- The paper demonstrates that composable systems dynamically allocate resources to reduce inefficiencies in deep learning workloads.
- It evaluates performance using benchmarks like MobileNetV2, ResNet50, YOLOv5, and BERT, revealing configuration-specific results.
- Software optimizations, including mixed-precision training and distributed data parallelism, significantly reduce model training times.
This essay provides an in-depth analysis of the paper "Performance Analysis of Deep Learning Workloads on a Composable System," which explores the potential benefits and performance characteristics of leveraging a composable infrastructure for deep learning workloads.
Introduction
The paper addresses the pressing challenge of resource inefficiency in modern data centers, particularly due to fixed provisioning of compute, storage, and network resources. The concept of a composable infrastructure offers a promising solution by enabling dynamic allocation and reconfiguration of resources such as CPUs, GPUs, storage, and network interfaces. This architectural flexibility supports a wide range of workloads, including AI and big data analytics, and facilitates early-stage experimental evaluations of system designs.
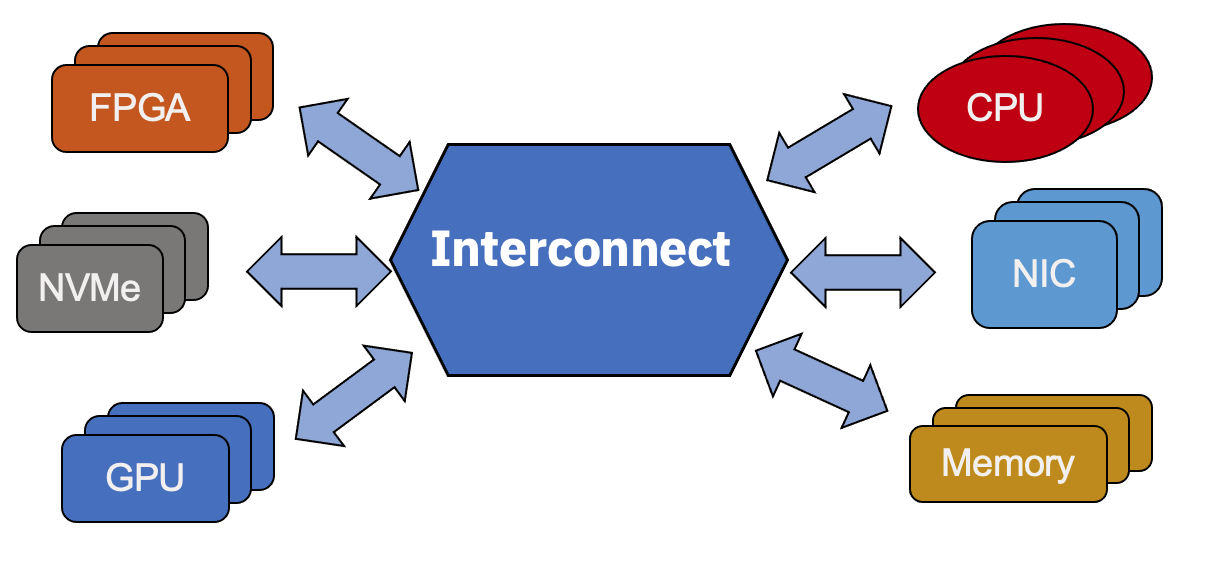
Figure 1: Composable Server Concept.
Composable System Architecture
The composable system detailed in the study is comprised of several key components such as the Falcon 4016 composable chassis, host servers, and a management server. The Falcon 4016 is integral as it accommodates a variety of devices (e.g., GPUs, NICs, NVMe SSDs) and supports high-speed PCI-e 4.0 connections, minimizing latency and maximizing flexibility in hardware configurations.
Enhancements also include a management interface based on the OpenBMC software stack, allowing for sophisticated configuration and monitoring capabilities. Various modes of operation, including standard and advanced modes, enable a range of configurations from single host interfacing with multiple GPUs to dynamic provisioning of devices across up to three hosts.
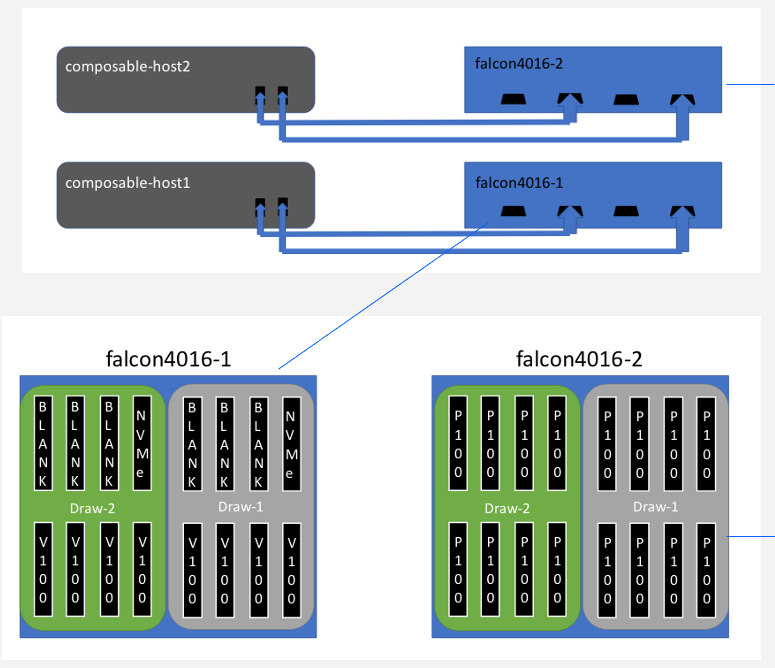
Figure 2: Example High-level Composable Architecture.
Experimental Setup and Benchmarks
To evaluate the performance of deep learning workloads on this composable system, the authors deployed a series of experiments using popular DL benchmarks across computer vision and natural language processing domains. The testbed was configured with NVIDIA Tesla V100 GPUs and high-speed NVMe drives, tested in varied composable configurations such as local, hybrid, and Falcon-attached setups.
The benchmarks include MobileNetV2, ResNet50, YOLOv5 for computer vision tasks, and BERT for NLP tasks, chosen for their diverse computational and communication demands.
GPU and CPU Utilization
The benchmarks were evaluated under different configurations to assess GPU utilization and memory access patterns. It was observed that certain models, especially BERT-based NLP models, consumed substantial GPU memory, whereas vision benchmarks effectively utilized GPU compute power without saturating memory bandwidth.
Impact of Falcon Switching
A critical aspect of this study was assessing the overhead introduced by PCI-e switching when using Falcon-attached resources. The results indicated negligible slowdowns (less than 7%) for smaller models but noticeable overheads for larger NLP models due to increased data exchange requirements, reflected in reduced inter-GPU communication bandwidth.
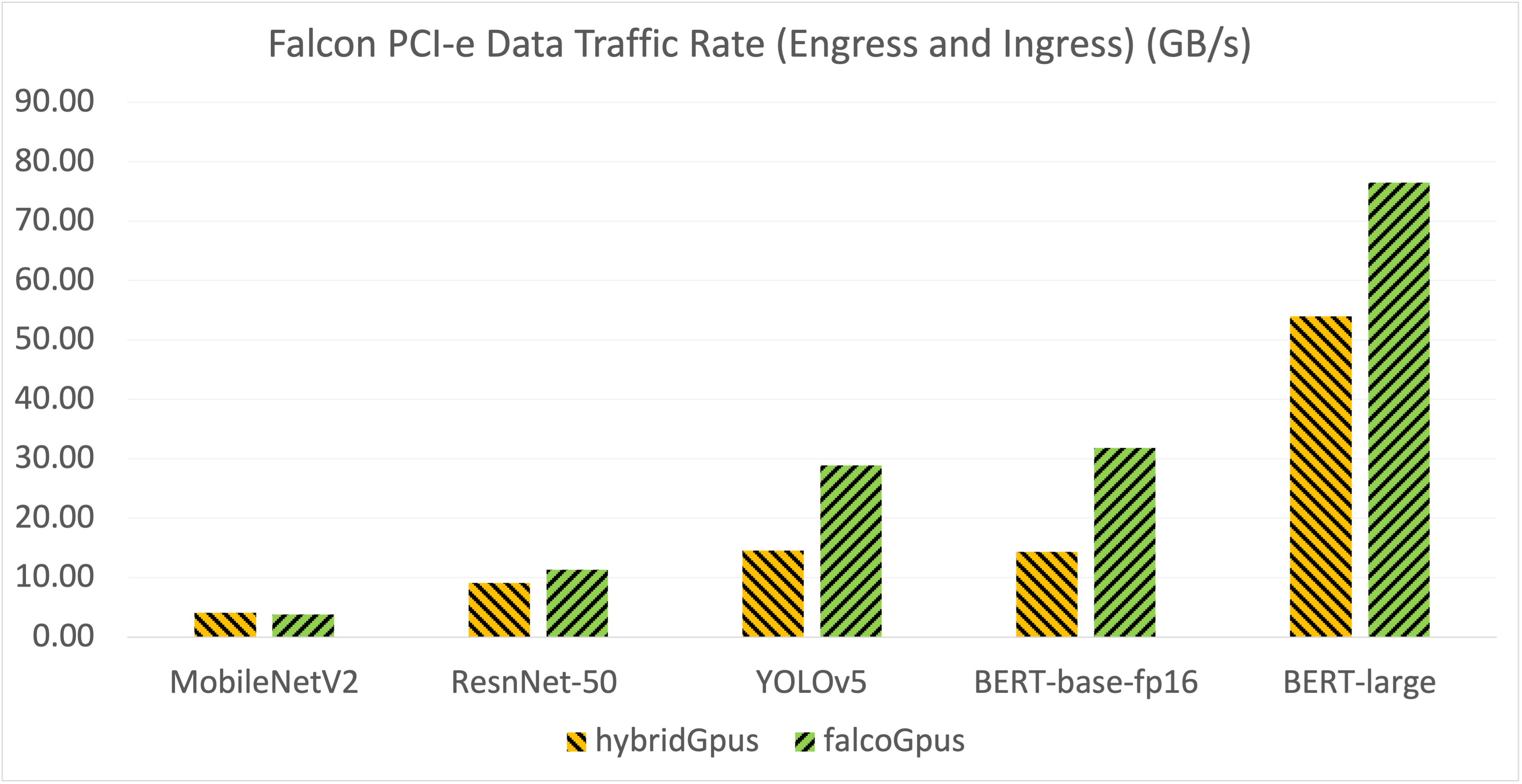
Figure 3: PCIe Data Transfer Rate (GB/s) for Falcon-attached GPU Configurations.
Software-level Optimizations
The study also explored the impact of mixed-precision training and distributed data parallel (DDP) optimization techniques. These approaches significantly reduced model training times across configurations, showcasing the importance of software optimizations in complementing composable hardware capabilities.
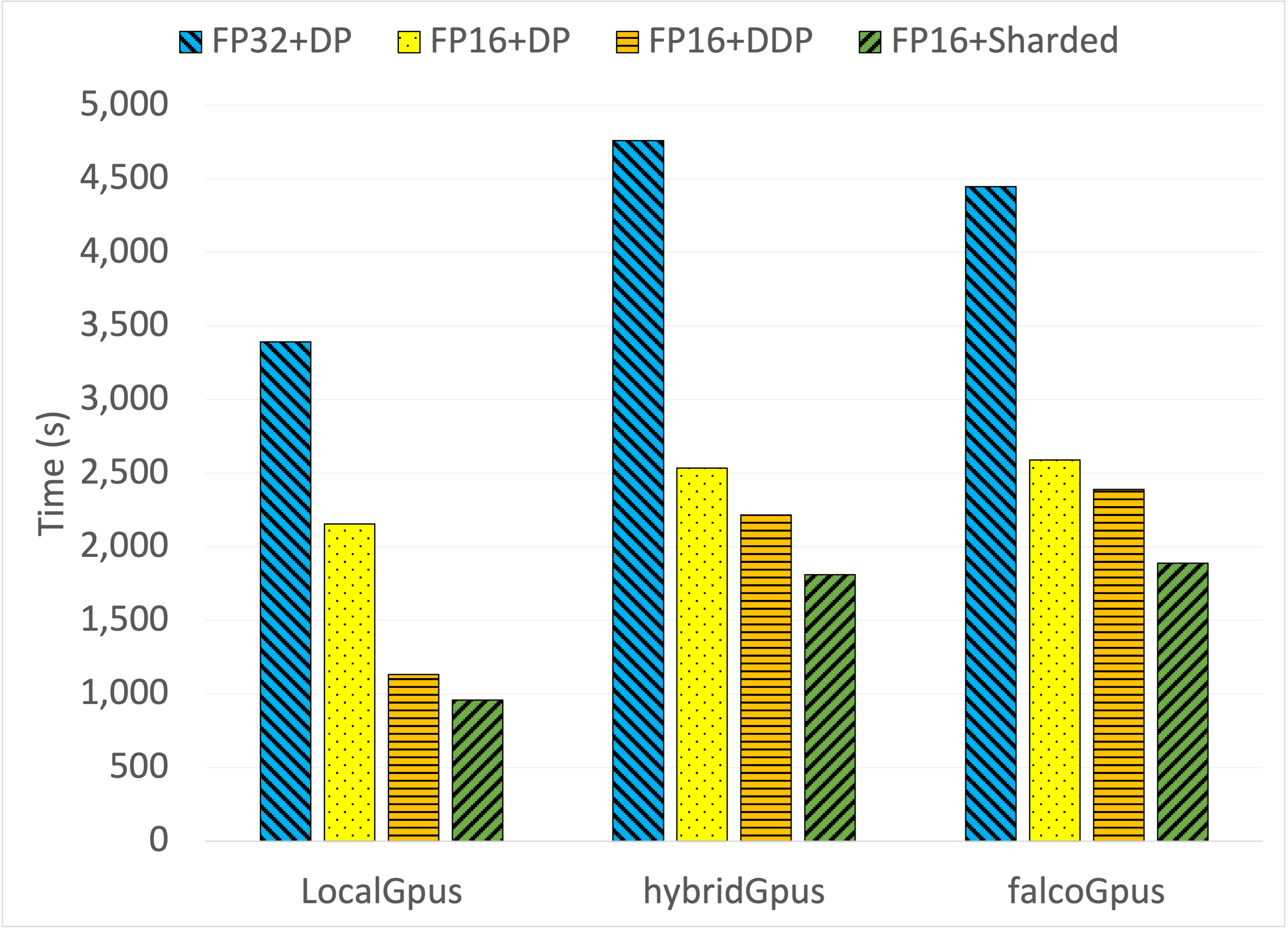
Figure 4: The Impact of Various Software-level DL Optimization on BERT-large Fine-tuning using the SQuaD dataset.
Conclusion
The composable system offers significant versatility for deploying a variety of deep learning workloads. While the PCI-e switching introduces some overhead, particularly for large-scale NLP tasks, the flexibility in resource allocation compensates for this, allowing for tailored configurations that meet specific workload requirements.
Future work is aimed at integrating more diverse hardware accelerators and further refining the system for optimal performance across varied AI and HPC applications. This exploration paves the way for more adaptive and efficient data center architectures oriented towards next-generation AI infrastructure.
This paper provides substantial insights into the dynamics of composable systems, illustrating the potential for enhanced resource utilization and system agility in AI-focused data centers.