Is Agentic RAG worth it? An experimental comparison of RAG approaches
Abstract: Retrieval-Augmented Generation (RAG) systems are usually defined by the combination of a generator and a retrieval component that extracts textual context from a knowledge base to answer user queries. However, such basic implementations exhibit several limitations, including noisy or suboptimal retrieval, misuse of retrieval for out-of-scope queries, weak query-document matching, and variability or cost associated with the generator. These shortcomings have motivated the development of "Enhanced" RAG, where dedicated modules are introduced to address specific weaknesses in the workflow. More recently, the growing self-reflective capabilities of LLMs have enabled a new paradigm, which we refer to as "Agentic" RAG. In this approach, the LLM orchestrates the entire process-deciding which actions to perform, when to perform them, and whether to iterate-thereby reducing reliance on fixed, manually engineered modules. Despite the rapid adoption of both paradigms, it remains unclear which approach is preferable under which conditions. In this work, we conduct an extensive, empirically driven evaluation of Enhanced and Agentic RAG across multiple scenarios and dimensions. Our results provide practical insights into the trade-offs between the two paradigms, offering guidance on selecting the most effective RAG design for real-world applications, considering both costs and performance.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper compares two ways to build AI systems that answer questions using outside information, called Retrieval‑Augmented Generation (RAG). Think of RAG like a smart student who, before writing an answer, goes to the library, picks relevant pages, and then writes using those pages.
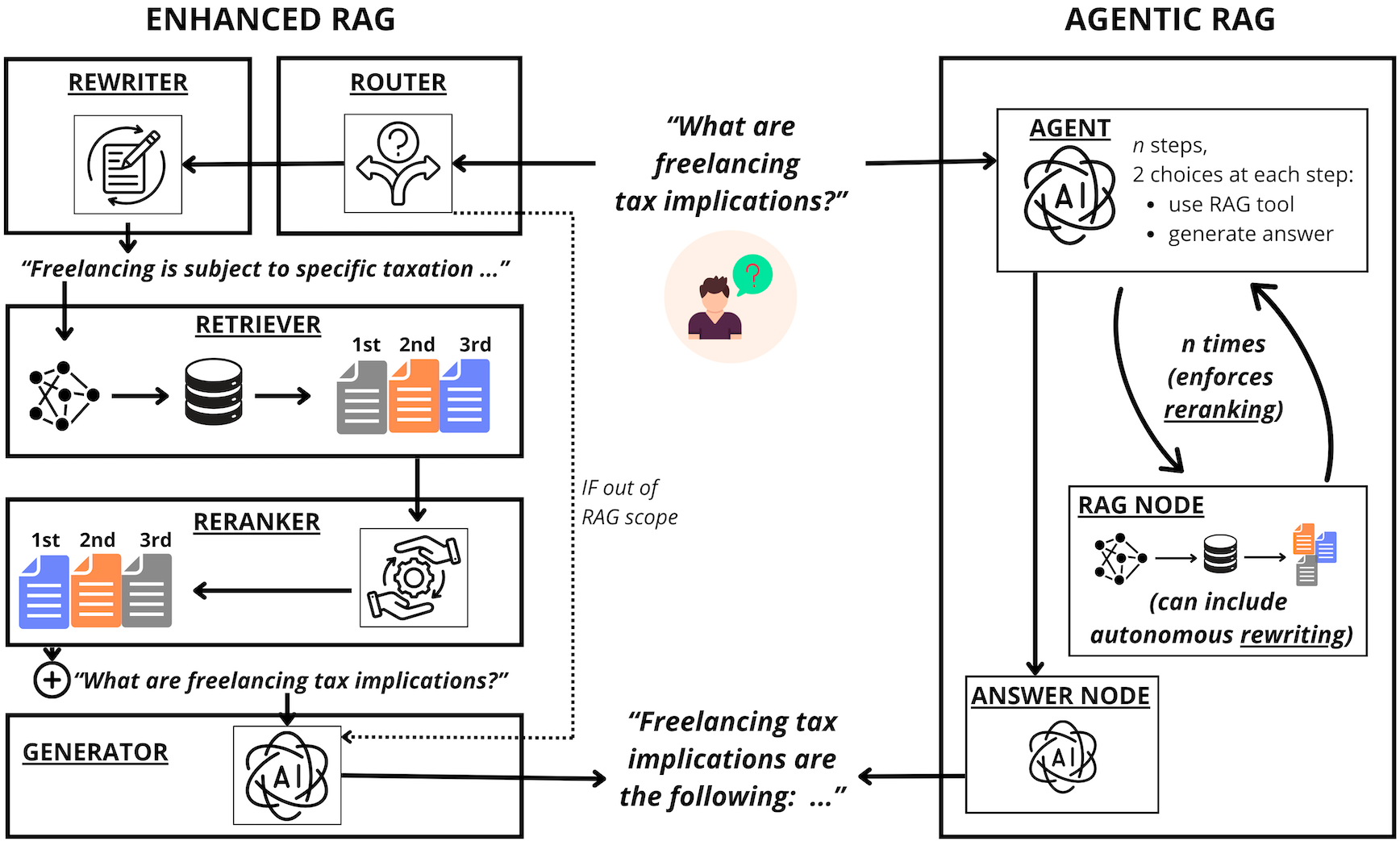
- Enhanced RAG: a fixed, step‑by‑step pipeline with small “helper” tools that improve each step (like a librarian who always follows the same checklist).
- Agentic RAG: the AI acts like a more independent assistant that decides what to do next, when to look things up, whether to rewrite the question, and whether to repeat steps (like a student who plans their own research process).
The big question: In real tasks, which approach works better, costs less, and when?
What were the key questions?
The researchers tested both approaches on realistic tasks and asked four simple questions:
- Can the system tell when it actually needs to look things up (and when it doesn’t)?
- Can it rewrite a messy or short user question into a better search query to find the right documents?
- After it retrieves documents, can it refine that list to keep only the most useful ones?
- How much do results depend on how strong the underlying LLM is (small vs. big models)?
They also measured cost and speed, not just accuracy.
How did they test this?
They set up both systems and ran them on four public datasets that mimic common uses:
- Two question‑answering sets (general and finance questions).
- Two information‑finding sets (checking facts and finding similar Q&A posts).
What the systems looked like:
- Enhanced RAG included specific, fixed helper steps:
- A “router” to decide if retrieval is needed.
- A “query rewriter” (e.g., HYDE) to turn questions into text that’s easier to search for.
- A “retriever” to fetch relevant documents.
- A “reranker” to sort the documents so the best ones are on top.
- Agentic RAG used a single large model to plan its own actions:
- It could choose to retrieve or not.
- It could rewrite the question if it thought it would help.
- It could repeat retrieval to try to improve the context before answering.
How they measured results (in everyday terms):
- Deciding to retrieve or not: Did the system avoid pointless look‑ups?
- Query rewriting quality: Did rewriting help bring back better documents?
- Document refinement: Did the final ranked list keep the most relevant items?
- Model strength: Did using a bigger/smarter model improve things equally for both systems?
- Cost/time: How many “tokens” (roughly, words) were processed and how long did it take? More tokens and steps = more money and time.
What did they find?
- Handling user intent (when to retrieve):
- In focused, well‑defined areas (like finance or grammar), Agentic RAG was slightly better at deciding when to use retrieval.
- In broader, noisier areas (like general fact checking), Enhanced RAG’s simple router was more reliable.
- Takeaway: Agentic is good at “knowing when to look things up” in narrow domains, but Enhanced can be safer in wide‑open topics.
- Query rewriting (turning a question into a better search):
- Agentic RAG did better on average at rewriting queries and pulling in more relevant documents.
- Why? Because it chooses when and how to rewrite, instead of always applying the same rule.
- Document list refinement (keeping only the best evidence):
- Enhanced RAG’s reranker clearly helped—it reliably pushed the best documents to the top.
- Agentic RAG didn’t gain much from repeatedly retrieving; it struggled to beat a good reranker.
- Takeaway: An explicit reranking step is a strong tool that Agentic behavior didn’t consistently replace.
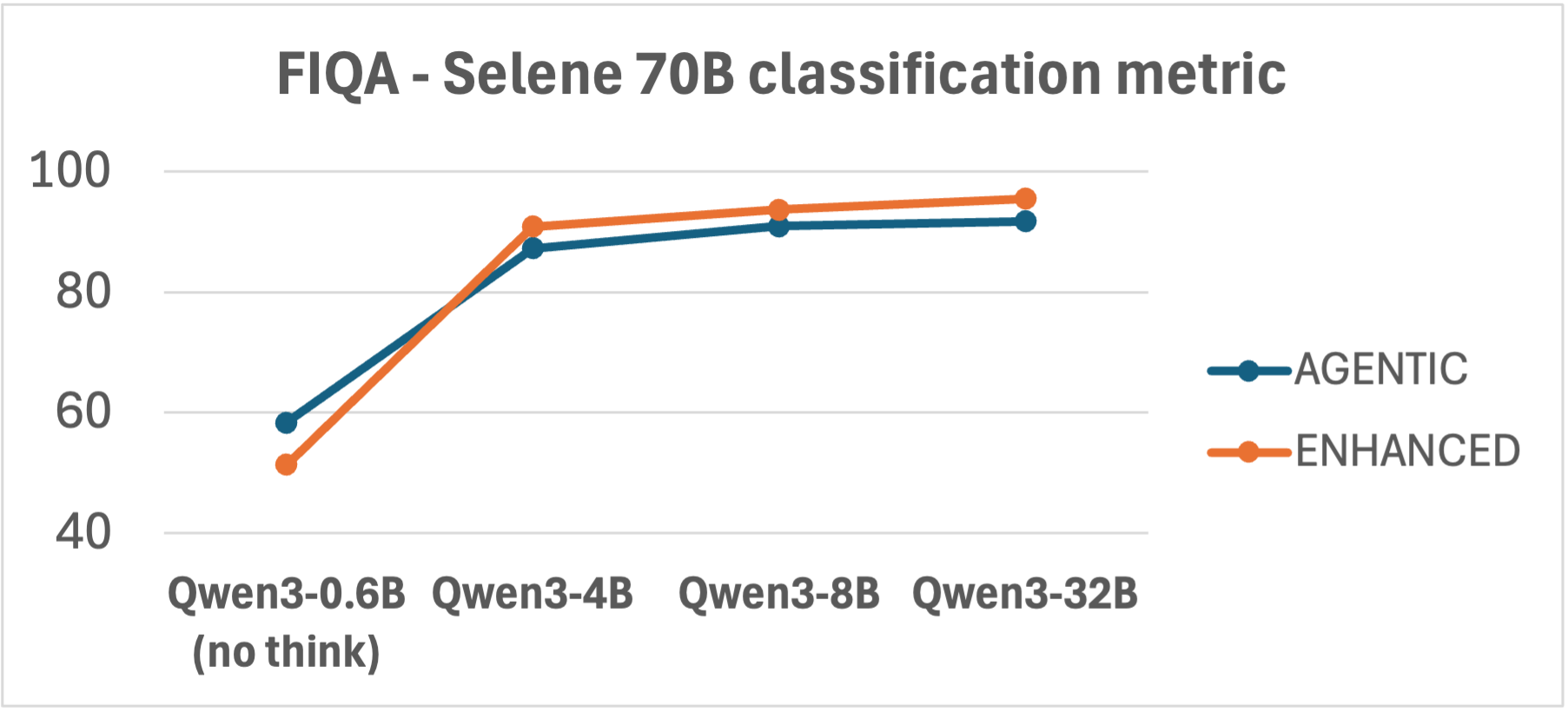
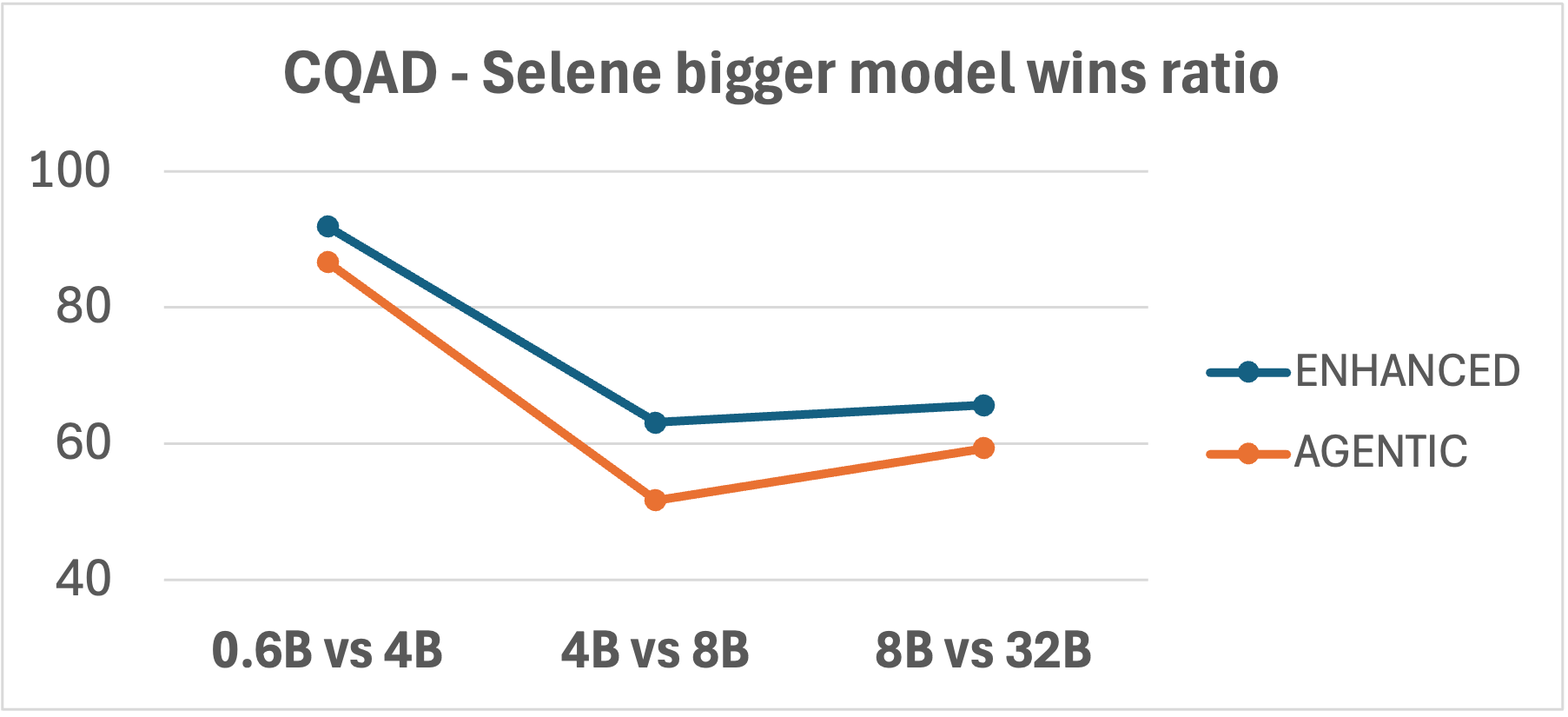
- Dependence on the underlying LLM:
- Both systems improved at similar rates when switching from smaller to larger LLMs.
- Takeaway: Upgrading the base model helps both approaches similarly—you don’t get a special boost just because it’s Agentic or Enhanced.
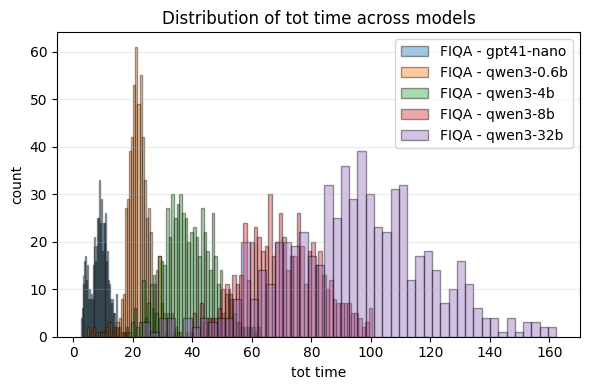
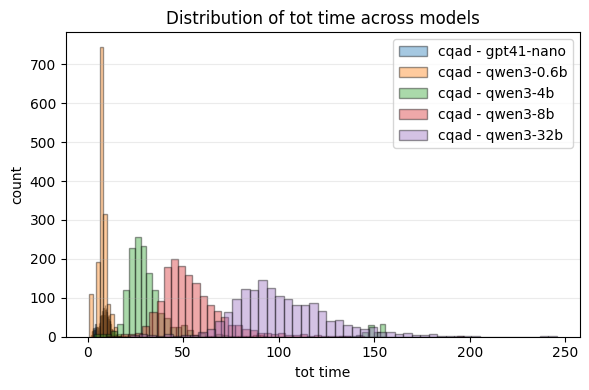
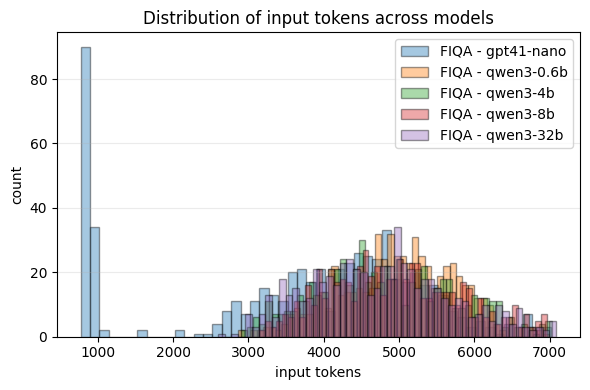
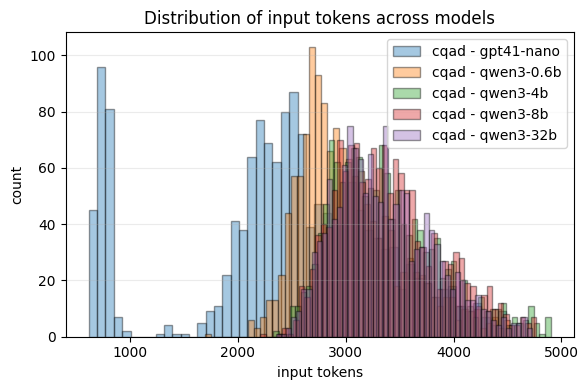
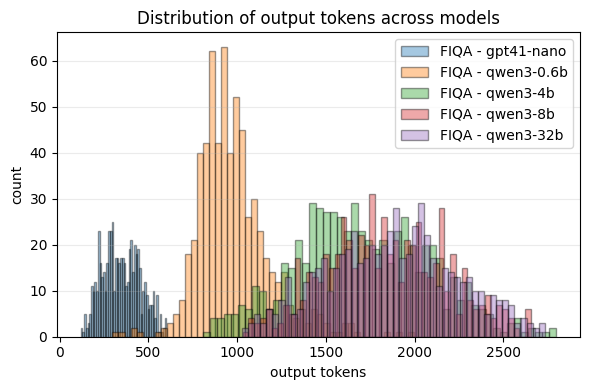
- Cost and speed:
- Agentic RAG used much more compute:
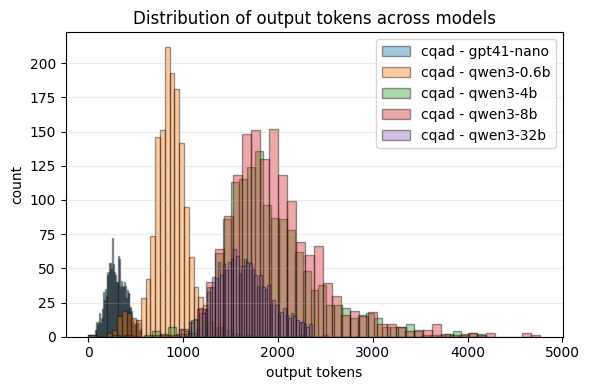
- Around 2.7× to 3.9× more input tokens and up to 2× more output tokens in the tested tasks.
- About 1.5× slower on average.
- Overall, up to about 3.6× more expensive in some cases.
- Takeaway: Agentic’s extra thinking and extra tool calls add noticeable cost and latency.
Why does this matter?
- There isn’t a single “best” RAG design for every situation.
- If your questions come from a narrow domain and you value flexible planning and query rewriting, Agentic RAG can shine.
- If you need predictability, efficiency, and strong evidence selection, a well‑tuned Enhanced RAG (with query rewriting and reranking) can match or beat Agentic performance for less money and time.
- Mixing ideas may help: adding a strong reranking step to Agentic RAG could yield better results.
Simple bottom line
- Agentic RAG = flexible and sometimes smarter about rewriting and deciding when to search, but it often costs more and isn’t always better at picking the best documents.
- Enhanced RAG = steady, efficient, and very good at trimming down to the most relevant evidence, with lower costs and consistent performance.
- Choose based on your needs: domain, budget, and whether you prefer predictable pipelines or more adaptive behavior.
Collections
Sign up for free to add this paper to one or more collections.

