- The paper presents a benchmark that assesses LLMs' ability to understand and evaluate the order of actions in sequential tasks like cooking.
- It employs binary classification and multi-choice questions to test logical sequence adherence and causal reasoning in procedural tasks.
- Results show that while fine-tuning improves performance, LLMs still face a plateau around 70%-80% accuracy in commonsense order reasoning.
STEPS: A Benchmark for Order Reasoning in Sequential Tasks
Introduction
The paper "STEPS: A Benchmark for Order Reasoning in Sequential Tasks" (2306.04441) introduces a novel benchmark designed to evaluate the capacity of LLMs to reason about the order of operations in sequential tasks. Actions and processes, such as cooking or manufacturing, are often represented in sequences and typically recorded as text. The sequence in which these actions are performed is crucial for successful task execution, particularly when executed by robots or AI agents. This benchmark evaluates the ability of LLMs to reason about step order, leveraging two subtask settings. The first involves determining the rationality of a given next step within a recipe, while the second requires selecting the correct step from multiple choices.
The benchmark is based on commonsense reasoning, a field where LLMs face challenges in zero-shot and few-shot learning contexts. The paper demonstrates that current prompting methods markedly lag behind tuning-based approaches in effectiveness for these tasks. The dataset associated with the benchmark is publicly available, aimed at enhancing research in this domain.
Methodology
The benchmark involves two distinct task settings — classification and multi-choice question formats. The Classification Setting is a binary classification task whereby LLMs evaluate whether a given step is a plausible next step based on preceding steps within a recipe. This process is framed as identifying whether the current action logically follows from the prior actions.
The Multi-Choice Question Setting requires LLMs to select the correct next step from two options, relying on causal language modeling techniques. It evaluates the model's ability to discern the correctness of action sequences in the context of preceding steps, presenting a challenge in terms of logical sequence adherence.
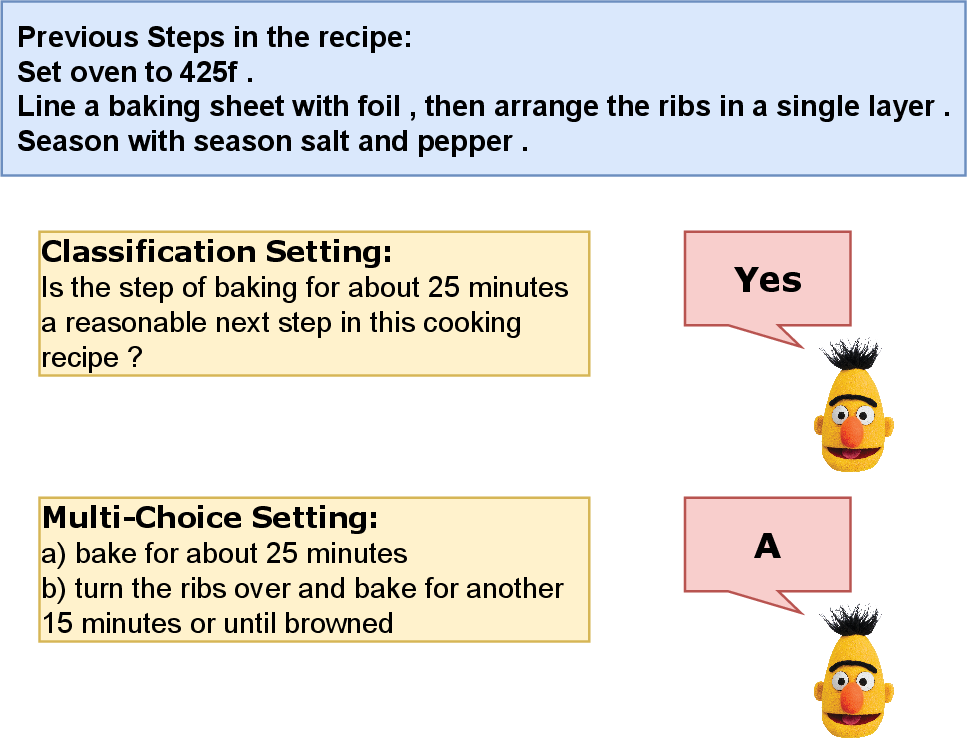
Figure 1: Illustration of two subtask settings of the proposed benchmark.
Dataset Construction
The benchmark utilizes a robust and curated dataset derived from the Food.com recipes, collected over 18 years. Recipes are processed to filter those with four to ten action steps, ensuring adherence to model input constraints. The classification dataset constructs true and false samples from these recipes, framing them as sequences and candidate steps. For multi-choice tasks, samples are structured as tuples, juxtaposing correct steps with randomly selected alternatives.
Evaluation
Baselines
The experiments involve evaluating various LLM influences, including GPT-2, OPT, and BLOOM models, through zero-shot, few-shot, and tuning-based methods. Architectural details such as parameter size, layer numbers, and embeddings are systematically recorded to illustrate the models' conditions during testing.
Evaluation Setting
Different strategies were employed in assessing models' performance on classification and multi-choice tasks. Classification Evaluation utilized zero-shot to few-shot in-context learning, capturing accuracy through sensitivity and specificity metrics. Multi-Choice Question Evaluation relied on language modeling perplexity as a scorer, a metric aligned closely with the pre-training objectives of these models.
Results
Classification results highlighted the challenges faced by LLMs in the proposed tasks, showcasing a noticeable performance increase when incorporating in-context learning methodologies. Fine-tuning consistently resulted in the highest performance. In multi-choice tasks, results demonstrated adherence to scaling laws across LLMs, showing progressively better accuracy with model size increments. Evaluations signal a potential performance ceiling around 70%-80%, suggesting inherent limitations in current LLM designs concerning commonsense reasoning without explicit external commonsense knowledge incorporation.
Conclusions
The STEPS benchmark emerges as a pivotal tool for evaluating LLMs' sequential reasoning capabilities in commonsense tasks. While demonstrating that current models approach a performance plateau when relying solely on large-scale self-supervised learning, the benchmark paves the way for future exploration into integrated commonsense databases and sophisticated reasoning techniques like chain-of-thought prompting to overcome existing limitations. The results provide insights into the models' inherent difficulties in seamlessly understanding and predicting ordered task sequences without explicit, articulated reasoning pathways or external knowledge resources.