- The paper introduces STANNIS, a framework that accelerates deep neural network training by leveraging computational storage to minimize data movement.
- It employs Newport, an ASIC-based storage device with a quad-core ARM Cortex A-53, dynamically tuning workloads for heterogeneous systems.
- Experimental results demonstrate up to a 2.7x speedup and 69% reduction in energy usage per image, highlighting significant performance and efficiency gains.
STANNIS: Low-Power Acceleration of Deep Neural Network Training Using Computational Storage
Introduction
The paper presents a framework for distributed training of deep neural networks (DNNs) utilizing computational storage devices (CSDs), notably titled "STANNIS." The intention is to revolutionize the typical train-and-infer workloads by minimizing data movements between storage and host systems. Central to this proposition is "Newport," a novel low-power CSD featuring augmented processing abilities. The research outlines a system architected to alleviate the high data movement overhead typically associated with neural network training, thereby improving performance and reducing power consumption.
Hardware Architecture
The underlying architecture, "Newport," integrates in-storage processing (ISP) capabilities directly into storage devices, merging storage management with computational power. Newport is an ASIC-based CSD encompassing both computing and data storage functionalities within a single environment.
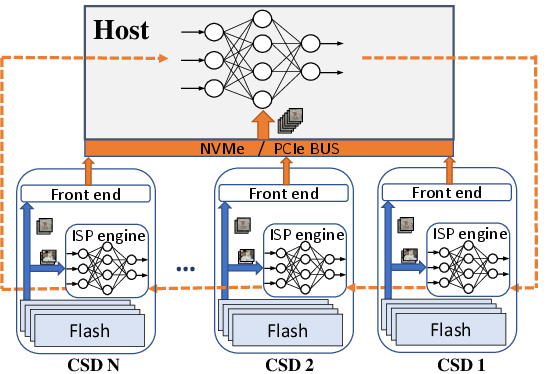
Figure 1: Stannis Architecture.
The architecture comprises three main subsystems: the front-end subsystem (FE), back-end subsystem (BE), and a dedicated ISP processing engine. The FE is responsible for interfacing with the host and decoding NVMe commands. The BE manages I/O operations with NAND flash chips, orchestrated across multiple channels. The ISP engine distinguishes Newport with a quad-core ARM Cortex A-53 processor, facilitating in-situ data processing and reducing the latency and bandwidth bottlenecks prevalent in traditional architectures.
Software Framework
The software framework "Stannis" capitalizes on the distributed training model, overcoming limitations of heterogeneous systems by dynamically tuning workloads based on the processing capabilities. Variations in batch size are allocated according to each node's computational speed, thereby synchronizing processing times and minimizing idle durations.

Figure 2: Stannis Performance for different deep neural networks.
This architecture allows for the effective distribution of neural network models, accommodating privacy constraints by processing sensitive data locally, eliminating the necessity of data transmission outside the storage unit. The workload calibration algorithm benchmarks the processing speeds to fine-tune batch sizes, ensuring equitable workload distribution among processors. This effectively mitigates the downside of Horovod's fixed batch sizes, particularly in systems with heterogeneous processing capabilities.
The experimental investigations underscore significant improvements in both training speed and energy efficiency achieved through the Newport CSDs and Stannis framework. Across several DNN architectures, the system exhibited marked improvements compared to conventional storage methods, attaining up to a 2.7x speedup in processing.
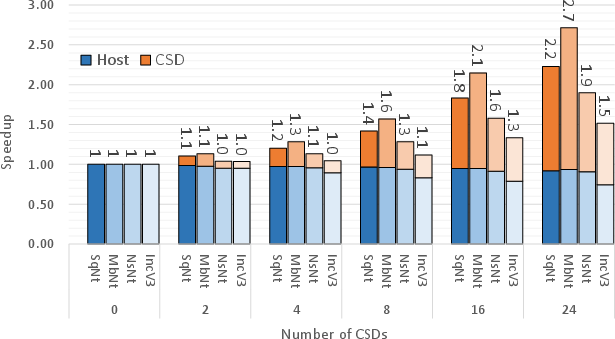
Figure 3: Speedup for different deep neural networks.
Furthermore, energy consumption analyses reveal that the ISP approach leads to substantial power savings. A comparative assessment against a standard SSD configuration demonstrated up to a 69% reduction in energy usage per image processed, showcasing the efficiency gains inherent in the Newport-driven computational paradigm.
Conclusion
The "STANNIS" framework represents an innovative advancement in the domain of in-storage processing for deep learning applications. It stands as a compelling solution that effectively reduces data movement overhead, enhances processing throughput, and introduces substantial energy savings in deep learning model training. The architectural innovations within Newport align well with the increasing demands for energy-efficient, real-time processing capabilities across distributed edge environments. Future research opportunities lie in extending the heterogeneity management capabilities of Stannis and exploring federated learning integrations for distributed neural network applications.