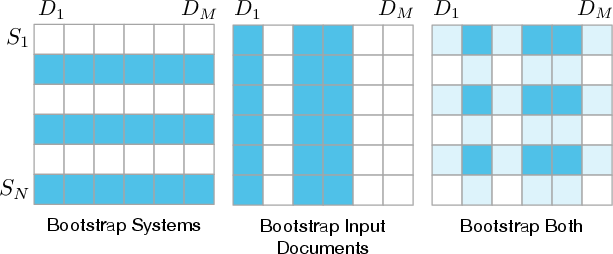
- The paper introduces a robust resampling framework that quantifies metric uncertainty using bootstrapping and permutation tests.
- The methodology employs Boot-Both and Perm-Both schemes to capture variability across systems and document inputs.
- Results reveal that common metrics like ROUGE may yield ambiguous rankings, urging careful interpretation in evaluations.
Statistical Evaluation of Summarization Metrics via Resampling: Uncertainty Quantification and Hypothesis Testing
Introduction
The evaluation of automatic summarization metrics has traditionally relied on reporting correlation coefficients—typically Pearson, Spearman, or Kendall—between metric scores and human judgments. However, the field has lacked rigorous quantification of the statistical uncertainty surrounding these estimates and systematic methods to compare two metrics' correlation with human ratings. This paper addresses both deficiencies by adapting resampling techniques—specifically, bootstrapping and permutation tests—to the estimation of confidence intervals (CIs) and the assessment of statistical significance in metric comparison. The analysis uncovers substantial epistemic uncertainty in metric correlations and reexamines frequently held assumptions regarding metric reliability.
Preliminaries: Metric Correlation Structures
Evaluation metrics X (e.g., ROUGE, BERTScore, QA-Eval, etc.) are compared to a reference Z (typically, human judgments) through system-level (Sys) or summary-level (Sum) correlations. Both metrics compute correlation over a matrix X∈RN×M and Z∈RN×M of metric and reference judgments for N systems and M documents:
- Sys(X,Z)=Corr({(M1j∑xij,M1j∑zij)}i=1N)
- Sum(X,Z)=M1j∑Corr({(xij,zij)}i=1N)
Confidence Interval Estimation
Parametric methods such as the Fisher transformation are problematic here due to their assumption of normality—a property empirically shown to be violated in summarization data. The alternative is nonparametric bootstrapping, with three distinct matrix sampling schemes:
Empirical evaluation demonstrates that Boot-Both produces CIs with coverage closest to the nominal rate when applied to held-out data partitions, justifying its use for downstream generalization.
Hypothesis Testing
While confidence interval overlap is informative, formal significance testing is required for metric discrimination. The canonical test in MT—Williams’ test—depends on normality and exhibits vanishing statistical power at realistic summarization correlation levels (r∼0.3−0.6), making it ill-suited here.
Nonparametric permutation testing is introduced with three permutation methods (analogous to the bootstrap methods) for creating exchangeable samples under the null. Perm-Both, which permutes individual entries, is most suitable for generalizing to new systems and document sets.
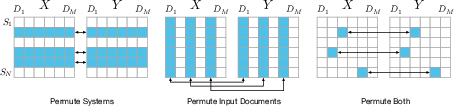
Figure 2: Permutation methods for system (rows), input (columns), or individual summary swaps. Perm-Both is the least restrictive.
Simulation results show that Perm-Both achieves the highest statistical power, successfully distinguishing artificially degraded metrics from true metric baselines—outperforming both Boot-Both and Williams’ test, especially at realistic summary-level system correlations:
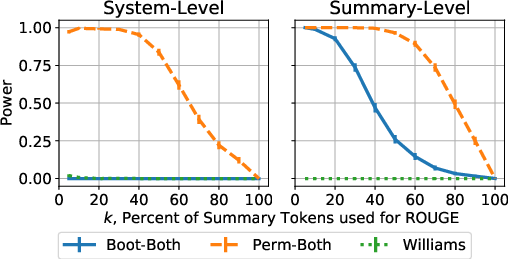
Figure 3: Power curves for Boot-Both, Perm-Both, and Williams’ test at system and summary level. Perm-Both dominates in statistical power for realistic effect sizes.
Empirical Findings
Uncertainty is Substantial
Application of Boot-Both–derived confidence intervals to GT-annotated evaluation datasets (TAC'08, CNN/DM Fabbri et al., Bhandari et al.) reveals that typical CIs for metric-to-human correlations are wide, particularly at the system level (e.g., ROUGE-2 system-level Kendall's τ CI: [−0.09,0.84] on CNN/DM). The interval width translates into ranking error; e.g., the ROUGE-2 interval covers between 9% and 54% incorrect system orderings versus human judgments, depending on where the true score lies in the CI:
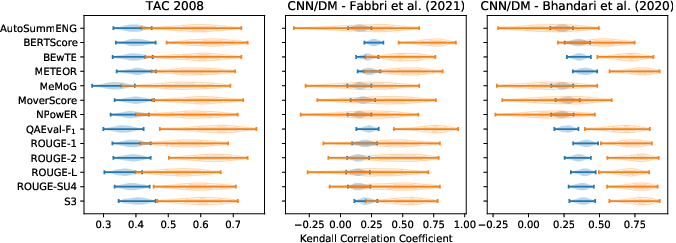
Figure 4: 95% confidence intervals for summary-level (blue) and system-level (orange) Kendall's τ correlations on TAC'08 and two CNN/DM datasets.
Comparative Significance across Metrics
Despite wide CIs and substantial overlap, permutation-based hypothesis testing (Perm-Both) does reveal statistically significant performance disparities in select settings. Notably, QA-Eval and BERTScore produce significantly higher correlations with human ratings than all other metrics for some datasets (TAC'08, CNN/DM datasets with Fabbri et al. annotator sampling), whereas traditional lexical metrics very rarely outperform ROUGE under strong error controls (Bonferroni correction):
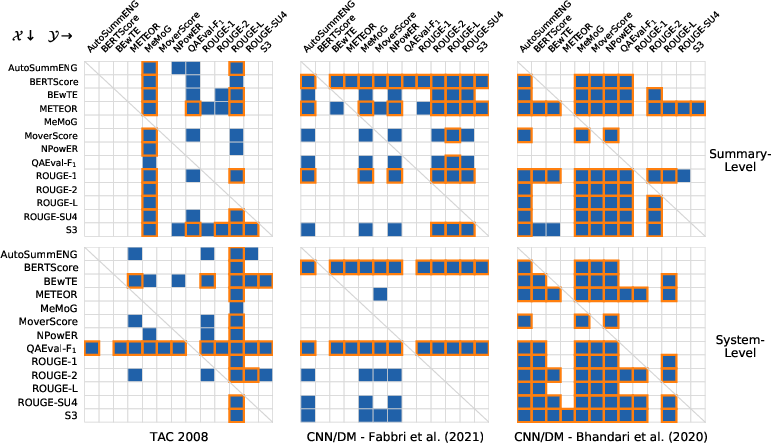
Figure 5: Pairwise Perm-Both hypotheses tests for all metric pairs; blue for p<0.05, orange outline for Bonferroni-adjusted significance. Row wins over column if significant.
The pattern does not hold across all datasets; e.g., sampled datasets such as Bhandari et al. exhibit narrower CIs and different significance outcomes, highlighting the sensitivity of metric comparisons to dataset construction and annotation procedures.
Methodological and Practical Implications
Statistical Soundness and Standardization
The paper rigorously demonstrates that traditional parametric inference is often unjustified for reference-based metric evaluation. Nonparametric bootstrap and permutation tests avoid untenable normality assumptions and accommodate the factorial structure of hypothesis generalization. Both randomizing across systems and inputs (Boot-Both/Perm-Both) best reflect uncertainty in practical system comparisons—where both dimensions are highly variable in deployed assessments.
Re-Evaluation of Metric Utility in Summarization
A striking claim is that in current summarization evaluation settings, the field has low certainty in the conclusions drawn from automatic metrics. System-level ranking error rates—derived from the width of Kendall’s τ intervals—suggest that, for many published results, even a large observed improvement in automatic metric correlation may not be statistically distinguishable from noise, and that automatic metrics may wrongly rank systems with respect to human judgments up to half the time.
Downstream Consequences and Recommendations
- Metric development and comparison should adopt Boot-Both and Perm-Both as the standard for uncertainty and significance reporting, respectively.
- ROUGE improvements cannot be regarded as definitive evidence of a superior summarization system; instead, robustness to CI width and explicit significance testing must be demonstrated.
- There is an exigent need for aggregation of much larger, more diverse, and more faithfully sampled summary-annotation datasets. Until then, it is inadvisable to rely entirely on automatic metrics for model selection or publication-worthiness.
- Analyses indicate that BERTScore and QA-Eval yield superior alignment with human ratings under certain conditions, but the field lacks universally superior metrics that robustly generalize across datasets/annotations.
Broader Applicability
Boot-Both resampling and Perm-Both significance testing generalize immediately to other text generation evaluation problems where observed scores are matrices rather than i.i.d. vectors—most notably, in NLG, MT, and structured output assessment.
Future Directions
- Meta-evaluation: Empirical assessment of cross-domain generalizability and robustness of the proposed methods to other annotation schemes and even downstream extrinsic evaluation settings.
- Data collection: Scaling and standardizing human evaluation, possibly via improved crowdsourcing or semi-automatic hybrid approaches, to allow for more precise statistical quantification of metric reliability.
- Metric improvement: Insights from these statistical tests can be used to construct meta-metrics or ensemble metrics whose correlation performance is less sensitive to dataset shifts and annotation variance.
Conclusion
The paper establishes that the evaluation of summarization metrics—when conducted with statistically grounded, resampling-based inference—reveals far greater uncertainty than is typically acknowledged in the literature. Analytical findings challenge existing dogma about the reliability of automatic evaluation, expose the limitations of traditional significance tests and CIs, and recommend instead robust, nonparametric resampling approaches that reflect the true epistemic uncertainty inherent in current summarization benchmarks. As automatic summarization (and NLG more broadly) advances, metric evaluation practice should evolve to reflect these insights, both in published research and in downstream deployment.