- The paper introduces the BAD dataset and BADNet, a deep-learning approach leveraging bystander reactions to improve robot failure detection.
- It employs a CNN architecture adapted from AlexNet with multiple labeling strategies, achieving over 90% precision in predicting failures.
- The study demonstrates the practical impact of using real-world human responses to enhance error detection in Human-Robot Interaction.
The Bystander Affect Detection (BAD) Dataset for Failure Detection in HRI
Introduction
The paper details the creation of the Bystander Affect Detection (BAD) dataset, designed to enhance failure detection in Human-Robot Interaction (HRI) by leveraging bystander reactions. The use of bystander cues, such as confusion or amusement, as data inputs for models predicting robot failure, presents a novel method aimed at improving the interaction capabilities of robots. The dataset comprises webcam videos capturing human reactions to 46 stimulus videos of both human and robot task failures, collected from 54 participants. The paper also introduces BADNet, a deep-learning model tested on this dataset, achieving precision levels exceeding 90%.
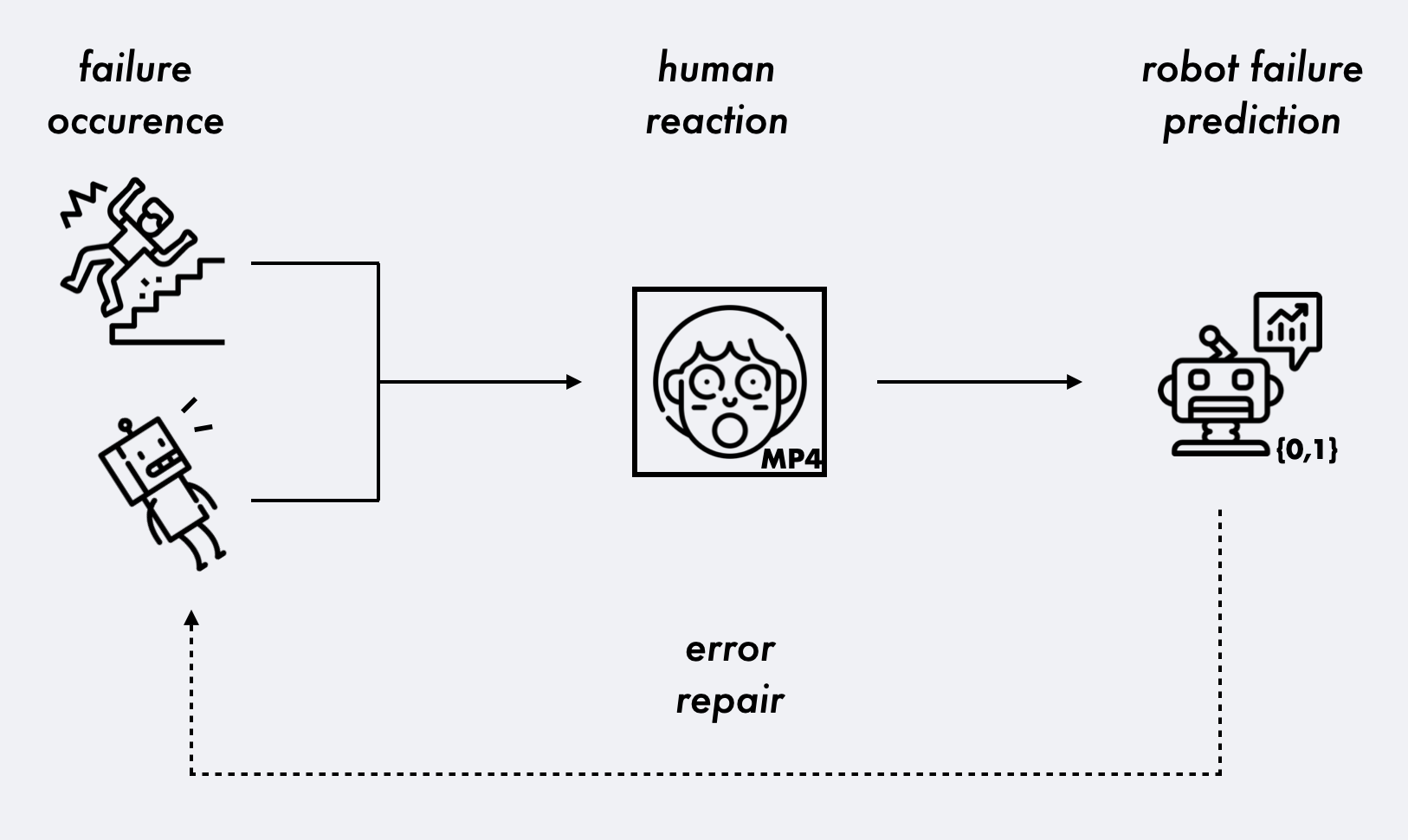
Figure 1: Schematic overview of interaction intelligence through bystander response. A failure occurs (left), leading to a human reaction (center), which is used as data input for failure prediction from the robot (right).
Dataset Collection and Characteristics
Methodology
The BAD dataset was acquired through online surveys, where participants reacted to video stimuli depicting errors or successes. The reactions, captured via participants' webcams, come from a diverse set of demographics, reflecting variations in cultural and experiential backgrounds. The quality of video data, inherent to the naturalistic setting, ensures a spectrum of conditions ranging from lighting variations to video quality.
Observations and Phenomena
Reactions captured include multimodal expressions—facial changes, head movements, and vocalizations. Other factors noted include humor, inter- and intra-participant variability, and the anticipation of errors based on the predictability of failure events.

Figure 2: Top to bottom, left to right: stills taken at 2-second intervals from a reaction video in the BAD dataset.
BADNet for Failure Detection
Model Architecture
BADNet utilizes a convolutional neural network (CNN) architecture adapted from AlexNet. It processes sequential RGB frames from reaction videos, outputting a prediction of failure occurrence. The model is light, containing only 50,674 trainable parameters, a size small enough to allow for deployment in resource-constrained environments.
Data Labeling Strategies
Three labeling methods were employed: manual, failure-vs-control (FvC), and failure-time (FailT), each affecting model training outcomes. Manual labeling involved direct human identification of reactions, FvC used ground-truth comparison between failure and control videos, and FailT differentiated pre- and post-failure segments within video reactions.
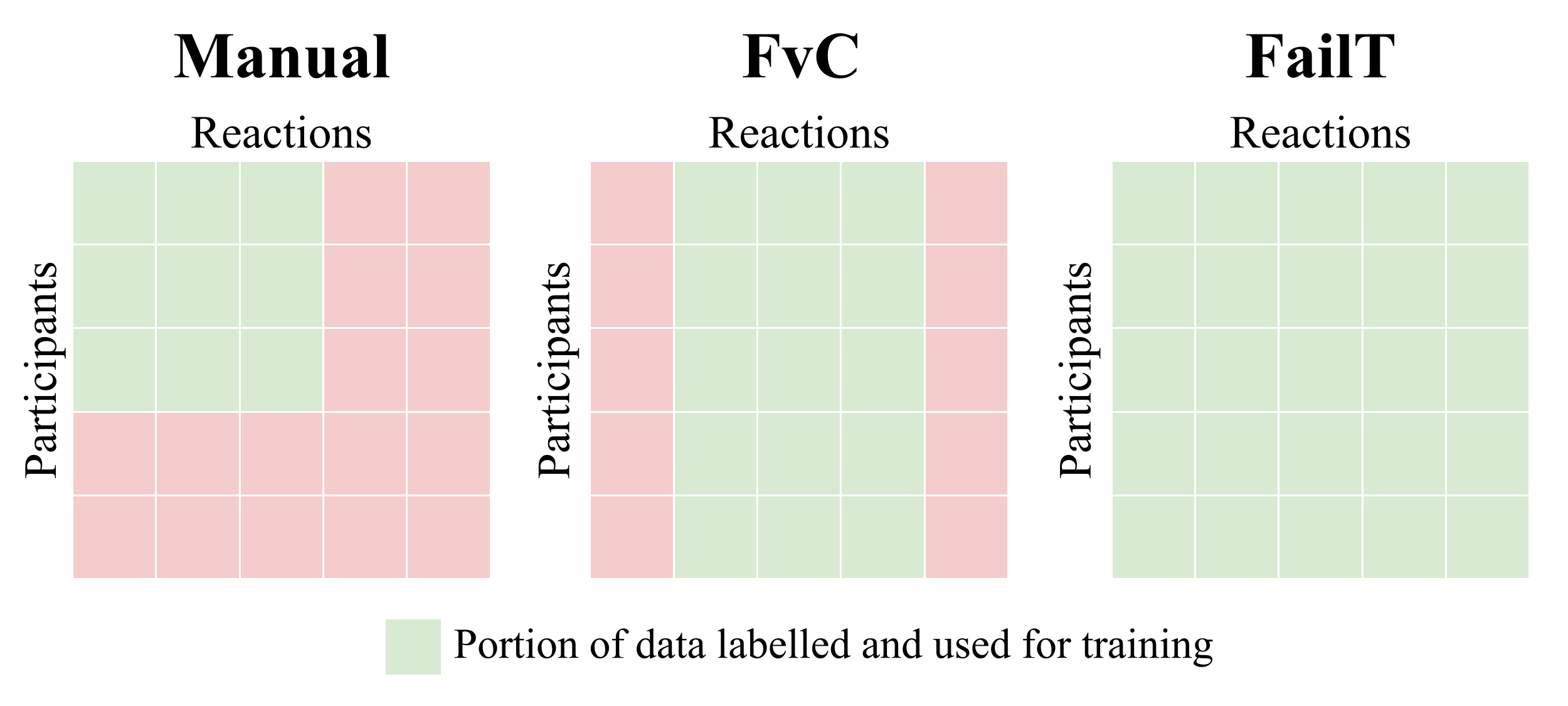
Figure 3: Visual representation of the different labeling methods and the corresponding portion of the total dataset used for training.
The model demonstrates strong performance across various labeling strategies, particularly in terms of precision, recall, and F1-score, with performances exceeding 90%. Notably, the FvC strategy exhibited superior generalization capabilities with unseen participants, indicating a promising direction for future robustness enhancements.
(Table 1)
Table 1: BADNet model performance summary. Summary across different labeling strategies with precision, recall, and F1 measures.
Discussion
Practical Implications
The use of bystander reactions introduces a scalable and efficient method to enhance robot error detection systems. The data collection leverages an 'in-the-wild' methodology, providing a more realistic basis for model training and subsequent application in real-world scenarios.
Limitations and Challenges
While the online setting for data capture introduces variability conducive to robust models, it also presents challenges such as inconsistent video quality. Additionally, the dataset's demographic skews and the model's current inability to distinguish false positives highlight areas for future improvement.

Figure 4: Detection cases for BADNet. The ground truth is given by whether failure occurred (FAIL) or not (NO FAIL), but the model inputs are bystander reactions.
Conclusion
The BAD dataset and BADNet model contribute significant advances to the recognition and exploitation of social cues in robotic systems for failure detection. These resources open avenues for further research in enhancing robot-human interactions, specifically within the domain of error perception and correction.
This research highlights the dataset's role in providing unique insights into bystander reactions and its application potential for developing high-precision failure detection models. Future research directions might explore multimodal data integration, expanding datasets, and refining model architectures for broader demographic applicability.
The promising results and methodologies established by this study furnish a foundational basis for advancing perceptual capacities in autonomous robotic systems, reinforcing the value of leveraging social dynamics within the framework of machine learning and artificial intelligence.