- The paper introduces the Hamburger module that uses matrix decomposition to factorize input representations as an alternative to self-attention.
- It leverages optimization algorithms like vector quantization and non-negative matrix factorization to extract low-rank embeddings for effective context modeling.
- Experimental results on vision tasks such as semantic segmentation demonstrate that Hamburger achieves competitive performance with improved computational efficiency.
Is Attention Better Than Matrix Decomposition?
Introduction
The paper "Is Attention Better Than Matrix Decomposition?" (2109.04553) challenges the perception that the self-attention mechanism, due to its popularity and success in various domains, especially in vision and NLP tasks, is irreplaceable for modeling global contexts in deep learning. The study explores the potential of Matrix Decomposition (MD) as an alternative, framing the problem of context modeling as a low-rank recovery issue. It introduces a novel module named "Hamburger," which leverages optimization algorithms for MD to factorize and reconstruct input representations into low-rank embeddings, purporting to rival the performance and efficiency of self-attention.
Methodology
Global Context Modeling as Low-Rank Recovery: The paper posits that the inherent correlation of hyper-pixels in image data, seen as long-range dependencies in networks, aligns with low-rank assumptions. This approach reframes the context learning task as optimizing for the low-rank structure within the data matrix, leveraging established MD methods.
Hamburger Architecture: The core of the proposed methodology is the "Hamburger" module, likened to its namesake for structured layers: two "bread" layers of linear transformation ensconce a "ham" layer where the primary computation occurs through MD. By mapping input data via linear transformations and solving for low-rank embeddings through MD, Hamburger processes context information effectively. The iterative optimization defines the computational graph necessary for global feature extraction.
Matrix Decomposition Techniques: The paper explores several MD models for the "ham" layer, notably Vector Quantization (VQ) and Non-negative Matrix Factorization (NMF), solving these through algorithms adapted for differentiable neural network contexts. These decompositions reveal compact structures in representations, enabling efficient computation comparative to self-attention's higher complexity.
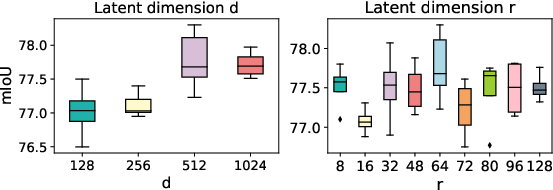
Figure 1: Ablation on d and r
Experimental Results
Vision Tasks Comparison: The research provides comprehensive experimental results in the scope of vision tasks like semantic segmentation and image generation, domains where global context modeling is critical. Remarkably, Hamburger achieves state-of-the-art or competitive results against current attention-focused methods. For instance, in semantic segmentation, it improves upon results on established datasets including PASCAL VOC and PASCAL Context.
Efficiency and Scalability: In terms of computational efficiency, Hamburger demonstrates significant advantages. The algorithmic complexity of MD used (O(ndr) where r≪n) stands in contrast to self-attention’s O(n2d), making it more scalable, particularly in scenarios constrained by memory and processing capabilities.
Implications and Future Directions
Implications for Deep Learning Architectures: This work illuminates the potential of long-established methodologies like MD in modern contexts, suggesting a paradigm where optimization-derived architectures might supplant or augment heuristic-driven designs like attention. It proposes these structured approaches could lead to more mechanistic insights and controlled parameterization in learning representations.
Future Directions: The paper opens avenues for exploring more sophisticated MD techniques within neural architectures, potentially broadening to unsupervised domains or expanding into natural language processing tasks. Further investigation into gradient stability and the exploration of optimization-driven network designs could unveil deeper structural efficiencies and tuning mechanisms.
Conclusion
The comparative analysis and results indicate that MD-based frameworks, exemplified in the Hamburger module, can hold their ground against attention mechanisms by harnessing the robustness and simplicity of mathematical optimization strategies. This work not only challenges prevailing norms but also rekindles interest in classical methods as powerful tools in the era of deep learning.