- The paper demonstrates that compressing reward functions transfers complex goal information to long-term memory, thus enhancing learning efficiency.
- Behavioral experiments show that larger goal spaces impair learning due to working memory constraints, while compressible goal structures mitigate this effect.
- Computational modeling reveals that incorporating reward collection reaction times yields the best predictions for goal-dependent reinforcement learning performance.
Reward Function Compression Facilitates Goal-Dependent Reinforcement Learning
Introduction
This paper presents a formal framework and empirical evidence for the cognitive mechanisms underlying goal-dependent reinforcement learning (RL) in humans, with a particular focus on the role of reward function compression. Unlike standard RL agents that learn from primary or secondary rewards, humans can flexibly assign value to novel, abstract outcomes contingent on current goals. However, this flexibility incurs cognitive costs, primarily due to the limited capacity of working memory (WM). The authors propose that, with repeated experience, humans compress complex goal information into simplified reward functions, which are then transferred to long-term memory, thereby enhancing learning efficiency. The study combines behavioral experiments, computational modeling, and supplementary controls to dissect the trade-offs between flexibility and efficiency in goal-dependent RL.
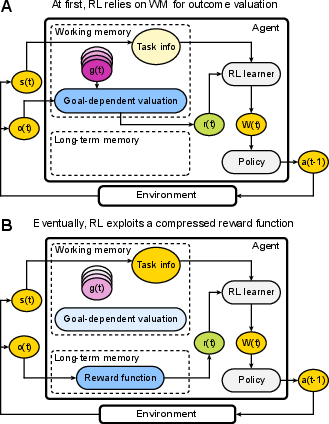
Figure 1: Schematic of goal-dependent learning, illustrating the interaction between RL, WM, and the process of reward function compression and transfer to long-term memory.
Experimental Paradigm and Manipulations
The core experimental paradigm required participants to learn stimulus-response mappings via trial-and-error, with feedback provided either as numeric points (Points blocks) or abstract images labeled as "goal" or "nongoal" (Goals blocks). The critical manipulations involved varying the number and structure of goal outcomes to probe the limits and mechanisms of goal-dependent value attribution.
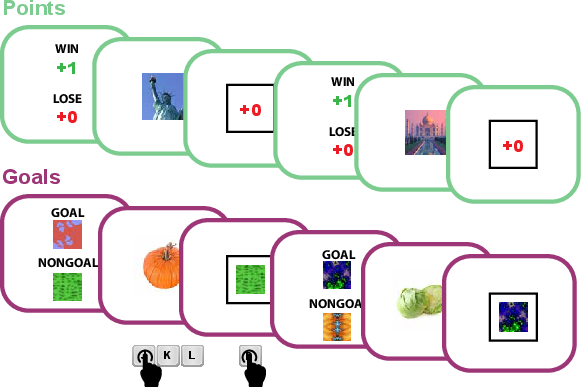
Figure 2: Task structure showing the mapping between stimuli and feedback types in Points and Goals blocks.
Experiment 1: WM Load and Goal Space Size
Experiment 1 tested the hypothesis that increasing the number of unique goals (goal space size) impairs learning due to WM limitations. Participants completed blocks with one, two, three, or four goal/nongoal image pairs. Learning performance decreased parametrically with the number of goal pairs, consistent with WM capacity constraints. Importantly, reward collection accuracy remained high and unaffected by load, indicating that the impairment was not due to failures in outcome identification but rather the cognitive cost of maintaining multiple goal representations.
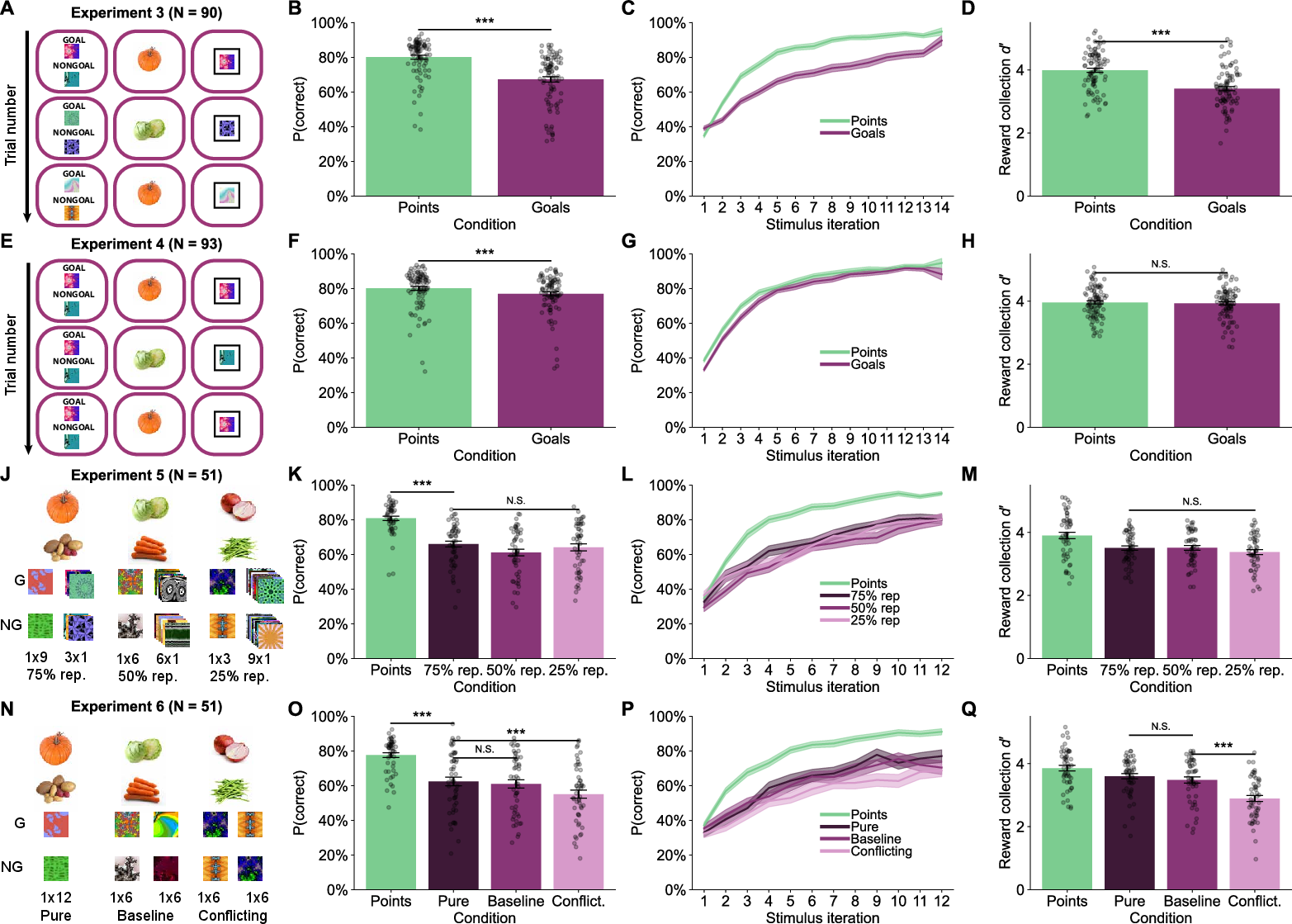
Figure 3: Manipulations and learning performance in Experiment 1, showing parametric decline in accuracy with increasing goal space size.
Experiment 2: Reward Function Compressibility
Experiment 2 held the number of unique goals constant but manipulated whether the goal space was compressible (i.e., could be reduced to a simple rule based on stimulus features). Learning performance was significantly higher in compressible blocks, supporting the hypothesis that reward function compression, not mere repetition, drives efficiency gains. This result rules out interference and repetition-based accounts, highlighting the importance of structural regularity for compression.
Figure 3: Manipulations and learning performance in Experiment 2, demonstrating improved accuracy in compressible goal spaces.
Behavioral Correlates of Reward Function Compression
The authors leveraged reward collection reaction times (RTs) as a behavioral marker of reward function compression. Across experiments, faster reward collection RTs correlated with higher learning performance, suggesting that as reward processing becomes more automatic (i.e., compressed and transferred to long-term memory), more cognitive resources are available for learning. By contrast, choice RTs did not show robust correlations with performance, refuting dual-tasking or interference explanations.
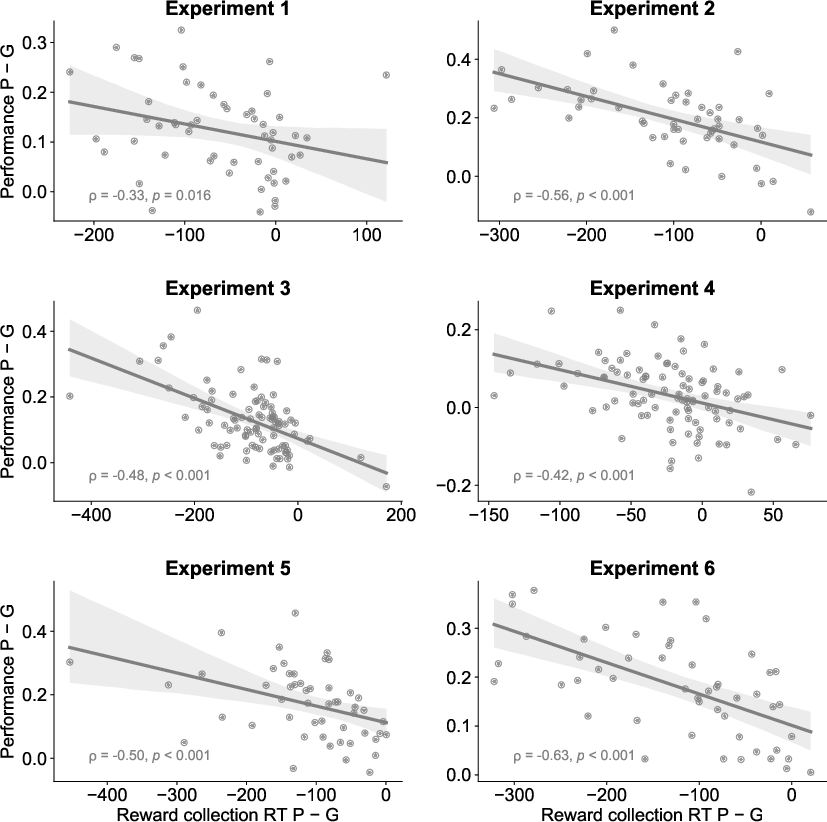
Figure 4: Correlations between performance differences and reward collection RTs across block types, supporting the link between reward processing efficiency and learning.
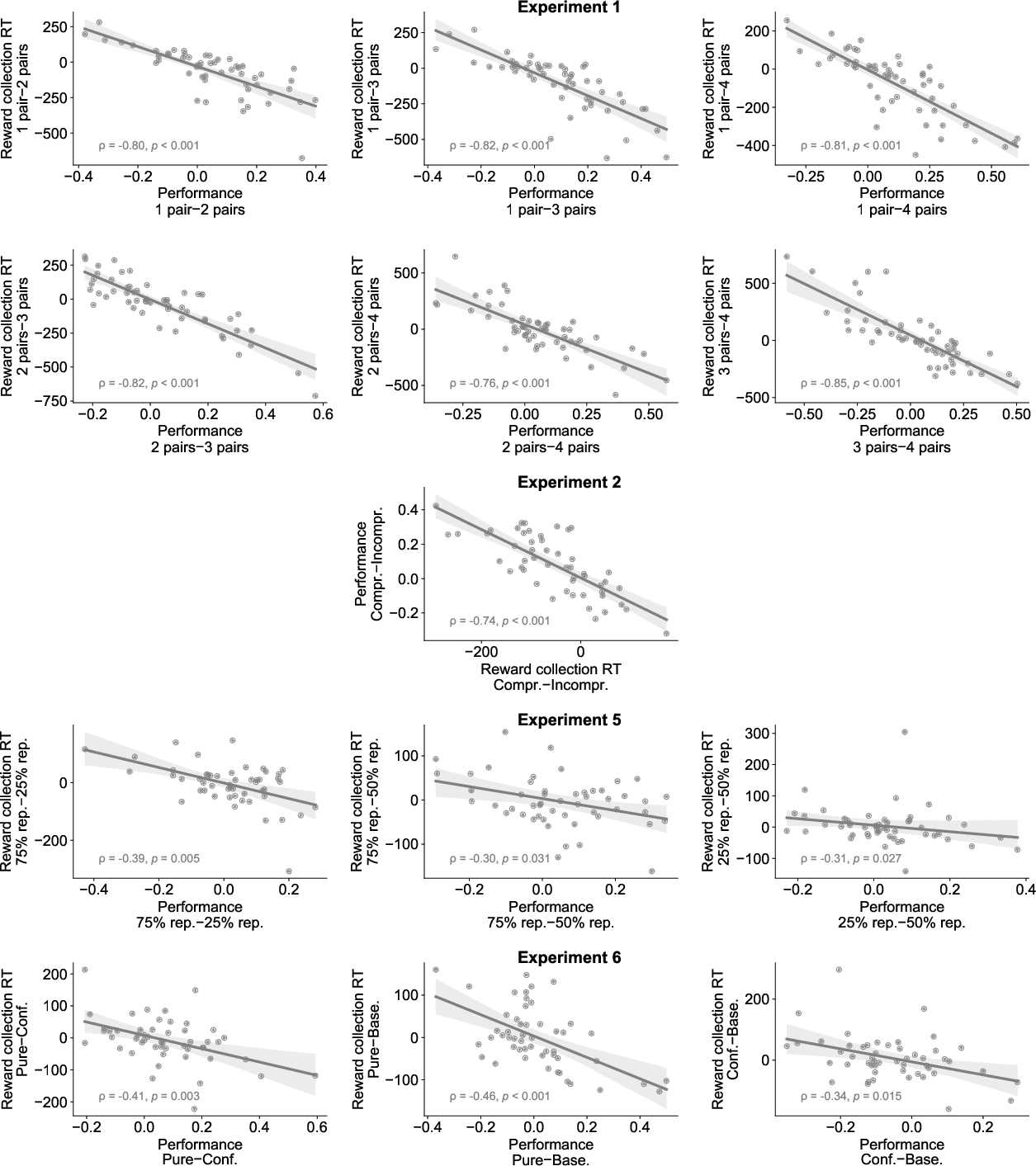
Figure 5: Correlations between performance and reward collection RTs within Goals block conditions, further substantiating the compression hypothesis.
Computational Modeling
A family of RL models was fit to participant data, incorporating mechanisms for outcome-sensitive and outcome-insensitive learning, stickiness, forgetting, and noise. The best-fitting model featured learning rates modulated by reward collection RTs, parameterized by a weighting factor ω. This model parsimoniously captured the observed behavioral effects and outperformed models with free parameters for each condition or those modulating choice noise. Model recovery and parameter recovery analyses confirmed identifiability and robustness.
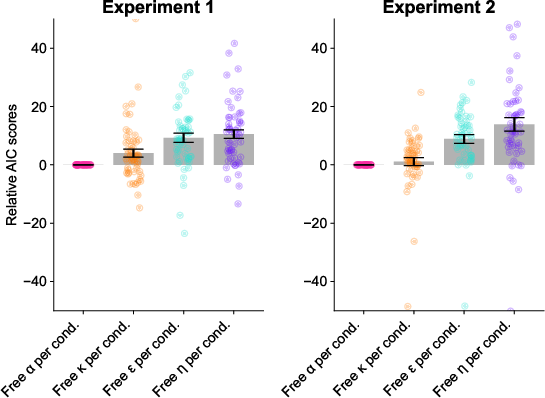
Figure 6: Model comparison for free parameter models across Goal sub-conditions.
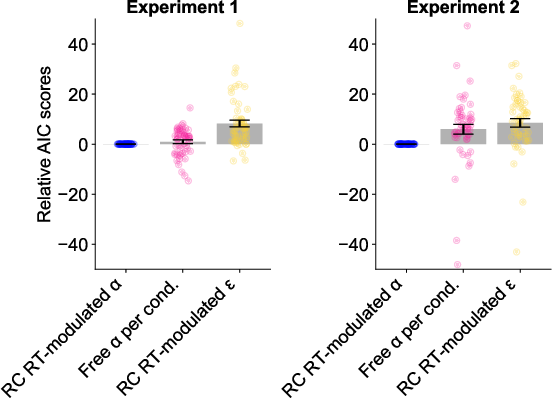
Figure 7: Model comparison for main models, highlighting the superiority of RT-modulated learning rate models.
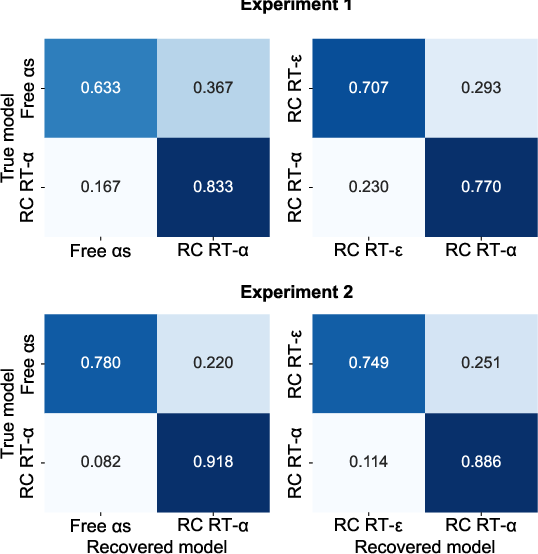
Figure 8: Model recovery confusion matrix, demonstrating reliable identification of the winning model.
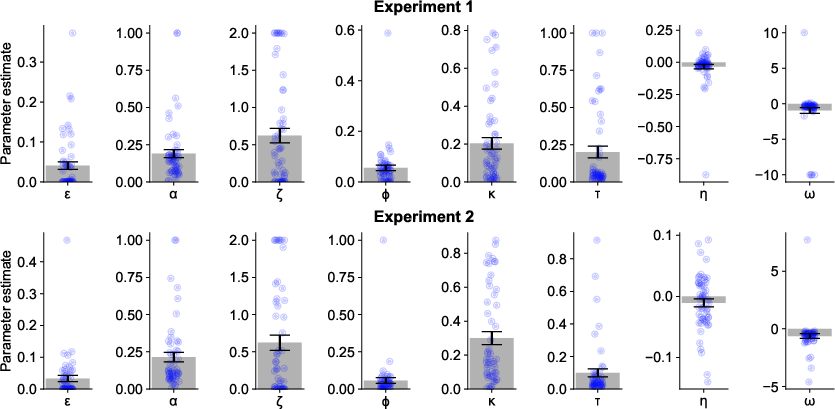
Figure 9: Best-fit model parameters, showing negative ω values and the inverse relationship between reward collection RTs and learning rates.
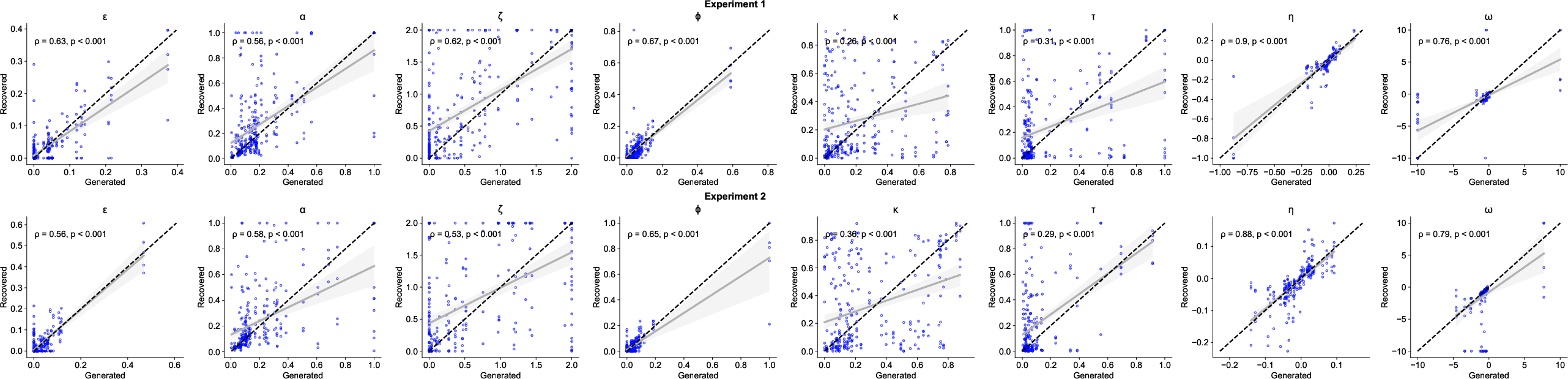
Figure 10: Parameter recovery plots, confirming the reliability of the fitting procedure.
Supplementary Experiments and Controls
Four supplementary experiments addressed alternative explanations:
- Experiment 3: Goal images changed every trial, preventing compression; learning was inefficient but outcome recognition remained high, ruling out encoding lapses.
- Experiment 4: Fixed goal images enabled compression; learning efficiency approached that of standard rewards over time, with increased subjective valuation of goal images.
- Experiment 5: Manipulated goal outcome repetition; no performance gains were observed, refuting repetition-based value caching.
- Experiment 6: Manipulated label consistency; inconsistent goal/nongoal labeling impaired learning, demonstrating the necessity of stable mappings for compression.
Figure 11: Manipulations and performance across Experiments 3-6, illustrating the effects of compression, repetition, and label consistency.
Theoretical and Practical Implications
The findings formalize the cognitive trade-off between flexibility and efficiency in goal-dependent RL. WM supports initial flexible value attribution but is capacity-limited and costly. Reward function compression enables transfer to long-term memory, freeing WM resources and enhancing learning. This mechanism aligns with theories of automatization and instance-based learning, and extends the literature on executive function-RL interactions by specifying the role of reward function construction.
Practically, these results suggest that structuring goals to facilitate compression (e.g., by emphasizing salient, consistent features) can improve learning and motivation. The framework has implications for educational and behavioral interventions, as well as for the design of artificial agents capable of flexible, goal-dependent learning.
Future Directions
Open questions include the generalization of reward function compression to self-imposed and naturalistic goals, the mechanisms of rule extraction and abstraction, and the potential for lossy compression to induce systematic errors in value generalization. Further research should explore the neural substrates of compression and its interaction with primary and secondary reward systems.
Conclusion
This study provides a formal and empirical account of how humans manage the trade-off between flexibility and efficiency in goal-dependent RL. The ability to compress complex goal information into stable reward functions is critical for efficient learning, and is constrained by WM capacity. These insights advance our understanding of intrinsic motivation and have broad implications for cognitive science, neuroscience, and AI.