- The paper introduces CASE, a task for suggesting contextually fitting terms using large-scale, automatically generated annotations.
- It employs independent encoders for context and seed terms, with seed-aware attention (notably using the trans-dot mechanism) to boost retrieval accuracy.
- Empirical results demonstrate that the simplified NBoW encoder with trans-dot attention achieves a Recall@10 of about 24.5%, outperforming traditional baselines.
Context-Aware Semantic Expansion: Task, Dataset, and Model
This paper introduces Context-Aware Semantic Expansion (CASE), a new task that generalizes beyond lexical substitution and set expansion by requiring the suggestion of terms that contextually fit a specific sentential context and a seed term. Unlike prior approaches that rely on human-labeled data, the authors devise a method for large-scale automatic data collection using naturally occurring textual patterns, and propose a neural network architecture specifically engineered for CASE. The study comprehensively evaluates baselines, context encoder variations, and attention mechanisms, culminating in a detailed empirical investigation.
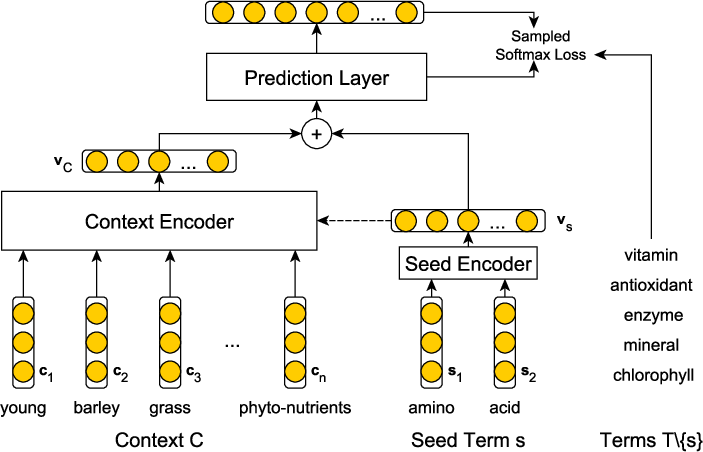
Figure 2: The network architecture of CASE illustrates the use of independent context and seed encoders whose outputs are concatenated before a prediction layer.
Task Definition and Data Annotation
CASE is formally defined as the prediction of contextually supported terms given a context C and a seed term s, recovering terms T∖{s} for each annotated example ⟨C,T⟩. Annotated examples are mined from web-scale corpora by extracting sentences with Hearst patterns to generate natural term lists within contexts. This approach yields a dataset of 1.8 million sentences, each supporting multiple expansion targets for each seed, and does not require human annotation.
This large-scale, naturally supervised approach enables network training at a scale infeasible with manual annotation, making the proposed CASE dataset a substantial contribution. Furthermore, the authors analyze the inherent bias introduced by the inclusion of hypernyms in the extracted contexts and empirically demonstrate that removing hypernyms decreases performance only marginally.
Network Architecture
The proposed CASE model consists of independent encoders for the context and the seed term:
- The context encoder is tasked with extracting a fixed-dimensional representation of the context, and several architectures are explored: Neural Bag-of-Words (NBoW), CNN, RNN (vanilla, LSTM, GRU, BiLSTM), as well as placeholder-aware encoders like CNN+Positional Features and context2vec.
- The seed encoder uses NBoW, drawing from a separate embedding matrix, given the typical brevity of the seed terms.
The concatenated seed and context vectors are passed through a prediction layer, yielding a probability distribution over a candidate expansion vocabulary. To manage the computational demands, sampled softmax is employed due to the large output space.
Attention Mechanisms and Scoring Functions
Recognizing that not all context tokens contribute equally to the seed-context interaction, the architecture incorporates both seed-oblivious and seed-aware attention mechanisms:
- Seed-oblivious attention computes attention weights based solely on context features.
- Seed-aware attention conditions the attention weights on the embedding of the seed term itself. Several parameterizations are evaluated:
- Dot: Direct dot product between seed and context vectors.
- Concat: Concatenation of seed and context vectors fed through a feedforward NN.
- Trans-dot: Affine transformation of context vectors before the dot product with the seed vector.
Empirical results show that the trans-dot mechanism consistently yields the best retrieval accuracy and ranking metrics, achieving statistical significance over other alternatives.
Experimental Analysis
Key findings from the reported experiments include:
- Baseline comparisons: Lexical substitution methods (e.g., LS (1912.13194)) and set expansion approaches are substantially outperformed by neural architectures tailored to CASE. Notably, augmenting baselines to incorporate term co-occurrence (LSCo) yields some improvement, but does not close the performance gap with the CASE approach.
- Context encoder ablation: The simplest NBoW context encoder achieves the strongest results, outperforming more complex RNN-based and placeholder-aware models. This demonstrates that, for CASE, elaborate structure modeling (e.g., word order, position) gives way to capturing global co-occurrence signals and contextual distributional semantics.
- Attention incorporation: Seed-aware attention (especially with the trans-dot scoring function) consistently enhances recall, MAP, MRR, and nDCG, compared to both non-attention and seed-oblivious models.
- Hypernym bias: Removal of hypernyms from context only marginally reduces model accuracy, indicating that the model's contextualization and expansion capability generalize beyond explicit type constraints.
Quantitatively, the best configuration (NBoW+trans-dot) achieves Recall@10 of approximately 24.5%, with statistically significant improvements over all baselines and other model variants.
Theoretical and Practical Implications
The explicit separation of context and seed encoding, together with the systematic evaluation of context aggregation methods, reveals key insights about the inductive biases required for CASE. The empirical results suggest that in large-vocabulary, open-set expansion tasks, order-agnostic context modeling combined with global attention mechanisms are highly effective.
This work also articulates an end-to-end pipeline for dataset construction, model training, and evaluation in a manner that is robust to annotation scarcity. The approach is theoretically extensible to downstream NLP tasks that demand contextualized entity or terminology expansion, including but not limited to IR query suggestion, data augmentation for writing assistants, and pre-processing for tasks such as word sense disambiguation.
Future Prospects
Future research directions include integrating pre-trained LMs (e.g., BERT, T5) into the CASE framework to leverage their deep contextualization, investigating zero-shot and few-shot adaptation to new domains, and extending the CASE paradigm to phrase and clause-level expansions. Moreover, using CASE as a component or evaluation methodology in compositional and multi-sense representations would further test its utility for challenging semantic tasks.
Conclusion
CASE formalizes a novel and practically relevant semantic expansion problem. By leveraging large-scale, automatically harvested supervision and a tailored neural architecture, the study demonstrates both the limitations of prior art and the efficacy of simple, well-motivated neural mechanisms—chiefly, order-agnostic encoding plus seed-aware attention. These insights provide a robust foundation for continued research in contextual semantic augmentation and its diverse downstream applications (1912.13194).