- The paper introduces a statistical framework using LMEMs and GLRTs to model inherent nondeterminism in ML evaluation.
- It decomposes variance components to assess hyperparameter sensitivity and reliability across diverse data conditions.
- Empirical case studies reveal that state-of-the-art gains may be non-robust and affected by data and parameter interactions.
Towards Inferential Reproducibility in Machine Learning Research
Introduction
This work addresses a significant concern in machine learning evaluation: the impact of non-determinism and measurement noise on the reliability and interpretability of reported performance metrics. Unlike the common practice of attempting to eliminate or strictly control sources of randomness to enable exact replication, the authors emphasize the inherent nondeterminism at implementation, algorithmic, and data levels, and argue for a principled statistical framework that quantifies, decomposes, and conditions on these noise sources when testing for performance differences. By leveraging linear mixed effects models (LMEMs), generalized likelihood ratio tests (GLRTs), and variance component analysis (VCA), the paper introduces a methodology for analyzing performance comparisons, robustness, and reliability in a way that yields inferences valid beyond singular model instances.
Statistical Framework for Reproducibility Analysis
Rationale
Empirical results in modern machine learning are persistently affected by nondeterministic factors. These include randomness at the implementation level (e.g., non-deterministic GPU computation, effect of low-level libraries), algorithmic variations (hyperparameters, architectures), and data-level randomness (preprocessing, splits, annotator variance). Contrary to the dominant paradigm of "training reproducibility" as strict duplication (e.g., fixed-seed, frozen environment), the paper asserts that this mindset restricts insight to isolated configurations and neglects both irreducible nondeterminism and critical data/parameter interactions.
Linear Mixed Effects Models
The proposed methodology employs LMEMs to appropriately model the hierarchical, repeated, and clustered structure of evaluation data in typical machine learning experimentation. LMEMs naturally allow the decomposition of variance into fixed effects (e.g., model type, hyperparameter value) and random effects (e.g., test example, run seed), calibrating hypothesis tests for system comparisons under realistic, non-i.i.d. settings:
Y=Xβ+Zb+ϵ,
where X encodes fixed effects, Zb specifies random effects (e.g., per-test example or per-run deviations), and ϵ is residual error. The random effects are modeled as Gaussian with specified covariances, and the structure of the model can flexibly reflect the experimental design (fully crossed, nested, or missing data).
Generalized Likelihood Ratio Testing
GLRTs are performed between nested LMEMs to assess the significance of performance differences between competing systems. The null model assumes no system effect on mean performance; the alternative allows system-dependent means (and potential data/parameter interactions):
- Null: Y=β+bs+ϵ
- Alternative: Y=β+βc⋅Ic+bs+ϵ
Extensions allow inclusion of data covariates (e.g., readability, frequency) and their interactions with system or hyperparameter indicators. Inference is made by comparing the likelihoods (ℓ0,ℓ1) of the two models via the test statistic λ=ℓ0/ℓ1, with small values evidencing significant differences.
A notable capability afforded by LMEM-based testing is conditioning inference on valued or categorical properties of the input data (e.g., readability scores, word rarity), as well as interaction terms for system × data or hyperparameter × data. This allows more granular performance analysis, facilitating conclusions about robustness or gains in certain data regimes.
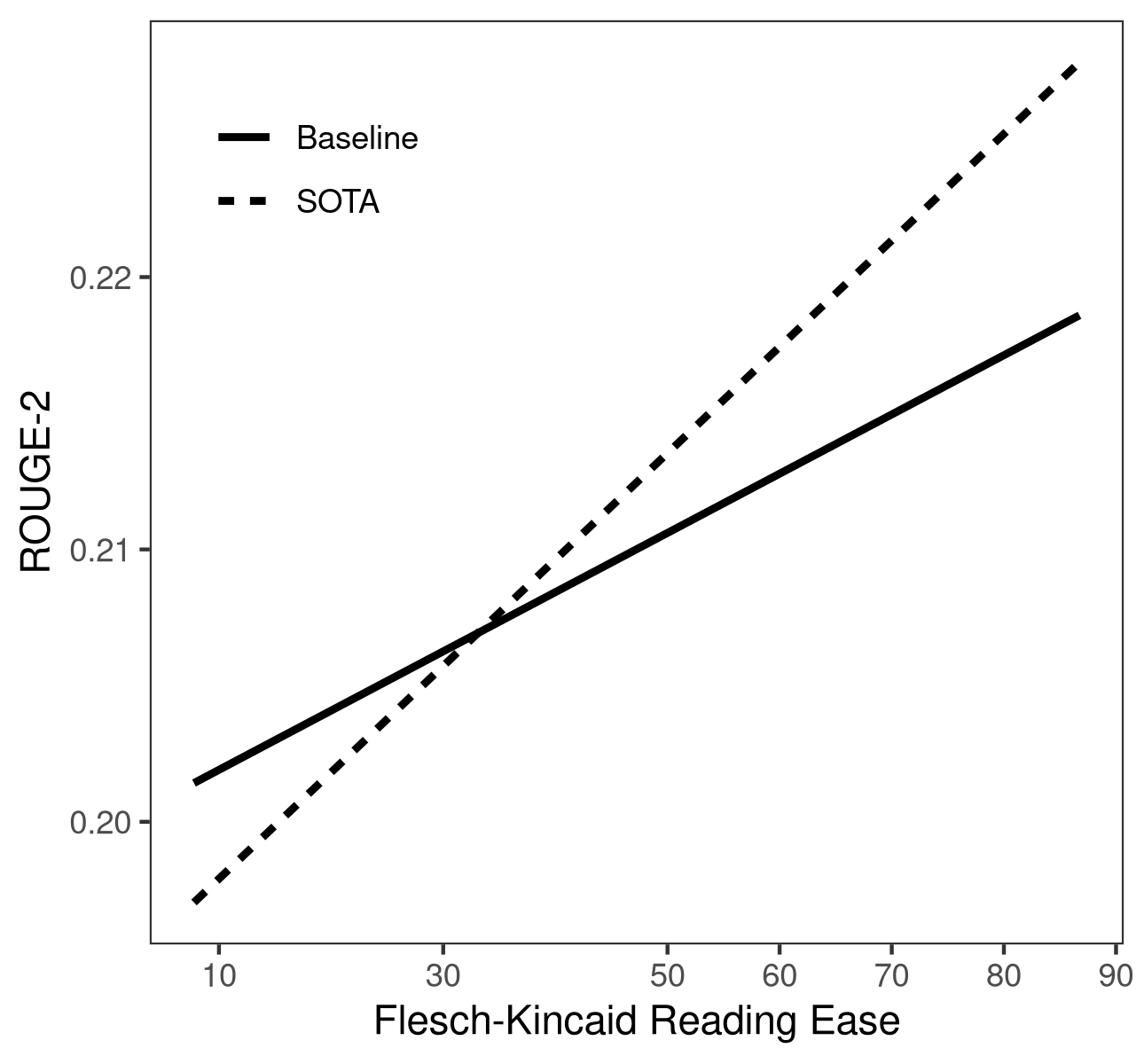
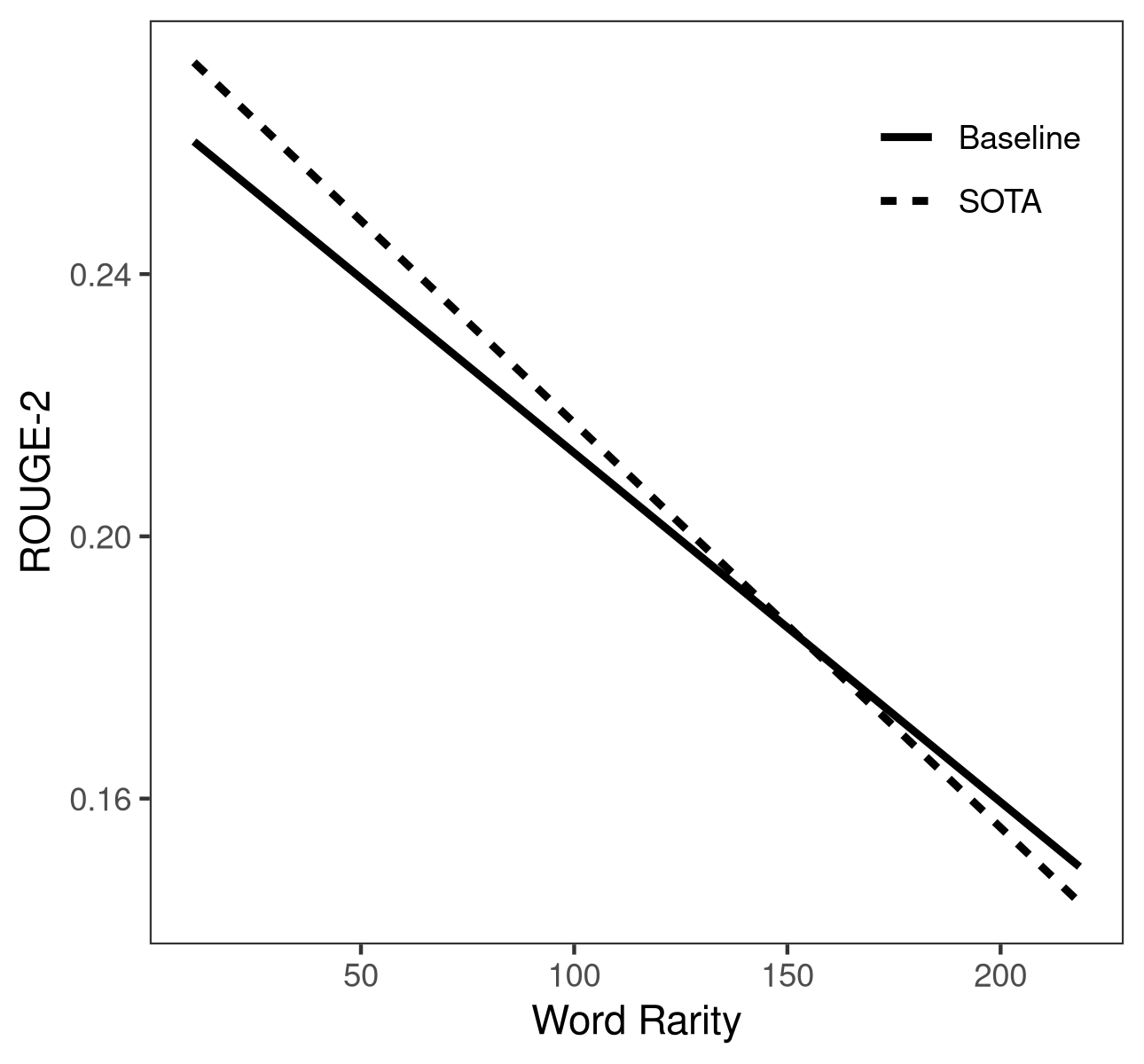
Figure 1: Interaction of Rouge-2 of baseline (solid) and SOTA (dashed) with readability (left) and word rarity (right).
Variance Component Analysis and Reliability
The variance component analysis (VCA) partitions observed score variance into interpretable components (sentence, regularization, residual, etc.). This decomposition permits identification of dominant sources of variance, detection of hyperparameter sensitivity, and assessment of reliability via an intra-class correlation coefficient (ICC):
φ=σobject2+σΔ2σobject2
where σobject2 is variance attributable to the objects of measurement (e.g., test examples), and σΔ2 pools error and facet variances. The reliability coefficient φ provides a summary measure of whether observed score variability is dominated by genuine systematic differences (e.g., between examples) versus contingent randomness.
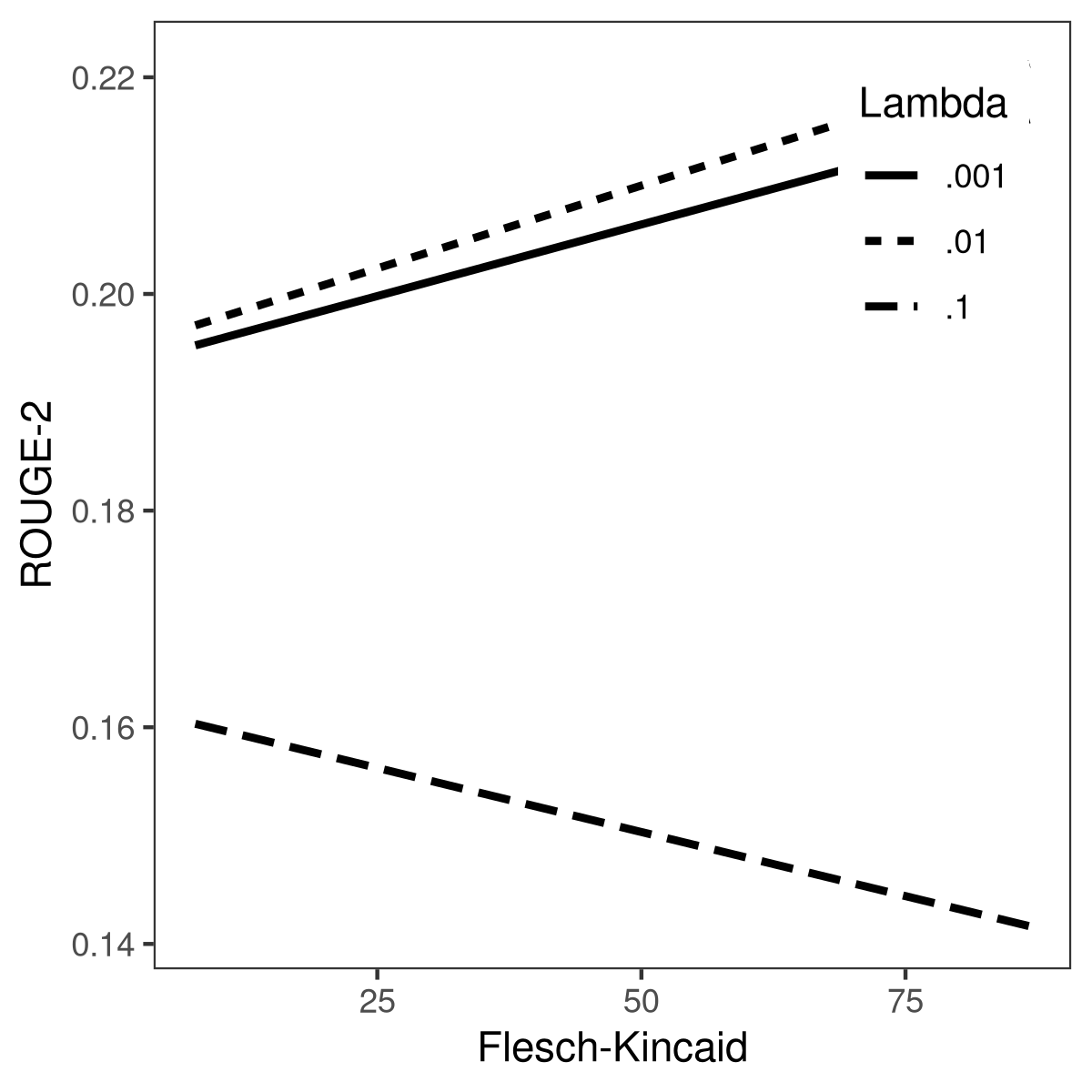
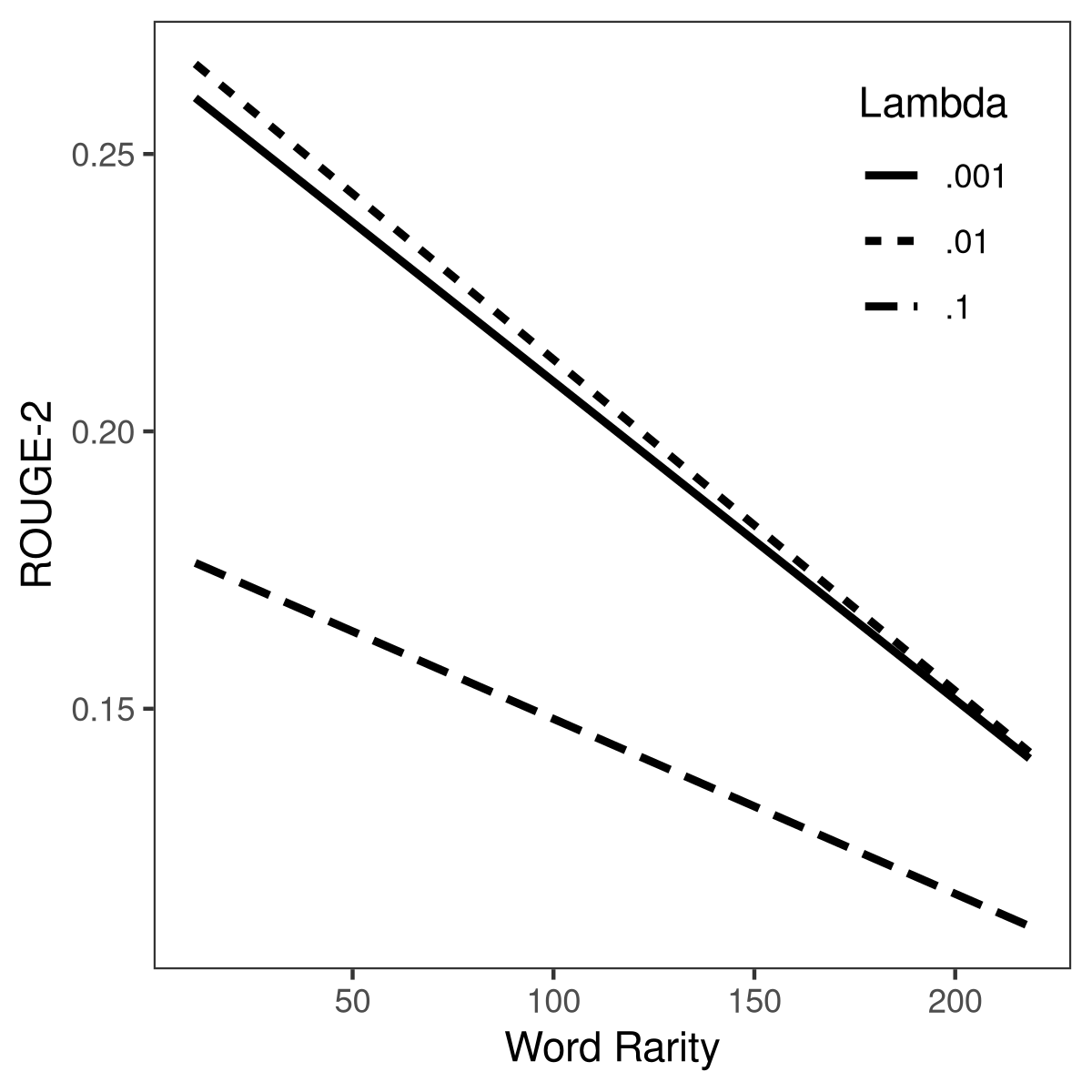
Figure 2: Interaction of Rouge-2 of SOTA for different values of regularization parameter λ with readability (left) and word rarity (right).
Empirical Case Study: Text Summarization with BART+R3F
The statistical approach is demonstrated in a detailed case study involving SOTA text summarization (BART+R3F), compared to a BART-large baseline on the CNN/DailyMail and RedditTIFU datasets.
- Replication under controlled, paper-specified settings confirms statistical significance in SOTA improvements; however, the standardized effect sizes are small, indicating the practical impact is limited.
- When conditioning on data properties (readability, word rarity), performance improvements over baseline are observed primarily for easy-to-read or common-word inputs.
- Under broader meta-parameter variation, the dominance of SOTA is reversed: baseline outperforms SOTA significantly, indicating lack of robustness to hyperparameter settings.
- VCA reveals that the regularization parameter λ accounts for the majority of performance variance in SOTA, while other sources (random seed, noise distribution) have negligible effect. The ICC-based reliability coefficient drops below levels considered "good" reliability under standard guidelines.
Notably, on the RedditTIFU dataset, the previously reported improvements do not generalize under alternative test splits, further underscoring the brittleness of SOTA gains when exposed to new data regimes.
Comparison with Other Approaches
The methodology introduced here stands in contrast to prior reproducibility analyses merely reporting means/confidence intervals or single coefficient measures of variation. While ANOVA-based VCA has appeared in retrieval and AutoML, this work generalizes by explicitly allowing for arbitrary sources of variance and conditional data interactions. The LMEM framework unifies special-case significance tests and accommodates missing data, unbalanced design, and complex experiment structure—facilitating robust, interpretable inference. Furthermore, the proposed reliability assessment is more nuanced and actionable than narrow significance or point estimates, connecting closely to classical measurement theory.
Practical Implications and Theoretical Contributions
The paper's framework has wide-ranging implications:
- Model Evaluation: Statistical inference about algorithmic improvements can be made robust to both inherent and design-driven noise, avoiding overstatements based on isolated lucky runs or idiosyncratic data subsets.
- Hyperparameter Sensitivity: Key hyperparameters (e.g., regularization coefficients) can be identified as bottlenecks to generalizable performance, and results can be appropriately caveated.
- Data-centric Analysis: The conditional significance analysis makes explicit whether advances are broadly applicable or restricted to specific input regimes.
- Experiment Reporting: Reuse of meta-parameter tuning data is encouraged, maximizing information generated in large-scale experimentation.
- Research Credibility: The quantification of reliability via ICC supports decisions regarding the trustworthiness of reported system comparisons, supporting ongoing efforts for transparency and empirical robustness.
Future Directions
Potential future work includes the application of the inferential reproducibility methodology to larger collections of models and datasets, integration with AutoML pipelines to dynamically report reliability alongside performance, and the development of standardized reporting guidelines based on ICC thresholds and VCA diagnostics. Additionally, further methodological advances could include accommodating non-Gaussian error structures, heteroscedasticity, and more elaborate covariance structures in LMEMs, as well as the expansion to causal inference scenarios.
Conclusion
This paper advances the methodology for empirical machine learning evaluation by proposing that measurement noise and inherent nondeterminism should be modeled, not merely suppressed, to enable meaningful inference beyond isolated system-dataset pairs. The adoption of LMEMs, GLRTs, and VCA, together with reliability coefficients, yields a principled and extensible approach to assessing system comparisons, robustness, and generalizability. The empirical case study clearly illustrates that performance gains often lack robustness to data and parameter variation, and that careful variance decomposition is essential to credible empirical claims. This work provides the foundation for more reliable and interpretable machine learning research, with implications for reproducibility standards, experimental practice, and trustworthy AI deployment.