attention mostly to the face and skin regions. Both clues suggest it learned real, face-related structure rather than superficial artifacts.
Why this matters:
- Platforms can better spot fake profile photos used for scams, spam, or misinformation.
- The method is robust to common “laundering” tricks like resizing and recompressing images.
What this could mean going forward
- Helpful, not perfect: This tool is a strong step for catching fake profile photos, especially across many AI image generators and image qualities. Still, some new tools can slip by until the model is retrained with their images.
- It’s an arms race: As detection improves, fake image makers will try new tricks. But keeping up makes faking more costly and difficult for most bad actors.
- Part of a toolkit: No single detector will stop everything. This is best used alongside other checks (like behavior patterns or text analysis) to keep platforms safer.
In short, the researchers built a face-focused “AI fake finder” that works well across many generators, sizes, and qualities, and seems to rely on meaningful face structure—making it a practical and resilient tool for finding AI-generated profile photos in the wild.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Out-of-engine generalization failures: The model’s TPR drops to 19.4% on Midjourney faces (at 0.5% FPR). What specific attributes of Midjourney outputs cause failures, and how much does adding modest amounts of Midjourney data to training recover TPR without inflating FPR?
- Dataset inconsistency and clarity: The paper reports 9,000 Midjourney face images in the table but 1,000 in the text. Which is correct, and how do such inconsistencies affect reproducibility and reported performance?
- Scope mismatch (faces vs non-faces): The classifier fails on AI-generated non-faces (0% TPR). What is the end-to-end performance of a practical two-stage pipeline (face detection + classifier), especially on images with multiple or partial faces?
- Orientation sensitivity: Vertical inversion reduces TPR by ~20 points. How can the model be made invariant (e.g., augmentation, architectural changes), and what is its robustness to other rotations and in-plane/out-of-plane pose variations?
- Pose/occlusion/partial-face robustness: The data emphasize centered, single faces; evaluation on profiles, extreme poses, occlusions (e.g., masks, sunglasses), partial faces, and group photos remains absent.
- Demographic fairness: Although diffusion faces were prompted across 30 demographic groups, the real LinkedIn data distribution is unknown and no per-group error rates are reported. Are TPR/FPR equitable across skin tones, genders, age groups, and intersectional subgroups?
- Background and context confounds: Integrated gradients suggest focus on facial regions, but no controlled experiments isolate background cues (e.g., studio backdrops, shallow DoF). Do background/lighting/retouching artifacts drive classification?
- Real-data ground truth noise: Real images are assumed real based on account activity heuristics. What fraction may still be AI-generated or heavily edited, and how sensitive is the model to such label noise?
- Data/domain transferability: Real images come from LinkedIn profile photos. How does performance transfer to other platforms/domains (e.g., dating apps, other social networks, news sites) and to unconstrained photography?
- Temporal drift and new generators: Performance on newer or rapidly evolving engines (e.g., future Midjourney/Stable Diffusion versions) is unknown. What is the decay rate over time, and what continual-learning or monitoring strategy maintains performance?
- Compression and laundering coverage: Only JPEG quality and resolution are studied. How robust is the model to other real-world pipelines (WebP/AVIF/HEIC, social-media recompression, cropping, rescaling kernels, rotations, blur/sharpen, noise, color edits, filters, skin smoothing, HDR, inpainting/outpainting)?
- Partial/compound synthesis: No evaluation on mixed-content images (e.g., real faces with AI-edited features or AI-generated backgrounds; GAN inversion edits). Can the model detect partially synthesized faces?
- Calibration and deployment metrics: Results are reported at FPR=0.5% with TPR and F1, but without ROC/PR curves, AUROC/AUPRC, calibration error, or confidence intervals. How stable are thresholds and PPV/NPV under realistic base rates?
- Statistical rigor and uncertainty: No variance estimates or confidence intervals are provided across runs/seeds/splits. What is the statistical significance and variability of reported improvements?
- Model architecture and tuning choices: Only scoring layers are trained on top of an EfficientNet-B1 backbone; no comparison to full-finetuning or modern backbones (EfficientNetV2, ConvNeXt, ViT/Swin-v2). Does full-finetuning or newer architectures improve out-of-engine generalization?
- Interpretability beyond saliency: The “semantic-level artifact” hypothesis is supported by inversion sensitivity and integrated gradients, but the concrete facial features remain unspecified. Which factors (e.g., skin microtexture, lighting geometry, facial geometry, teeth/eye artifacts) are causal? Can this be tested via controlled manipulations and concept-based analyses?
- Face vs non-face leakage: Because some real images contain no faces while all AI images used for training contain faces, the classifier may conflate “contains a face” with “AI-generated face.” After enforcing face-cropping/segmentation for both classes, do results hold?
- Resolution-specific training trade-offs: Training at matched lower resolutions improves TPR relative to downsample-then-upsample evaluation. What is the optimal multi-resolution training regime for platforms with heterogeneous input resolutions?
- Per-engine performance diagnostics: The paper aggregates results but only briefly notes per-engine variation. Detailed per-engine confusion, failure mode analysis, and targeted augmentations are needed to understand and address engine-specific weaknesses.
- Data curation impacts: Diffusion face sets were curated to remove failures, potentially biasing the distribution. How does the model perform on uncurated, real-world prompts with failure cases and less controlled outputs?
- Duplicate/overlap controls: There is no explicit discussion of deduplication across training/eval splits (within engines or prompts). Are there inadvertent similarities that inflate performance?
- Multi-face and crowded scenes: The paper focuses on single-face images. How does the system behave on images with multiple faces of mixed provenance (e.g., AI + real), and how should it aggregate per-face decisions?
- End-to-end latency and scalability: No runtime or resource-cost analysis is provided. What are throughput and latency on production hardware, and how do they scale to hundreds of millions of users?
- Adversarial robustness: The paper notes but does not test adversarial attacks. How vulnerable is the model to gradient-based attacks, expected-over-transforms (EOT), spatial attacks, or imperceptible perturbations that preserve photo realism?
- Threshold drift under content shifts: With evolving user behavior and platform policies (e.g., automatic recompression), how often must thresholds be recalibrated, and how does drift affect on-platform precision/recall?
- Code/data release and reproducibility: Real LinkedIn images are private and internal curation details (e.g., prompt lists, seed choices) are not fully specified. What minimal artifacts (synthetic data, code, prompts, seeds) can be released to enable reproducibility?
- Failure analysis for Midjourney: Given the stark underperformance on Midjourney, what specific image characteristics (e.g., shading models, detail synthesis, color statistics) hinder detection, and which targeted augmentations or feature constraints best mitigate this gap?
- Orientation and augmentation strategy: Inversion degrades performance, yet face images can be rotated. Which augmentation policies (rotations, flips, geometric transforms) preserve performance without erasing learned semantics?
- Application boundary: The detector is face-only; detecting AI-generated non-face images (e.g., logos, scenes) is out of scope. What complementary detectors and fusion strategies are needed for broader AI-content detection in user profiles?
- Legal/ethical constraints on real data: The reliance on LinkedIn public photos limits external validation. How can future work construct public, consented, demographically balanced real-face datasets for benchmarking without privacy risks?
Practical Applications
Immediate Applications
Below are concrete, deployable uses that leverage the paper’s detector for AI‑generated faces, along with sectors, possible tools/workflows, and feasibility notes.
- Social platforms and online marketplaces (software, trust & safety)
- Use case: Flag suspicious profile photos during account creation or change; batch scan existing profiles to prioritize reviews for spam/fraud rings.
- Tools/workflows: “AI Face Authenticity Score” service; upload‑time screening SDK; trust & safety triage dashboard with thresholds tuned to ~0.5% FPR and engine‑aware retraining.
- Assumptions/dependencies: Photo contains an upright face; ≥128×128 resolution; generalization varies by engine (e.g., Midjourney lower TPR out‑of‑engine); must be one signal among many with human review.
- Recruiting/HR networks and job boards (software, HR tech)
- Use case: Reduce fake applicant profiles, spam agencies, and impersonation on professional networks.
- Tools/workflows: Profile-photo check at onboarding; periodic re‑scans; integration with identity verification vendors for stepped‑up KYC on high‑risk cases.
- Assumptions/dependencies: Same as above; policy guardrails to avoid automated adverse actions; bias and demographic fairness audits.
- Fintech and banking KYC (finance)
- Use case: Pre‑screen selfie images in remote onboarding to reduce synthetic identity attacks that rely on GAN/diffusion headshots.
- Tools/workflows: Detector embedded before liveness/biometrics; risk‑based routing (e.g., request live capture if score is high).
- Assumptions/dependencies: Not a substitute for liveness/biometrics; adversarial manipulation possible; orientation normalization recommended.
- Dating and social discovery (consumer software)
- Use case: Discourage fully synthetic avatars; surface authenticity warnings to users or to moderation teams.
- Tools/workflows: Upload‑time scoring; user‑facing prompts (“This looks AI‑generated; please verify”); moderation queue prioritization.
- Assumptions/dependencies: Trade‑offs between user experience and false positives; needs clear policy on permitted AI photos.
- Ad networks and brand safety (advertising)
- Use case: Vet ad creatives and advertiser profile images to curb fake business pages and scams leveraging AI faces.
- Tools/workflows: Pre‑flight creative scanner; advertiser account photo verification; partner APIs for agencies.
- Assumptions/dependencies: JPEG compression and typical ad resizing are handled well; creatives without faces won’t be flagged by this model.
- Enterprise security and anti‑phishing (cybersecurity)
- Use case: Identify AI‑generated personas used in spear‑phishing on collaboration tools or executive‑impersonation campaigns.
- Tools/workflows: Browser extension or email‑client plugin that scores avatars in contact cards; SOC alerting for high‑risk personas.
- Assumptions/dependencies: Works only when an avatar/face is present; integrate with other signals (domain age, behavior).
- Media and fact‑checking triage (media, OSINT)
- Use case: Rapid triage of accounts and sources in breaking‑news contexts to prioritize deeper verification.
- Tools/workflows: Batch scanning of source avatars; newsroom dashboard with thresholded risk bins.
- Assumptions/dependencies: Not evidence of intent; must be combined with provenance checks and reporting standards.
- Education platforms and online proctoring (education)
- Use case: Mitigate fake student/TA accounts or marketplace tutors using synthetic profile photos.
- Tools/workflows: Enrollment photo screening; escalations to manual verification for high‑risk matches.
- Assumptions/dependencies: Respect student privacy regulations; clear appeal paths for false positives.
- Healthcare telemedicine portals (healthcare)
- Use case: Reduce fake patient/provider accounts with synthetic profile photos prior to appointments or messaging.
- Tools/workflows: Pre‑registration screening; pair with credential verification for clinicians.
- Assumptions/dependencies: HIPAA/PHI handling and consent; not for diagnosis or biometric identity.
- Developer and platform tooling (software)
- Use case: Offer a hosted API/SDK for AI‑face detection with configurable thresholds and audit logs.
- Tools/workflows: REST API, client‑side SDKs, batch pipelines; scheduled retraining to add new synthesis engines.
- Assumptions/dependencies: Ongoing model updates as generators evolve; logging and privacy-by-design.
Long-Term Applications
These opportunities require further research, scaling, ecosystem coordination, or product development to reach production maturity.
- Cross‑engine generalization and model hardening (software, research)
- Use case: Improve detection on unseen/new engines (e.g., Midjourney) and against adversarial examples.
- Tools/workflows: Continual learning with new engine data; adversarial training; automated orientation normalization; federated updates across partners.
- Assumptions/dependencies: Access to diverse, legal training sets; compute budget; red‑team exercises.
- Video and multi‑modal detection (media, security)
- Use case: Extend to video calls and animated avatars (live deepfakes); combine with audio and liveness signals.
- Tools/workflows: Frame‑level and temporal models; on‑device lightweight inference; fusion with voice/lip‑sync detectors.
- Assumptions/dependencies: Efficient inference to avoid latency; privacy constraints; robust to compression/streaming artifacts.
- Standards and policy integration (policy, industry consortia)
- Use case: Platform policies that require disclosure for AI profile images; risk‑tiered enforcement guided by measured FPR/TPR.
- Tools/workflows: Transparency labels; appeals process; periodic third‑party audits and demographic bias reporting.
- Assumptions/dependencies: Regulatory alignment (e.g., AI transparency rules); cross‑platform interoperability.
- Provenance and watermark fusion (ecosystem, software)
- Use case: Combine detector scores with cryptographic provenance (e.g., C2PA) and watermarks for stronger evidence.
- Tools/workflows: Scoring fusion engine; content‑credentials verification in upload pipelines; policy exceptions for properly attributed AI art.
- Assumptions/dependencies: Adoption of provenance standards; watermarks may be absent or removable.
- Privacy‑preserving and on‑device detection (mobile/edge)
- Use case: Run lightweight models client‑side to pre‑check uploads without sending full images to servers.
- Tools/workflows: Model distillation/quantization; secure enclaves; threshold‑only sharing to the server.
- Assumptions/dependencies: Mobile performance budgets; verifiable on‑device execution; user consent.
- Cross‑platform signal sharing (trust & safety)
- Use case: Share hashed indicators or risk scores for coordinated fake networks across platforms while preserving privacy.
- Tools/workflows: Shared abuse taxonomies; privacy‑preserving matching (e.g., PSI); incident‑response playbooks.
- Assumptions/dependencies: Legal frameworks for data sharing; governance and abuse prevention.
- Fairness, evaluation, and governance (academia, policy)
- Use case: Independent benchmarks to measure performance across demographics, resolutions, and orientations.
- Tools/workflows: Open evaluation suites; bias and calibration audits; standardized reporting (TPR/FPR at fixed thresholds).
- Assumptions/dependencies: Representative real‑image datasets; ethical review boards; community oversight.
- Beyond faces: broader synthetic media detection (software, robotics, e‑commerce)
- Use case: Extend semantic‑artifact approach to bodies, products, or environments used in scams (e.g., fake equipment listings).
- Tools/workflows: Category‑specific detectors trained on semantic cues; layered with fingerprint‑style methods.
- Assumptions/dependencies: New datasets and task‑specific artifacts; careful avoidance of overfitting to low‑level noise.
- Law enforcement and OSINT triage (public sector)
- Use case: Prioritize suspected synthetic personas in investigations of fraud, trafficking, or disinformation networks.
- Tools/workflows: Batch avatar scanning; integration with case management; chain‑of‑custody for forensic review.
- Assumptions/dependencies: Legal authority and safeguards; detector used only for prioritization, not sole evidence.
- End‑user safety assistants (daily life)
- Use case: Consumer plug‑ins that highlight likely AI‑generated faces in profiles or classifieds to prompt caution.
- Tools/workflows: Browser/mobile extensions; privacy‑preserving local inference; clear UX cues and education.
- Assumptions/dependencies: Risk of false reassurance or undue alarm; needs clear messaging about limitations.
Key dependencies and assumptions across applications
- Face presence and orientation: The model targets faces; non‑face AI images won’t be flagged, and vertical inversion significantly reduces TPR. Orientation normalization is recommended.
- Resolution and quality: Robust down to ~128×128 and tolerant to JPEG compression; very low resolutions (≤64×64) degrade performance.
- Generalization: Strong in‑engine performance; variable out‑of‑engine (e.g., low on Midjourney) unless retrained with new data.
- Adversarial risk: Potential vulnerability to intentional evasion; layered defenses and continual updates are required.
- Governance: Use as a risk signal, not a sole enforcement trigger; implement human‑in‑the‑loop review, appeals, bias audits, and transparent policies.
- Privacy and compliance: Ensure lawful collection and processing of profile images; document data retention and user consent.
Collections
Sign up for free to add this paper to one or more collections.