- The paper introduces CPSRs, a method leveraging random projections to compress state representations and reduce computational costs in model-based reinforcement learning for POMDPs.
- It demonstrates that CPSRs achieve comparable or superior prediction accuracy with orders of magnitude faster model build times than traditional TPSRs.
- It integrates CPSRs with fitted-Q function approximation to enable effective planning in challenging domains with large observation spaces and complex dynamics.
Efficient Learning and Planning with Compressed Predictive States: An Expert Review
Introduction
"Efficient Learning and Planning with Compressed Predictive States" (1312.0286) introduces Compressed Predictive State Representations (CPSRs), an extension of PSRs leveraging compressed sensing and random projection techniques to enable tractable and regularized learning of models for partially observable systems. The work addresses a key limitation of prior PSR approaches: the super-linear computational and storage costs of model estimation in complex, partially observable environments. The authors further integrate CPSR model learning with reinforcement learning strategies by combining their approach with fitted-Q function approximation for planning, and validate their framework empirically on synthetic and real-world domains.
Background: Predictive State Representations and Learning Paradigms
PSRs represent the state of partially observable dynamical systems as predictions about the future, specifically as the conditional probability over a core set of tests given history. As opposed to latent-state models such as POMDPs or HMMs, PSRs operate only with observable quantities, bypassing combinatorial latent-state inference and EM optimization. Learning PSRs can be performed either by combinatorial (discovery-based) identification of a minimal core set or by subspace/spectral techniques (TPSR), which estimate a subspace spanning the core tests. For large domains, subspace-based methods offer lower sample complexity but still require the computation of large observable matrices whose size scales with the number of possible histories and tests.
CPSRs: Compressed Sensing for Model Learning
Computational Bottleneck and Motivation
The principal computational bottleneck in subspace-based PSR learning arises from the necessity to compute, store, and invert large matrices whose dimensions are proportional to the number of unique tests and histories observed in training. This is infeasible for systems with large observation spaces, long trajectories, or complex dynamics.
Compression Methodology
The CPSR framework introduces random projections—matrices satisfying the Johnson-Lindenstrauss lemma—to project observables into lower-dimensional compressed feature spaces. Both the test and history vectors are independently mapped onto smaller subspaces, and model estimation proceeds wholly within this compressed domain.
- Batch Learning: Matrix computations are performed directly in compressed space. The algorithm constructs compressed probability matrices by iterating over sampled trajectories and applying the random projections.
- Incremental Learning: CPSR models can be updated incrementally by updating SVDs and compressed counts with new data, supporting online or mini-batch regimes.
A notable advantage is that neither the set of all tests nor the set of all histories must be enumerated or stored, and the random projections are instantiated on-the-fly for encountered elements.
Theoretical Analysis
A rigorous theoretical section establishes that CPSRs are consistent estimators when the projection dimension exceeds the rank of the underlying system, matching prior PSR learning guarantees. For lower-dimensional compressions, the analysis connects the induced bias and variance of the learned model to compressed regression risk bounds, leveraging observed sparsity in real domains and covariance decay of predictive features. The error introduced by random projections is formally quantified, demonstrating controlled bias and reduced variance in the compressed regime.
Planning with CPSRs
CPSRs are integrated into a planning framework via the fitted-Q paradigm. Instead of observable states, CPSR predictive vectors are used as the input to non-linear function approximators (e.g., Extra-Trees) to estimate the action-value function. This enables end-to-end model-based RL in partially observable domains using only observable trajectories, without hand-specified state features.
Empirical Evaluation
Model Quality
Experiments on the ColoredGridWorld domain demonstrate that CPSRs can achieve or even exceed the prediction accuracy of uncompressed TPSRs at long-term prediction horizons, which is attributed to regularization effects of random projection. Strong runtime reductions are shown: model build times for CPSRs are orders of magnitude smaller than those for the uncompressed baseline.
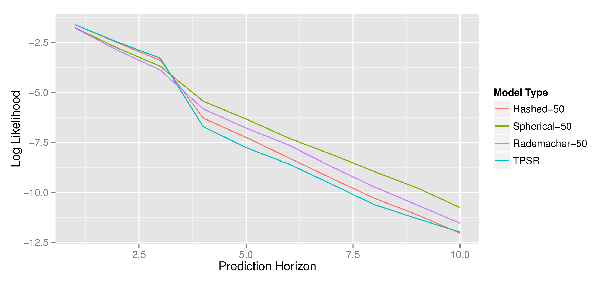
Figure 1: The log-likelihood of test data as a function of prediction horizon for various models; compressed approaches maintain or improve accuracy.
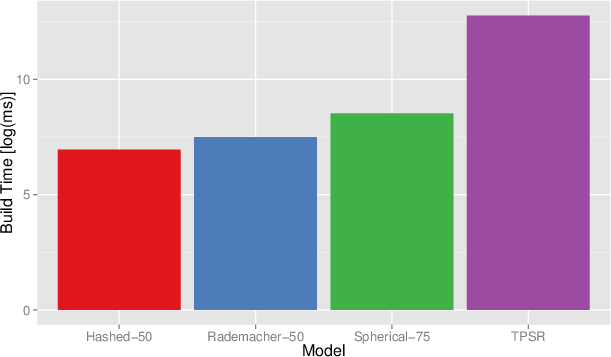
Figure 2: Model construction times (log-scale) indicate drastic efficiency gains for compressed models.
Figure 3 compares the effect of compressing both histories and tests versus only compressing tests, with results showing negligible impact on model likelihood.
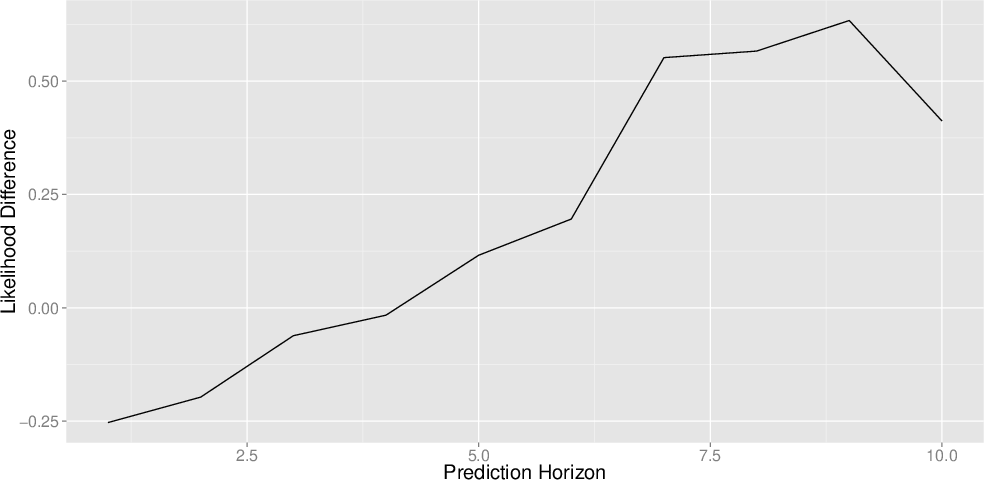
Figure 3: History compression introduces minimal degradation to model likelihood.
Planning experiments are performed on ColoredGridWorld, standard and sparsified (S-PocMan) PacMan, and an adaptive migratory management (AMM) domain:
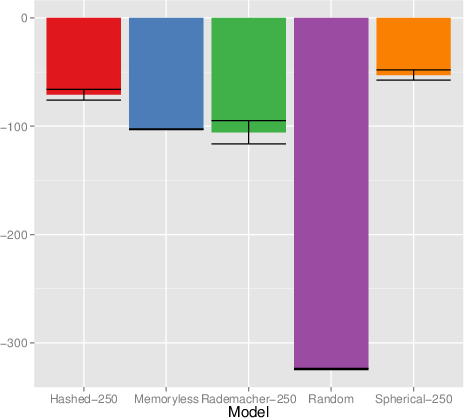
Figure 5: Visualization of the S-PocMan domain structure.
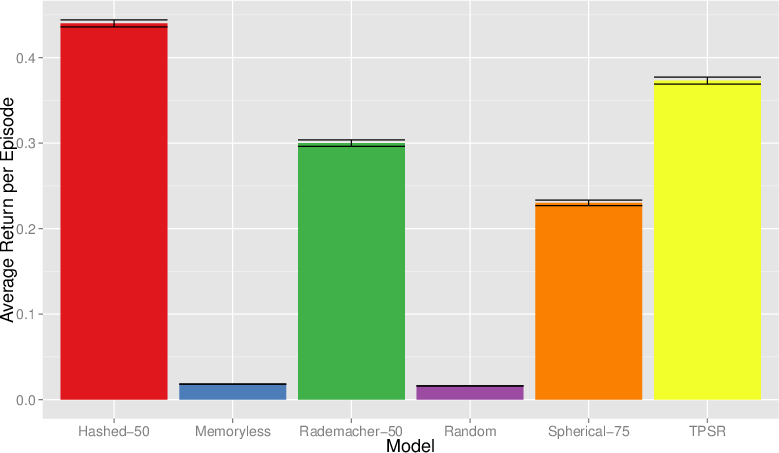
- In S-PocMan, increased partial observability (by removing directional cues and sparsifying reward) restores the supremacy of model-based (CPSR) control.
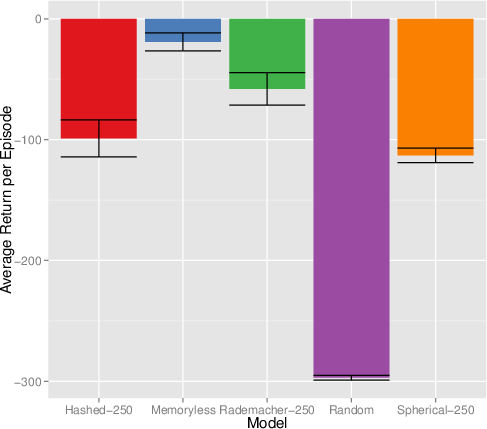
- In the AMM domain, only CPSR-based agents achieve a measurable performance gain over random, as the history dependence, large state space, and non-stationarity preclude effective model-free policies.
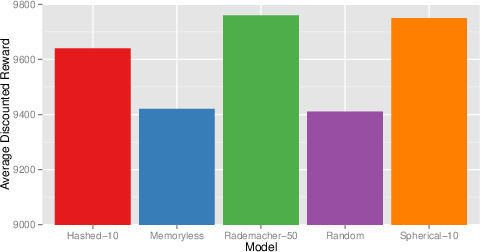
Figure 6: Discounted return per episode in AMM; performance is monotonic with projection dimension for the best models.
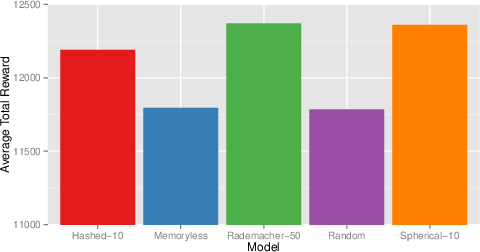
Figure 7: Total undiscounted return per episode in AMM; model-based approaches again dominate.
Across domains, the choice of compression dimension and projection type is shown to affect performance. Planning is more sensitive to these meta-parameters than one-step prediction, presumably due to error propagation in rollouts.
The study elaborates practicalities in implementation: the importance of hyperparameter selection, LRU-caching for projection lookups, and maintaining numerical stability via normalization and SVD truncation. The method is compared and contrasted with feature-based or kernel PSRs, memory-augmented PSRs, U-Tree, and AIXI-style adaptive history models. Critically, while feature- or kernel-based PSR approaches focus on continuous/structured observation spaces, CPSR emphasizes computational scalability and regularization via compression, making principled trade-offs between model bias and variance.
Implications and Future Directions
The work demonstrates that large, partially observable RL problems can be tractably addressed by compressing the predictive state space via random projections without explicit feature engineering. It is empirically shown that in highly aliased domains, memory-based approaches are essential, while in 'nearly observable' domains, simple model-free RL can suffice.
For future research, salient directions include:
- The use of non-least-squares objectives in the implicit regression step, e.g., regularized or robust loss functions, or direct minimization of planning loss.
- Compositional and modular architectures (e.g., hierarchical CPSRs or hybrid approaches integrating with memory-networks).
- Distributed or hardware-optimized implementations for large action/observation spaces, and adaption to continuous observation domains, potentially by combining with domain-specific feature learning or kernel approximations.
- Deeper theoretical investigation of the interaction between compression, planning horizon, and statistical efficiency, especially for non-i.i.d. sampling regimes.
Conclusion
This work establishes compressed predictive state representation as a tractable and theoretically sound mechanism for model-based reinforcement learning in complex POMDPs with large observation and action spaces. CPSRs provide a flexible alternative to classic PSR learning and kernel-based approaches, support both batch and online learning, and deliver effective policies in environments where even domain-specific models are unavailable or infeasible to specify. The empirical results and comprehensive theoretical treatment validate compressed sensing as a key enabling technology for scalable sequential decision-making in partially observable domains.