Fantastic Reasoning Behaviors and Where to Find Them: Unsupervised Discovery of the Reasoning Process
Abstract: Despite the growing reasoning capabilities of recent LLMs, their internal mechanisms during the reasoning process remain underexplored. Prior approaches often rely on human-defined concepts (e.g., overthinking, reflection) at the word level to analyze reasoning in a supervised manner. However, such methods are limited, as it is infeasible to capture the full spectrum of potential reasoning behaviors, many of which are difficult to define in token space. In this work, we propose an unsupervised framework (namely, RISE: Reasoning behavior Interpretability via Sparse auto-Encoder) for discovering reasoning vectors, which we define as directions in the activation space that encode distinct reasoning behaviors. By segmenting chain-of-thought traces into sentence-level 'steps' and training sparse auto-encoders (SAEs) on step-level activations, we uncover disentangled features corresponding to interpretable behaviors such as reflection and backtracking. Visualization and clustering analyses show that these behaviors occupy separable regions in the decoder column space. Moreover, targeted interventions on SAE-derived vectors can controllably amplify or suppress specific reasoning behaviors, altering inference trajectories without retraining. Beyond behavior-specific disentanglement, SAEs capture structural properties such as response length, revealing clusters of long versus short reasoning traces. More interestingly, SAEs enable the discovery of novel behaviors beyond human supervision. We demonstrate the ability to control response confidence by identifying confidence-related vectors in the SAE decoder space. These findings underscore the potential of unsupervised latent discovery for both interpreting and controllably steering reasoning in LLMs.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (the big idea)
This paper is about peeking inside LLMs to understand how they “think” when solving problems step by step. Instead of guessing what’s happening from the words they write, the authors look directly at the model’s internal signals to find hidden “dials” that control reasoning behaviors like checking work (reflection) or changing plans (backtracking). Even better, they show we can turn those dials up or down to steer how the model reasons—without retraining it.
What questions did the researchers ask?
- Can we discover different reasoning behaviors inside an LLM automatically, without hand-labeling examples like “this is reflection” or “this is backtracking”?
- Do these behaviors live in neat, separate places inside the model’s internal space?
- If we find the right “directions” (reasoning vectors) inside the model, can we push the model to reflect more, reflect less, backtrack more, or backtrack less?
- Are there other useful behaviors we can uncover—like confidence—that aren’t easy to define by looking at words alone?
- Do these discoveries work across different kinds of tasks, not just math?
How did they study it? (simple explanation of the method)
Think of an LLM as having a control room full of sliders and switches (its internal activations). When the model solves a problem step by step, those sliders move in certain patterns.
Here’s what the authors did:
- Break reasoning into steps
- They asked a reasoning model to solve problems and wrote down each step of its chain-of-thought (like sentences separated by a special marker
\n\n). - For each step, they captured the model’s internal state right at that separator—like taking a snapshot of what the model is “thinking” between steps.
- They asked a reasoning model to solve problems and wrote down each step of its chain-of-thought (like sentences separated by a special marker
- Learn the “parts” of reasoning with a Sparse Autoencoder (SAE)
- An SAE is a special tool that compresses and reconstructs data while using only a few “parts” at a time.
- Imagine you want to build many different LEGO models using the smallest possible set of reusable pieces. The SAE learns those pieces.
- In the model’s control room, each learned “piece” is a direction you can push the sliders—a reasoning vector. Each vector tends to represent a distinct behavior.
- See if the pieces match real behaviors
- They looked at which vectors activate when the model is reflecting or backtracking (using a separate judging model to label steps).
- They visualized the vectors on a 2D map to see if similar behaviors cluster together (they did!).
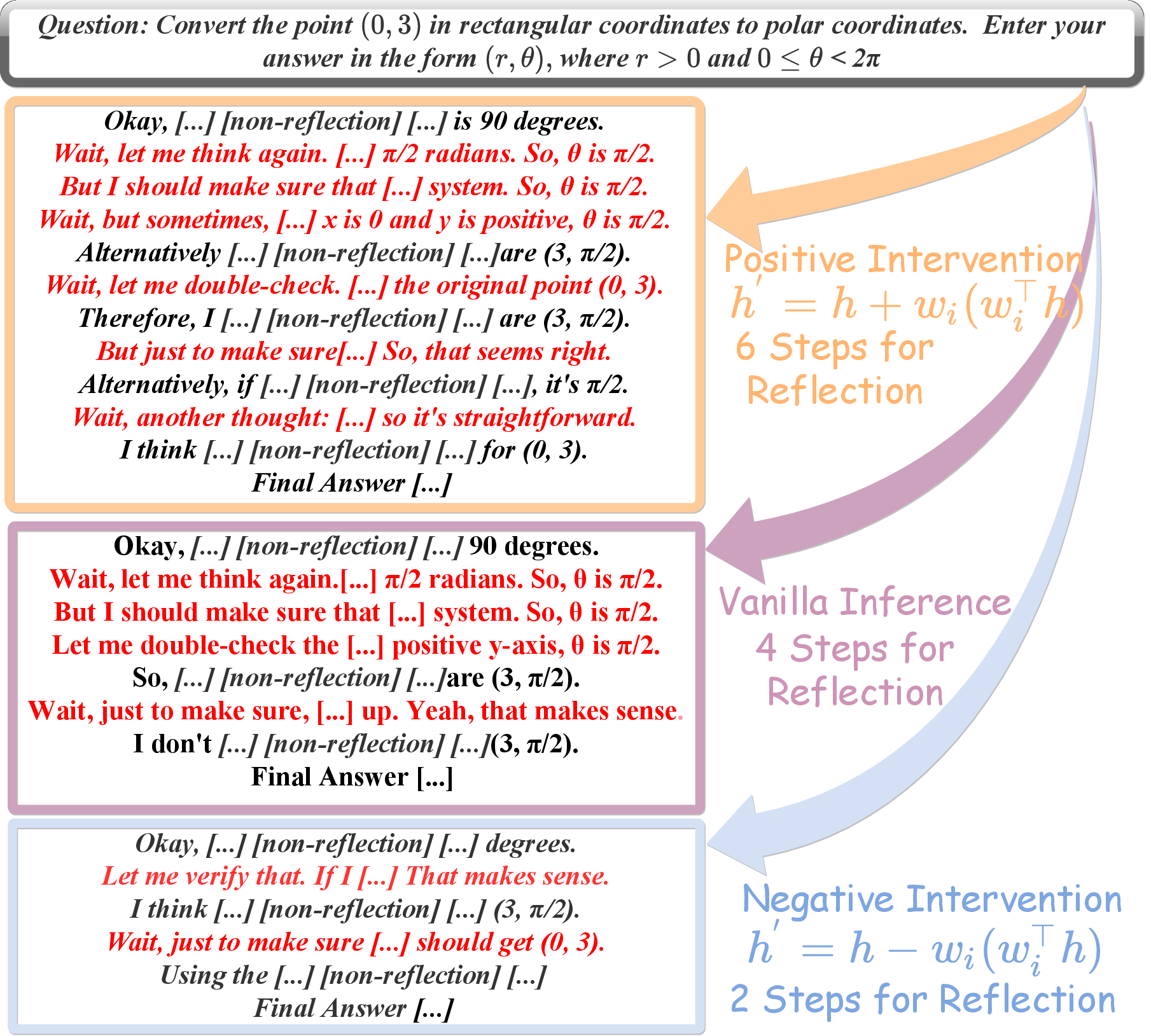
- Try steering the model
- They edited the model’s internal state by adding or removing specific vectors—like turning a dial up or down.
- For example, subtracting the “reflection” vector reduced reflection; adding it increased reflection. This changed how the model reasoned, but often kept the final answer the same.
- Discover new behaviors (like confidence)
- Instead of labeling “confidence” by words, they searched for vectors that make the model’s predictions more certain (lower entropy).
- They found concentrated “confidence” directions that, when applied, made the model write fewer “Wait” or “Alternatively” phrases and more direct calculations.
What did they find, and why is it important?
Here are the main findings:
- Reasoning lives in directions
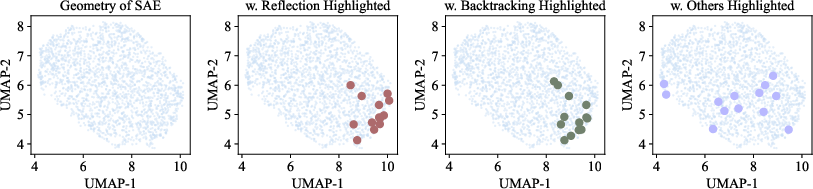
- The SAE discovers clean, separate directions in the model’s internal space that line up with understandable behaviors like reflection and backtracking.
- You can steer reasoning without retraining
- By adding or removing a behavior’s vector during inference, the model shows more or less of that behavior. For instance:
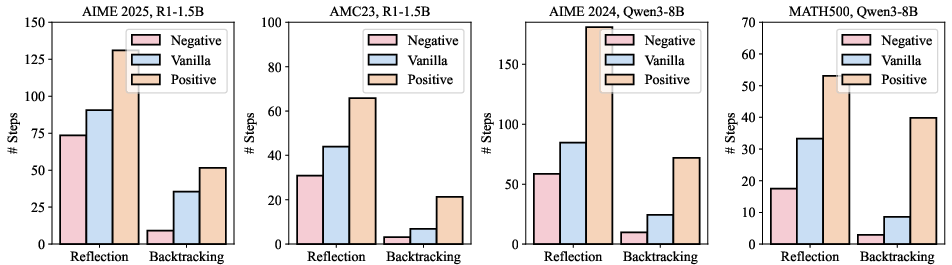
- Turning down reflection led to fewer self-checking steps and shorter solutions.
- Turning it up led to more self-checking and longer solutions.
- The final answers often stayed correct, showing we’re changing style, not just accuracy.
- Behaviors cluster and show structure
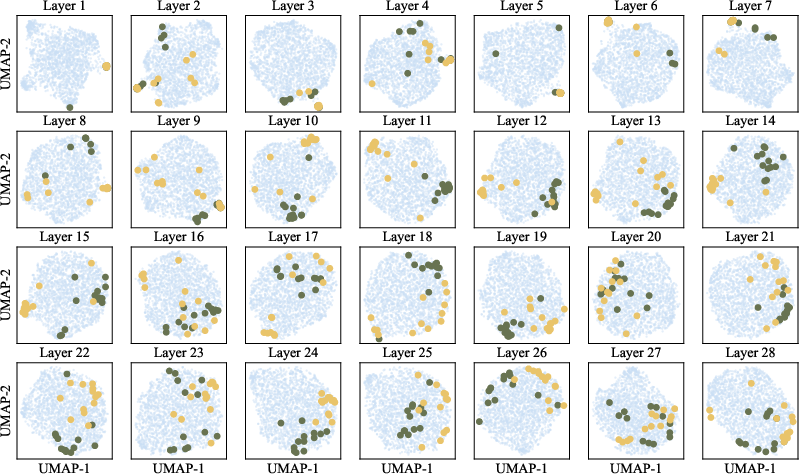
- On a 2D map, vectors for similar behaviors cluster together.
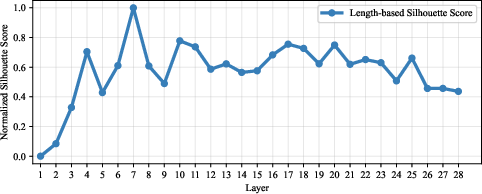
- Mid-to-late layers of the model show the clearest separation between behaviors.
- The model’s internal space also organizes by response length—some vectors align with longer or shorter reasoning.
- New behavior: confidence
- They found “confidence vectors” by optimizing for lower uncertainty.
- Applying these vectors reduced reflection/backtracking words and increased precise math steps.
- This worked across different tasks (math, science, logic), not just the training set.
- Practical gains
- By combining the top confidence vectors and tuning them per question, they improved accuracy and used fewer tokens compared to some existing steering methods.
Why it matters:
- It gives a clearer, testable way to understand how LLMs reason.
- It allows fine-grained control at test time (no extra training), useful for making models faster (less overthinking) or more careful (more checking) depending on the situation.
- It helps us move beyond hand-picked labels to discover new, useful behaviors automatically.
What could this change in the future?
- Smarter, adjustable reasoning: Apps could dial up “careful checking” for safety-critical tasks, or dial it down for speed when the stakes are lower.
- Better transparency: Knowing which internal directions map to which behaviors builds trust and helps diagnose mistakes.
- Efficiency and cost savings: Steering away from unnecessary steps can cut token usage without hurting accuracy.
- New discoveries: The same unsupervised approach could reveal other helpful behaviors we haven’t named yet (like planning quality, doubt handling, or consistency), and let us steer them too.
Key terms in everyday language
- Activation/hidden state: The model’s “brain activity” while thinking.
- Vector/direction: A particular way to nudge that activity—like moving a slider in a specific direction.
- Sparse Autoencoder (SAE): A tool that learns a small set of reusable “thinking pieces,” using only a few at a time so each piece is easier to understand.
- Reflection: The model checks and revisits earlier steps.
- Backtracking: The model abandons a path and tries a new approach.
- Entropy (confidence): Low entropy = high confidence; high entropy = uncertainty.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Step segmentation robustness: The method assumes sentence-level steps detected via the delimiter token
<\n\n>. It is unclear how sensitive discovery and steering are to segmentation choices, tokenization, formatting styles, multilingual text, or models that do not emit such delimiters. Evaluate alternative, model-agnostic step boundary detectors and their impact on SAE features. - Online applicability: The approach extracts step representations by re-running inference with the full question+response to read delimiter activations. Specify and validate an online/streaming procedure for detecting steps and performing interventions without re-feeding completed outputs, including latency and engineering overhead.
- Layer selection and multi-layer modeling: SAEs are trained on a single chosen layer (often late). Systematically assess which layers best capture behavior, whether combining multi-layer SAEs yields better disentanglement/controllability, and how layer choice affects causal interventions.
- Intervention placement and mechanics: Interventions are injected at the last token of each step into the residual stream. Test different injection sites (pre/post layer norm, attention vs MLP blocks, start vs end of steps, all tokens vs last), quantify stability and off-target effects, and characterize impacts on layer norms and activation scaling.
- SAE hyperparameter sensitivity: The decoder size (D=2048), sparsity strength, optimizer, and ReLU gating are chosen heuristically. Perform sensitivity analyses to quantify effects on reconstruction, sparsity, disentanglement, and controllability; establish principled criteria for hyperparameter selection.
- Theoretical assumptions vs practice: The identifiability theorem assumes incoherence, strict sparsity, ReLU, and separated coefficients, and uses an penalty. Verify how closely real hidden states meet these assumptions, clarify the practical sparsity surrogate (e.g., top-k, ), and empirically test identifiability/stability across seeds and datasets.
- Comparative baselines: The paper does not compare SAEs against other unsupervised methods (e.g., ICA, NMF, PCA, subspace identification). Benchmark these alternatives for behavior disentanglement, causal steerability, and interpretability to confirm SAE necessity.
- Behavior labeling validity: Reflection/backtracking labels rely on an LLM-as-a-judge (GPT-5). Quantify label reliability (e.g., with human annotation, inter-annotator agreement, multi-judge consensus), measure labeling bias, and assess how label noise affects conclusions about decoder column semantics.
- Causal validation beyond token-level cues: Current causal evidence uses step counts and token-frequency shifts (“Wait”, “Alternatively”). Develop stronger causal tests (e.g., randomized intervention schedules, placebo controls, causal mediation analyses) and outcome metrics beyond style (accuracy, calibration, self-consistency, error correction).
- Generalization breadth and depth: SAEs trained on MATH500 were applied to GPQA-Diamond/KnowLogic. Expand evaluation to diverse domains (coding, planning, dialogue, multilingual), more task families, and larger model sizes; report accuracy, efficiency, and calibration under domain shift with statistical significance.
- Confidence vector risks: Minimizing entropy may induce overconfidence or suppress useful metacognition. Measure calibration (ECE, NLL), error rates on hard cases, hallucination risk, and the trade-off between confidence and correction, including tasks where reflection/backtracking is beneficial.
- Distinguishing epistemic confidence from style: Token-level shifts (numbers vs “Wait/Alternatively”) may reflect stylistic changes rather than true confidence. Design probes or behavioral tests that separate epistemic certainty from linguistic style and quantify the relationship to correctness.
- Length geometry and causal control: Length emerges as a structural axis, but causal control of length was not demonstrated. Identify length vectors and test whether steering can compress/extend reasoning without harming accuracy; characterize the trade-offs between length, correctness, and efficiency.
- Column purity and disentanglement: The method filters columns active across multiple behaviors and averages behavior-specific columns. Define and measure column “purity” (e.g., orthogonality, selectivity, mutual information with labels), and develop algorithms to deconfound overlapping features.
- Multi-objective steering: Steering single behaviors can affect others (e.g., confidence overlaps with reflection/backtracking). Study multi-objective control (e.g., Pareto trade-offs), interference between vectors, and methods for constrained or compositional steering.
- Stability of discovered dictionaries: Assess how SAE columns vary across random seeds, training subsets, and annotation protocols; quantify stability and reproducibility by aligning columns across runs and measuring consistency of behavior clusters.
- Scaling and compute: Training SAEs at scale (larger models, more layers, bigger datasets) may be memory-intensive. Characterize computational costs, propose efficient/streaming training, and evaluate performance-compute trade-offs.
- Safety and ethics of steering metacognition: Suppressing reflection/backtracking may reduce self-correction and increase harm. Evaluate safety impacts on adversarial, sensitive, or high-stakes tasks; assess fairness and privacy implications of activation edits.
- Integration with training: Explore whether discovered vectors can guide fine-tuning/RL (e.g., regularizing toward or away from specific behaviors), improve reward modeling, or enable curriculum strategies that align structural and semantic features.
- Multimodal extension: The approach is text-only. Investigate whether SAE-based behavior discovery and steering generalize to multimodal reasoning (vision-language, speech), and how representations and step segmentation should be adapted.
- Metrics beyond UMAP/Silhouette: UMAP visualizations can be misleading. Introduce intrinsic geometry metrics (e.g., representational similarity analysis, linear probes, information-theoretic measures) to validate cluster separability and semantic alignment.
- Production constraints: Document how to deploy RISE in real systems (APIs, streaming inference, latency budgets), including failure modes, monitoring for off-target effects, and fallback strategies when steering degrades performance.
- Code/data release and reproducibility: The paper lacks public artifacts. Release code, SAE checkpoints, labeled steps, and evaluation scripts to enable replication; specify dataset splits, seeds, and exact prompts used for annotation and intervention.
Practical Applications
Below are practical applications that can be derived from the paper’s findings on RISE (Reasoning behavior Interpretability via Sparse auto-Encoder). Each item notes sector relevance, potential tools/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These can be deployed now with access to model activations and modest engineering.
Cross-sector: Serving-time reasoning control
- Action: Wrap LLM inference with a RISE steering middleware to suppress or amplify specific reasoning behaviors (e.g., reflection, backtracking) and adjust response length and confidence, by injecting SAE-derived vectors at sentence-step delimiters.
- Sectors: Software, education, finance, customer support, research platforms.
- Tools/Workflows: “Meta-cognition knobs” (UI sliders for reflection/backtracking/length/confidence); per-prompt policies (e.g., concise mode, thorough mode); A/B testing harness for accuracy–token cost trade-offs.
- Assumptions/Dependencies: Access to hidden states; ability to hook into residual streams and sentence-step delimiters; per-model/layer SAE training; intervention strength tuning to avoid accuracy loss.
Efficiency and token-budget governance
- Action: Reduce overthinking and verbose CoT via negative interventions on reflection/backtracking or by steering toward confidence vectors; enforce token budgets while maintaining accuracy.
- Sectors: Enterprise LLM deployment, cloud inference, mobile/on-device assistants.
- Tools/Workflows: Token Budget Governor; adaptive verbosity controller; automatic early-exit triggers guided by confidence-related vectors.
- Assumptions/Dependencies: Behavior vectors generalize across domains (supported by GPQA/KnowLogic results, but monitor accuracy); telemetry on accuracy/tokens; policy for graceful fallback when steering is counterproductive.
Reasoning analytics and interpretability dashboards
- Action: Provide UMAP-based visualizations of decoder columns, cluster labels (reflection/backtracking/other), length-aware axes, and per-prompt behavior activations for audit and debugging.
- Sectors: Model interpretability teams, academic labs, AI platform providers.
- Tools/Workflows: Reasoning Analytics Dashboard; Silhouette-based separability reports across layers; behavior frequency counters per task.
- Assumptions/Dependencies: Stable SAE geometry per layer; LLM-as-a-judge labeling for validation; access to step-level activations and logs.
Education: Adaptive tutoring styles
- Action: Adjust tutors to be more concise or more self-checking; enable “Try alternatives” mode (backtracking) for exploration vs. “Be decisive” mode (confidence) for mastery checks.
- Sectors: EdTech, institutional learning platforms.
- Tools/Workflows: Student-facing sliders (“Explore vs. Confirm,” “Verbose vs. Concise”); teacher dashboards showing model reflection/backtracking occurrences; metacognitive training modules that expose when and why the model reflects.
- Assumptions/Dependencies: Safety guardrails to prevent overconfident errors; domain-specific tuning of vectors for math vs. writing vs. logic.
Software engineering assistants
- Action: Modulate code assistant behaviors: suppress unnecessary rambling; amplify backtracking when searching alternatives; increase confidence for routine tasks.
- Sectors: Developer tools, CI/CD systems.
- Tools/Workflows: IDE plugins with steering controls; CI “decisiveness profiles” for routine refactors; bug triage modes that increase backtracking to explore more fixes.
- Assumptions/Dependencies: Reliable sentence-step delimitation in code reasoning; continuous monitoring for correctness regressions.
Finance and operations decision support
- Action: Calibrate confidence and reflection based on risk appetite: increase reflection for high-stakes analyses; reduce verbosity to meet SLAs for routine tasks.
- Sectors: Finance, operations, procurement.
- Tools/Workflows: “Risk-aware reasoning profiles” tied to task types; audit logs of reasoning behaviors; compliance-ready reports showing reduced overthinking or increased checks on critical items.
- Assumptions/Dependencies: Policy alignment; human-in-the-loop validation; clear thresholds for steering strength.
Healthcare and clinical documentation (non-diagnostic support)
- Action: Control reasoning verbosity in clinical documentation assistants; increase reflection when summarizing complex charts; reduce meta-cognition in routine notes to save time.
- Sectors: Healthcare IT.
- Tools/Workflows: EHR-integrated reasoning control; behavior logs for compliance audits; profile presets (routine vs. complex cases).
- Assumptions/Dependencies: Strict validation; medical safety constraints; avoid using steering alone for diagnostic decisions.
Research workflows
- Action: Use RISE to mine new behaviors and structure (e.g., length axis) for benchmarking; test causal effects on reasoning styles across tasks and models; curate datasets based on behavior profiles.
- Sectors: Academia, industrial research.
- Tools/Workflows: Behavior mining pipelines; cross-model latent catalogs; per-layer separability analyses.
- Assumptions/Dependencies: Per-model SAE training; robust cross-domain checks; reproducible labeling protocols.
Long-Term Applications
These require further research, scaling, or standardization before broad deployment.
Standardized “Reasoning Control API”
- Action: Define an industry-standard interface for behavior vectors (reflection/backtracking/length/confidence) and steering primitives (projection, addition, strength).
- Sectors: AI platform vendors, open-source ecosystems.
- Tools/Workflows: SDKs for model-agnostic steering; registry of behavior vectors per model/layer; configuration-as-code for reasoning profiles.
- Assumptions/Dependencies: Broad access to activations across providers; consistent step delimiters; governance for safe defaults.
Training-time integration and alignment
- Action: Use SAE-derived behavior vectors as auxiliary objectives or regularizers in fine-tuning/RL to shape models toward concise, confident, or reflective styles as desired.
- Sectors: Model training/finetuning providers.
- Tools/Workflows: Behavior-aware RLHF/RLAIF; curriculum design using discovered latent axes; distillation that transfers desirable vectors from reasoning models to base models.
- Assumptions/Dependencies: Stable identifiability of vectors during training; avoidance of harmful bias (e.g., excessive confidence); evaluation for robustness.
Adaptive compute orchestration and early exit
- Action: Couple confidence vectors with dynamic early-exit policies and per-step compute allocation (think-when-needed); allocate test-time compute based on entropy/behavior signals.
- Sectors: Cloud inference, embedded systems, cost-sensitive deployments.
- Tools/Workflows: Policy engines that gate further steps if confidence is sufficient; elastic CoT controllers; multi-pass strategies that expand steps only when signals indicate need.
- Assumptions/Dependencies: Reliable confidence–accuracy correlation per domain; safeguards against premature exits; latency-accuracy trade-off management.
Safety and governance monitoring
- Action: Continuous auditing of reasoning styles for signs of deceptive or brittle patterns; guardrails that reduce entropy when the model exhibits risky behavior (e.g., backtracking loops).
- Sectors: Policy, compliance, safety engineering.
- Tools/Workflows: Behavior anomaly detectors; compliance dashboards; intervention templates for high-risk prompts.
- Assumptions/Dependencies: Clear operational definitions of “risky” behaviors; approval workflows; evidence that steering mitigates risk without masking errors.
Multimodal and robotics extensions
- Action: Generalize behavior vectors to vision-LLMs and planners to control decisiveness, exploration (backtracking), and plan verbosity; reduce compute in embedded robotics.
- Sectors: Robotics, autonomous systems, industrial automation.
- Tools/Workflows: Planning style regulators; exploration–exploitation knobs; mission-time controllers that enforce concise reasoning under constraints.
- Assumptions/Dependencies: Multimodal adaptation of step delimitation; safe-task validation; hardware-aware latency controls.
Productization in enterprise platforms
- Action: Ship “Reasoning Editor” features across LLM platforms: sliders for reflection/backtracking/length/confidence; per-team profiles; analytics on behavior–outcome relationships.
- Sectors: SaaS AI suites, productivity platforms.
- Tools/Workflows: Organization-level presets; role-specific reasoning styles (analyst vs. support agent); outcome-linked dashboards.
- Assumptions/Dependencies: UX that conveys trade-offs; privacy-compliant logging; cross-task generalization of behavior vectors.
Cross-model latent behavior catalogs
- Action: Build shared catalogs of behavior vectors that transfer across models; map correspondences between layers and latent spaces to enable portability.
- Sectors: Open-source communities, benchmarking consortia.
- Tools/Workflows: Alignment pipelines; vector matching across models; public repositories with metadata (layer, domain, effect sizes).
- Assumptions/Dependencies: Sufficient structural similarity between models; robust mapping methods; licensing and IP considerations.
Sector-specific validated deployments (high stakes)
- Action: Deploy rigorously validated steering in healthcare diagnostics, legal analysis, and regulated finance to balance reflection, decisiveness, and verbosity.
- Sectors: Healthcare, legal, finance.
- Tools/Workflows: Clinical/forensic validation studies; fail-safe thresholds; human-in-the-loop workflows.
- Assumptions/Dependencies: Strong evidence for calibration and safety; regulatory approval; continuous monitoring and rollback mechanisms.
Overall assumptions and dependencies shared across applications:
- Access to internal activations and the ability to inject steering vectors during inference.
- Reliable sentence-step delimitation (the paper uses a delimiter token such as “<\n\n>”).
- Per-model and per-layer SAE training (mid-to-late layers often yield better separability; oversmoothing near final layers may reduce distinctness).
- Steering strength must be tuned to prevent accuracy degradation; behavior effects can be task- and domain-dependent.
- Ethical constraints: avoid amplifying unwarranted confidence; ensure human oversight in high-stakes contexts.
Glossary
- Activation patching: An activation-level editing technique that replaces or modifies internal activations to study or control model behavior. "Activation steering modifies model outputs by editing internal activations, with notable approaches including representation engineering~\citep{zou2310representation}, activation patching~\citep{meng2022locating}, and DiffMean~\citep{marks2023geometry}."
- Activation space: The vector space of internal model activations where directions can encode semantic or behavioral features. "discovering reasoning vectors, which we define as directions in the activation space that encode distinct reasoning behaviors."
- Activation steering: Modifying a model’s output by directly editing its internal activations along targeted directions. "Activation Steering. Activation steering modifies model outputs by editing internal activations, with notable approaches including representation engineering~\citep{zou2310representation}, activation patching~\citep{meng2022locating}, and DiffMean~\citep{marks2023geometry}."
- Adam optimizer: A stochastic optimization method that uses adaptive moment estimates for efficient training. "We use the Adam optimizer~\citep{kingma2014adam} with cosine annealing learning rate decay."
- argmin: The argument (input) that minimizes a given function; commonly used in optimization objectives. "\argmin_{S} \; \mathbb{E}!\left[- \sum_{k=1}{|V|} p_k \log p_k \right]"
- Backtracking: A reasoning behavior where the model abandons a current path and attempts an alternative approach. "backtracking (i.e., the model abandons the current reasoning path and pursues an alternative solution)"
- Chain-of-Thought (CoT) prompting: A prompting strategy that elicits multi-step reasoning traces from LLMs. "Chain-of-Thought (CoT) prompting~\citep{wei2022chain}"
- Confidence vectors: Directions in activation space that reduce output entropy and steer the model toward more confident reasoning. "Generalization of confidence vectors across data domains under different steering directions."
- Cosine annealing learning rate decay: A schedule that reduces the learning rate following a cosine curve over training. "We use the Adam optimizer~\citep{kingma2014adam} with cosine annealing learning rate decay."
- Cosine similarity: A metric that measures directional similarity between vectors, often used for embedding comparisons. "We adopt UMAP for visualization because it leverages cosine similarity as the internal metric, emphasizing directional rather than Euclidean differences."
- Decoder column space: The subspace spanned by the columns of an autoencoder’s decoder matrix, interpreted as feature directions. "Visualization and clustering analyses show that these behaviors occupy separable regions in the decoder column space."
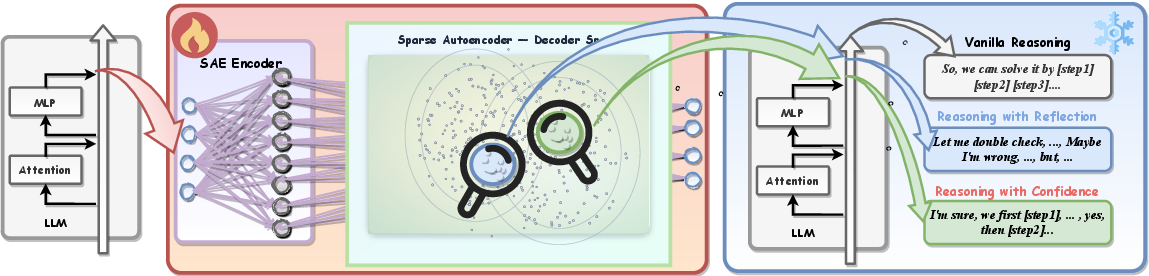
- Decoder columns: Individual columns of the decoder matrix that act as atomic feature directions for reconstruction and steering. "We show that individual decoder columns correspond to interpretable reasoning behaviors (Figure~\ref{fig:method})."
- Decoder matrix: The linear transformation in an autoencoder that reconstructs inputs from latent codes; its columns represent learned features. "recovers a decoder matrix whose columns align with the true dictionary up to permutation matrix and scaling diagonal matrix :"
- Difference-of-Means (DiffMean): A supervised method that computes a steering direction by subtracting the mean activation of one class from another. "From the perspective of mechanistic interpretability, many studies rely on activation engineering methods, particularly the Difference-of-Means (DiffMean) approach~\citep{marks2023geometry}."
- Dictionary (sparse coding): A set of basis vectors used to represent inputs sparsely via linear combinations. "is a dictionary of latent behavior directions"
- Entropy: A measure of uncertainty in the model’s output distribution; lower entropy indicates higher confidence. "we adopt entropy as our proxy objective"
- Incoherence: A dictionary property limiting pairwise correlations between atoms to enable sparse recovery and identifiability. "Assume: (i) Incoherence: ."
- k-sparse code: A latent representation with at most k nonzero entries, promoting interpretability via sparsity. "a is a -sparse code"
- Latent space: The space of learned codes or features where semantic behaviors can be disentangled and manipulated. "Figure~\ref{fig:sae_semantic} illustrates that the SAE decoder columns encode semantically meaningful behaviors in the latent space."
- Linear Representation Hypothesis: The view that abstract features are linearly encoded in model activations and can be isolated as directions. "Building on the Linear Representation Hypothesis~\citep{olah2024linear,park2023linear}"
- LLM-as-a-judge: Using an LLM to label or evaluate model outputs or steps according to specified criteria. "The classification is performed using an LLM-as-a-judge approach"
- Mechanistic interpretability: Methods aiming to explain model behavior via internal mechanisms like circuits, features, and activation geometry. "From the perspective of mechanistic interpretability, many studies rely on activation engineering methods"
- Oversmoothing phenomenon: The tendency for deep transformer layers to make token representations overly similar, reducing separability. "This observation aligns with the oversmoothing phenomenon in current LLMs~\citep{wang2023pangu}"
- Permutation matrix: A matrix that reorders basis vectors; used to express equivalence up to reindexing of decoder columns. "up to permutation matrix and scaling diagonal matrix :"
- Prefilling stage: The initial phase of inference where context is processed before generating tokens; parameters or biases may be adapted here. "learns a bias term at test time during the prefilling stage"
- ReLU: A non-linear activation function defined as max(0, x), used to induce sparsity in codes. "For a standard SAE~\citep{cunningham2023sparse}, we use as the non-linear activation function ."
- Residual stream: The main vector pathway in transformer layers where token representations accumulate via residual connections. "We specifically use the residual stream representations after each transformer layer"
- Representation engineering: Editing or steering internal representations to control model behavior. "Activation steering modifies model outputs by editing internal activations, with notable approaches including representation engineering~\citep{zou2310representation}"
- RISE: The paper’s framework: Reasoning behavior Interpretability via Sparse auto-Encoder, for unsupervised discovery and control of reasoning vectors. "we propose an unsupervised framework (namely, RISE: Reasoning behavior Interpretability via Sparse auto-Encoder) for discovering reasoning vectors"
- SAE (Sparse Auto-Encoder): An autoencoder trained with sparsity constraints to learn disentangled features aligned with semantic behaviors. "we employ sparse auto-encoders (SAEs), which learn a dictionary of sparse latent features that reconstruct hidden states while promoting disentanglement."
- Silhouette score: A clustering metric measuring cohesion and separation to quantify cluster quality. "Then, we quantify the above analysis by Silhouette scores~\citep{Rousseeuw87jcam_Silhouettes,shahapure2020cluster}."
- Softmax: A function converting logits into a probability distribution over tokens. "p_k = \mathrm{softmax}!\big(f_{l \to L}(h + S W_{\mathrm{decoder})\big)_k"
- Sparsity: The property of having few active features or nonzero code entries; often enforced via L0 penalties. "which encourages the SAE to accurately reconstruct the original activations while enforcing sparsity in the latent codes."
- Steering vector: A direction added or projected in activation space to shift model behavior along a desired axis. "The resulting steering vector can then be applied to shift the response style"
- Test-time scaling: Increasing compute at inference (e.g., more samples or longer reasoning) to boost performance. "test-time scaling~\citep{snell2024scaling}"
- UMAP: Uniform Manifold Approximation and Projection; a dimensionality reduction method emphasizing local/global structure via a graph-based approach. "we apply Uniform Manifold Approximation and Projection (UMAP)~\citep{mcinnes2018umap} to embed the decoder columns into a two-dimensional space."
Collections
Sign up for free to add this paper to one or more collections.

