- The paper presents ViLBERT, which innovatively extends BERT into a two-stream model that integrates visual and linguistic data via co-attentional transformers.
- It employs pretraining on 3.3M image-caption pairs with Faster R-CNN extracted features, emphasizing masked multi-modal learning for robust representation.
- ViLBERT delivers 2 to 10 percentage points improvements across tasks like VQA, VCR, and image retrieval, setting new performance benchmarks.
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
Introduction to ViLBERT
ViLBERT, short for Vision-and-Language BERT, represents a significant advancement in the development of task-agnostic visiolinguistic models designed to address multiple vision-and-language tasks. Departing from the conventional task-specific models, ViLBERT innovatively extends the BERT architecture into a two-stream paradigm that integrates visual and linguistic information through co-attentional transformer layers. This structure allows for seamless interaction between modalities, permitting variable depths necessary for processing and sparse interaction via co-attention.

Figure 1: Our ViLBERT model consists of two parallel streams for visual (green) and linguistic (purple) processing that interact through novel co-attentional transformer layers. This structure allows for variable depths for each modality and enables sparse interaction through co-attention.
Architecture and Methodology
The architecture of ViLBERT builds upon the foundations laid by the BERT model, adapting it to accommodate visual components alongside textual data. In ViLBERT, image content is divided into region features using a pre-trained object detection network, specifically Faster R-CNN with a ResNet-101 backbone trained on Visual Genome. This two-stream model comprises separate transformer blocks for visual and linguistic data, merged through co-attentional layers that facilitate context-rich interaction without excessive computational demand.
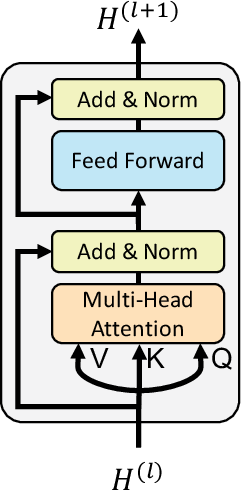

Figure 2: Standard encoder transformer block.
The core computational element in ViLBERT is the co-attentional transformer layer, which leverages query-key-value mechanisms to produce vision-conditioned language attention and vice versa. The retrieval and integration of attentional features from alternate modalities create opportunities for sophisticated multi-modal representations, capable of holistically understanding visiolinguistic input.
Pretraining Tasks
ViLBERT’s learning process is initiated through self-supervised proxy tasks on the Conceptual Captions dataset, consisting of approximately 3.3 million image-caption pairs collected from alt-text-enabled web images. The pretraining tasks include masked multi-modal learning and multi-modal alignment prediction, where the model reconstructs masked components and assesses alignment between text and images.
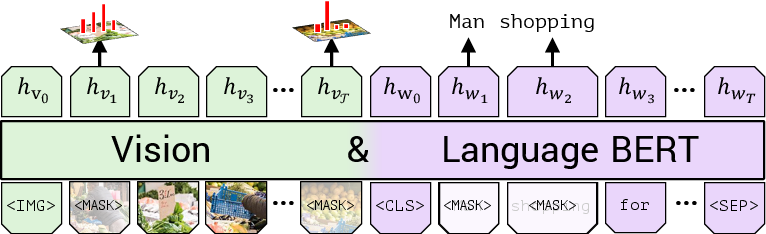
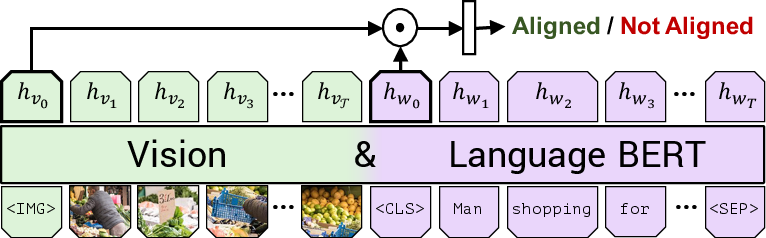
Figure 3: Masked multi-modal learning.
These pretraining tasks are essential for training ViLBERT to achieve significant enhancements across various vision-and-language tasks, moving away from isolated learning to a unified approach that leverages pretrainable visual grounding.
Transfer to Vision-and-Language Tasks
The versatility of ViLBERT is demonstrated by its ability to transfer to numerous established tasks with trivial architectural modifications, such as visual question answering (VQA), visual commonsense reasoning (VCR), referring expressions, and caption-based image retrieval. Performance improvements ranging from 2 to 10 percentage points against task-specific baselines validate its efficacy.

Figure 4: Examples for each vision-and-language task we transfer ViLBERT to in our experiments.
ViLBERT sets state-of-the-art benchmarks for tasks like VCR, RefCOCO+, and Flickr30k image retrieval by significant margins, reflecting its robust adaptability and strong representation power.
Experimental Analysis
A series of experiments and baseline comparisons underscored specific contributions of ViLBERT to its success. By isolating elements like the depth of co-attentional blocks or the scale of pretraining datasets, substantial insights into optimization strategies for visiolinguistic reasoning were gained.
Conclusion
ViLBERT is a profound step forward in vision-and-language representation learning, presenting an efficient, scalable, and universally applicable model. Its innovative co-attentional two-stream architecture not only surpasses current task-specific models but also offers a solid basis for future work in multi-modal AI, setting the stage for broader applications requiring integrated processing of visual and linguistic data. As the field advances, further exploration into generation tasks and multi-task learning will capture the full potential of ViLBERT's design.

Figure 5: Qualitative examples of sampled image descriptions from a ViLBERT model after our pretraining tasks, but before task-specific fine-tuning.
With the foundation laid by ViLBERT, avenues for future research include extending these models to other vision-and-language tasks, particularly those necessitating text generation. The complementary capabilities of self-supervised learning frameworks and transformer-based architectures offer promising directions for advancing AI research in holistic visiolinguistic understanding.