Published 9 Jun 2020 in cs.LG and stat.ML | (2006.05094v2)
Abstract: Most bandit policies are designed to either minimize regret in any problem instance, making very few assumptions about the underlying environment, or in a Bayesian sense, assuming a prior distribution over environment parameters. The former are often too conservative in practical settings, while the latter require assumptions that are hard to verify in practice. We study bandit problems that fall between these two extremes, where the learning agent has access to sampled bandit instances from an unknown prior distribution $\mathcal{P}$ and aims to achieve high reward on average over the bandit instances drawn from $\mathcal{P}$. This setting is of a particular importance because it lays foundations for meta-learning of bandit policies and reflects more realistic assumptions in many practical domains. We propose the use of parameterized bandit policies that are differentiable and can be optimized using policy gradients. This provides a broadly applicable framework that is easy to implement. We derive reward gradients that reflect the structure of bandit problems and policies, for both non-contextual and contextual settings, and propose a number of interesting policies that are both differentiable and have low regret. Our algorithmic and theoretical contributions are supported by extensive experiments that show the importance of baseline subtraction, learned biases, and the practicality of our approach on a range problems.
The paper introduces a gradient ascent framework that meta-learns bandit policies to minimize Bayes regret and maximize expected reward.
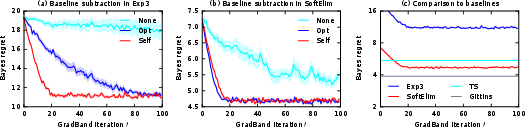
It employs advanced baseline subtraction techniques to significantly reduce gradient estimation variance and ensure efficient convergence.
Empirical results demonstrate up to a 95% regret reduction in contextual bandit settings, validating its robustness and scalability.
Meta-Learning Bandit Policies by Gradient Ascent — Expert Summary
Problem Formulation and Meta-Learning Paradigm
The paper presents a meta-learning framework for bandit policy optimization situated between traditional minimax and Bayesian approaches. Instead of worst-case instance analysis or requiring a known prior, the assumed setting provides sampled bandit problem instances from an unknown distribution P. The central objective is to learn parameterized, differentiable policies that minimize Bayes regret and maximize Bayes reward in expectation over P. This two-level optimization problem—learning policies that adapt efficiently within each instance and tuning policy parameters meta-optimally over the prior—naturally motivates policy-gradient-based meta-learning.
Gradient-Based Policy Optimization Algorithm
The proposed algorithm ("GradBand") performs batch gradient ascent on policy parameters w by generating simulated bandit trajectories on sampled instances from P. Per-iteration complexity is O(Kmn) where K is the number of arms, m is batch size, and n is the horizon. Crucially, the algorithm is agnostic to the explicit functional form of P—all required statistics are empirically estimated from sampled instances. The reward gradient derivation leverages additivity and sequential independence properties of the bandit process:
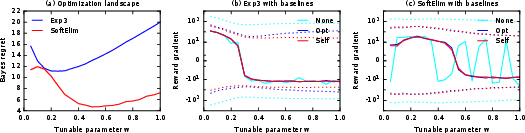
Figure 1: The Bayes regret and reward gradients of and policies, showing gradient estimation variance for different baseline choices.
To address high gradient estimation variance, the methodology employs advanced forms of baseline subtraction, including both "optimal" (oracle) and "self" (run-based) baselines, yielding substantial variance reduction and more stable gradient trajectories under stochastic sampling.
Differentiable Policy Classes and Their Analysis
Non-Contextual Setting
Three differentiable policy families are introduced:
EXP3: A softmax-based randomized policy parameterized for exploration rate, suitable for adversarial bandits but generally over-explorative in stochastic regimes. The policy is analytically differentiable via a closed-form score-function.
SoftElim: A novel softmax policy that progressively "soft eliminates" arms with large empirical gaps and frequent sampling, modulated by a learnable exploration parameter. The regret bound for SoftElim is O(∑i=1(16/Δi)logn) for K arms, matching gap- and time-dependence of classic UCB algorithms, but tunable via w.
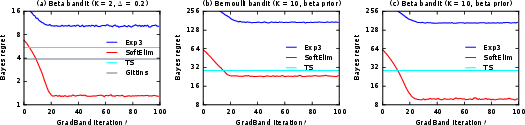
Figure 2: The Bayes regret of and policies, as a function of gradient ascent iterations in a Bernoulli bandit.
RNN Policies: History-dependent policies parameterized by the weights of a recurrent neural network, which are meta-learned via gradients. The sequence encoding and softmax output enables instance-adaptive exploration strategies not tractable in analytic policies.
Contextual Setting
The framework generalizes to contextual bandits by learning a context projection W to an informative subspace and leveraging linear bandit estimators in the projected space. Differentiable policies include:
Contextual SoftElim: Extends SoftElim to context-projected reward gaps and confidence widths, with regret scaling as O~(K2dn).
Contextual Thompson Sampling (TS): TS policies are differentiated by including sampled posterior means as explicit variables in the gradient, with the derived reward gradient involving expectations over posterior samples, leading to higher estimator variance.
ϵ-greedy: Included as a baseline, with gradients only on scalar exploration rate.
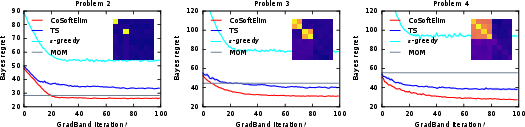
Projection matrices learned by meta-gradient optimization reliably recover the relevant task subspace, outperforming method-of-moments baseline subspace estimators and simple bias-based regularization schemes.
Empirical Results: Regret Minimization and Robustness
Extensive experiments across simulated, synthetic, and real-world multi-class classification problems demonstrate:
Substantial improvements in Bayes regret—optimized SoftElim and contextual policies outperform UCB, Thompson Sampling, and Gittins index baselines in most regimes.
Baseline subtraction (notably bself) drastically reduces reward gradient variance, enabling efficient convergence within a few dozen gradient steps.
Learned policies are robust to batch size, horizon length, and moderate prior misspecification. Regret scaling as logn corroborates theoretical results in the main text.
RNN policies display competitive performance, exhibiting instance-specialized exploration strategies and robustness to distractor arms in high-dimensional problems.
Figure 4: The Bayes regret of RNN policies, showing average and median performance over multiple optimization runs.
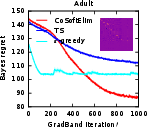
On real-world datasets (e.g., UCI ML Repository), meta-learned contextual policies achieve up to 95% regret reduction versus untuned baselines, with empirical projection matrices recovering task-relevant features.
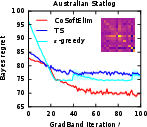
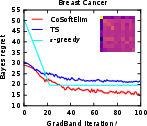
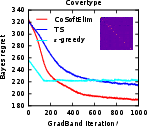
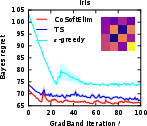
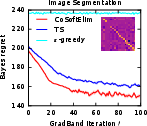
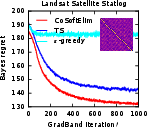
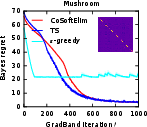
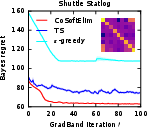
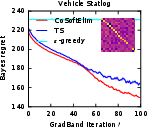
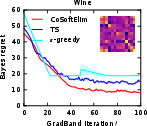
Figure 5: The Bayes regret of , , and −greedypoliciesonclassificationbenchmarksaftermeta−gradientoptimization.</p></p><h3class=′paper−heading′id=′theoretical−considerations−and−strong−claims′>TheoreticalConsiderationsandStrongClaims</h3><p>TheanalysisprovesconcavityoftheBayesrewardwithrespecttoexplorationhorizoninexplore−then−commitpolicies,thusestablishingglobalconvergenceguaranteesforgradientascentinthisrestrictedsetting.Furthermore:</p><ul><li>Thepaperderives,forthefirsttime,therewardgradientforThompsonsamplingpoliciesinnon−contextualandcontextualsettings.</li><li>Empiricalevidencesuggestsnear−concavityandunimodalityofregretlandscapesinalltesteddifferentiablepolicies.</li><li>Thepaperclaimsthatbaseline−subtractedgradientestimatesallownear−optimalpolicylearningwithordersofmagnitudelesscomputationalexpensecomparedtoclassicaldynamicprogramming(Gittins),andgreaterstabilitythandeepRLmethods(DQN).</li></ul><h3class=′paper−heading′id=′limitations−computational−tradeoffs−and−scaling′>Limitations,ComputationalTradeoffs,andScaling</h3><p>Themostcriticallimitationisvarianceinempiricalgradientestimation,particularlyacuteinRNNpolicies,whichmotivatesfurtherresearchinscalablecontrolvariatemethods.Althoughbaselinesubtractionand<ahref="https://www.emergentmind.com/topics/curriculum−learning"title=""rel="nofollow"data−turbo="false"class="assistant−link"x−datax−tooltip.raw="">curriculumlearning</a>yieldpracticalimprovements,theoreticalconvergenceoutsideoftheestablishedconcavecasesremainsopen.Moreover,theframeworkassumestheabilitytosimulatecompletetrajectoriesonsampledinstances,whichmaynotalwaysbeaccessibleinappliedsettings.</p><p>Computationally,theapproachisparallelizableandfeasibleforproblemswithlargeK,d,andn—providedmemoryconstraintsonKmn$ statistics are observed. Comparing Gittins index computation (days of compute) to meta-gradient policy learning (seconds–minutes), the method presents attractive scalability characteristics.
Implications, Practical Impact, and Future Directions
The meta-learning approach enables:
Automated, data-driven tuning of bandit algorithms for specific application regimes (clinical trials, adaptive recommendations, etc.) where accurate prior modeling is not feasible.
Instance-adaptive exploration guided by empirical prior characteristics as opposed to the worst-case or strictly Bayesian assumptions.
Integration of deep representation learning (e.g., RNNs, context projection) within a theoretically motivated framework.
Immediate extension to complex settings—generalized linear bandits, combinatorial actions, partial monitoring—by designing differentiable policy classes and reward structures.
Figure 6: The Bayes regret of different policies under varying meta-learned subspace configurations.
Research directions include: advancing variance reduction for high-dimensional policies, extending concavity results, and analyzing global convergence for softmax-based meta-learning in broader settings.
Conclusion
This work establishes a rigorous, scalable mechanism for meta-learning bandit policies by gradient ascent over sampled task priors. The integration of differentiable policy classes, theoretical analysis of reward gradients, and empirically validated variance reduction positions the approach as a practical alternative to conventional bandit and RL tuning. The framework's adaptability and performance gains suggest promising avenues for meta-learning exploration strategies in sequential decision-making under uncertainty.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.