Pathways: Asynchronous Distributed Dataflow for ML
Abstract: We present the design of a new large scale orchestration layer for accelerators. Our system, Pathways, is explicitly designed to enable exploration of new systems and ML research ideas, while retaining state of the art performance for current models. Pathways uses a sharded dataflow graph of asynchronous operators that consume and produce futures, and efficiently gang-schedules heterogeneous parallel computations on thousands of accelerators while coordinating data transfers over their dedicated interconnects. Pathways makes use of a novel asynchronous distributed dataflow design that lets the control plane execute in parallel despite dependencies in the data plane. This design, with careful engineering, allows Pathways to adopt a single-controller model that makes it easier to express complex new parallelism patterns. We demonstrate that Pathways can achieve performance parity (~100% accelerator utilization) with state-of-the-art systems when running SPMD computations over 2048 TPUs, while also delivering throughput comparable to the SPMD case for Transformer models that are pipelined across 16 stages, or sharded across two islands of accelerators connected over a data center network.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Pathways, a new computer system made by Google that helps train and run very large machine learning models across thousands of special chips (like TPUs and GPUs). Think of Pathways as a smart “conductor” for a giant orchestra of computers: it decides what each chip should do, when to do it, and how to move data between them so everything runs smoothly and fast.
The big idea is to keep flexibility for new kinds of ML models while still getting top speed for today’s models. Pathways can handle complex setups, like splitting a big model into stages (pipelining), or spreading work across different groups of chips in different places, without slowing down.
Key Questions the Paper Tries to Answer
Here’s what the authors wanted to figure out, in simple terms:
- How can we run huge ML models on thousands of chips efficiently, even when the models don’t fit the “everyone does the same thing at the same time” style?
- Can we make one central controller that keeps everything organized, but still be as fast as systems where every computer runs its own copy of the program?
- How do we move data between chips quickly and in smart ways, especially when they’re in different “islands” or buildings?
- Can we share chips between different users and programs without wasting time or memory?
- Will this work for real models, like Transformers used in language tasks, and still match state-of-the-art performance?
How Pathways Works (Methods and Approach)
To make this accessible, think of Pathways like a city’s traffic system:
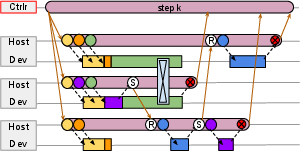
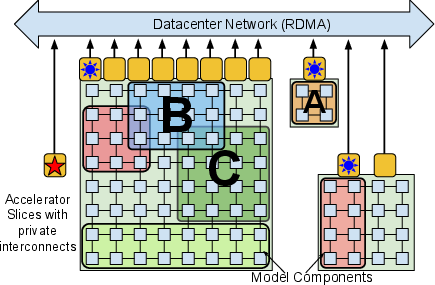
- The “Resource Manager” is like a city planner. It hands out “virtual streets” (virtual devices) that map onto real roads (physical chips). This helps place work in the best spots for fast communication.
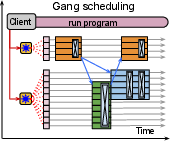
- The “Scheduler” is like a traffic light system. It makes sure groups of cars (computations) start in the right order and at the same time when needed (“gang scheduling”), so nobody blocks the intersection.
Here are the main ideas explained with everyday language:
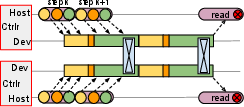
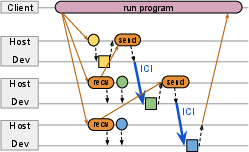
- Single Controller: Instead of running the same program separately on every computer (“multi-controller”), Pathways has one “boss program” that sends instructions to all chips. This makes it easier to handle complicated models and share resources.
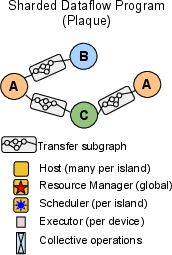
- Sharded Dataflow Graph: Imagine breaking a big task into smaller pieces (“shards”), like slicing a pizza. Each piece is a node in a graph, and arrows show how data flows from one piece to another. Pathways keeps this graph compact by treating whole groups of shards as single nodes when possible.
- Futures: A “future” is just a promise of a result that will arrive later. Using futures lets Pathways start preparing the next steps before current steps are fully done, keeping chips busy.
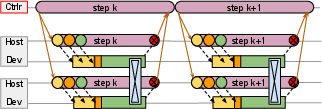
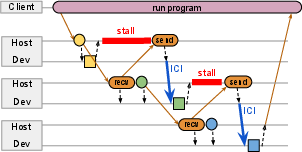
- Parallel Asynchronous Dispatch: Instead of waiting for each step to finish before setting up the next one, Pathways prepares many steps at once in parallel. Think of setting the table for all dinner courses early, so you don’t pause between courses.
- Gang Scheduling: When multiple chips must start together (like a band playing a song in sync), Pathways schedules them to avoid deadlocks or waits.
- Smart Data Movement: Pathways automatically sends data where it’s needed—sometimes over fast chip-to-chip links (like ICI on TPUs), sometimes over the data center network (DCN). It can “scatter” and “gather” data as needed, like distributing and collecting papers in a classroom.
- Integration with JAX and TensorFlow: Pathways can run existing ML code with minimal changes, and it can turn JAX functions into compiled chunks that run efficiently on TPUs.
The authors test Pathways using:
- Micro-benchmarks: Tiny programs that measure overheads, like timing how fast a simple “add and reduce” step runs.
- Real models: Big Transformer models (including T5 variants and a 3-billion-parameter LLM), trained on up to 2,048 TPU cores.
Main Findings and Why They Matter
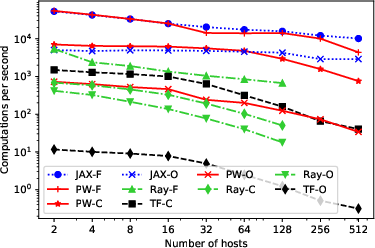
- Near 100% Accelerator Utilization: Pathways can keep thousands of chips almost fully busy, matching the speed of top systems like JAX when training standard “SPMD” models (where all chips run the same code on different data).
- Works Across Multiple TPU Pods: It’s the first system designed to run programs spanning multiple TPU groups (“pods”), meaning it scales beyond a single cluster.
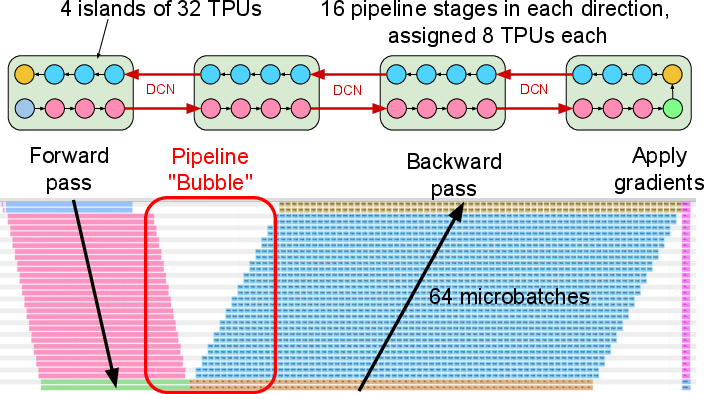
- Pipelining Performance: For Transformer models split into up to 16 stages, Pathways achieves throughput close to the standard SPMD method, even when the stages are spread across different islands of chips connected over a data center network.
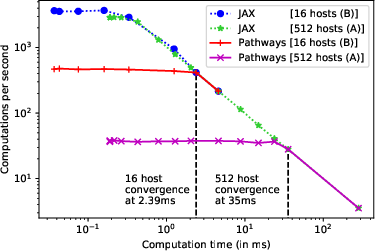
- Parallel Dispatch Helps: When computations are short, organizing and preparing the next steps in parallel prevents the system from stalling. This keeps performance high.
- Efficient Multi-Tenancy: Pathways can share chips among different users and programs, scheduling fairly (e.g., giving each program a proportional share), with little or no switching overhead.
- Flexible Yet Fast: Unlike older single-controller systems that slowed down when models got complex, Pathways retains the flexibility for future ML designs without sacrificing performance.
These results are important because they show you don’t have to choose between flexibility and speed. Pathways can handle modern and future ML models—like those with pipelines, sparse computations, or mixtures of experts—without collapsing under the coordination and data movement challenges.
Implications and Impact
- Faster Progress on Large Models: Researchers can try out new ideas (like fine-grained control flow, mixtures of experts, or cross-task sharing) without rewriting everything to fit a rigid style.
- Better Use of Expensive Hardware: Pathways makes it easier to share accelerators and run multiple tasks together efficiently, which reduces waste and cost.
- Scales to Future Needs: As ML models grow and become more complex, and as chip clusters get bigger and more varied, Pathways’s design will still work.
- Easier Experimentation: Because Pathways integrates with familiar tools like JAX and TensorFlow, teams can adopt it without large code changes and still get high performance.
In short, Pathways is like upgrading from many separate band leaders to a single expert conductor who can handle many styles of music, coordinate musicians across multiple stages, and keep everything playing in sync—at full speed—today and as the music gets more complex in the future.
Collections
Sign up for free to add this paper to one or more collections.