Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
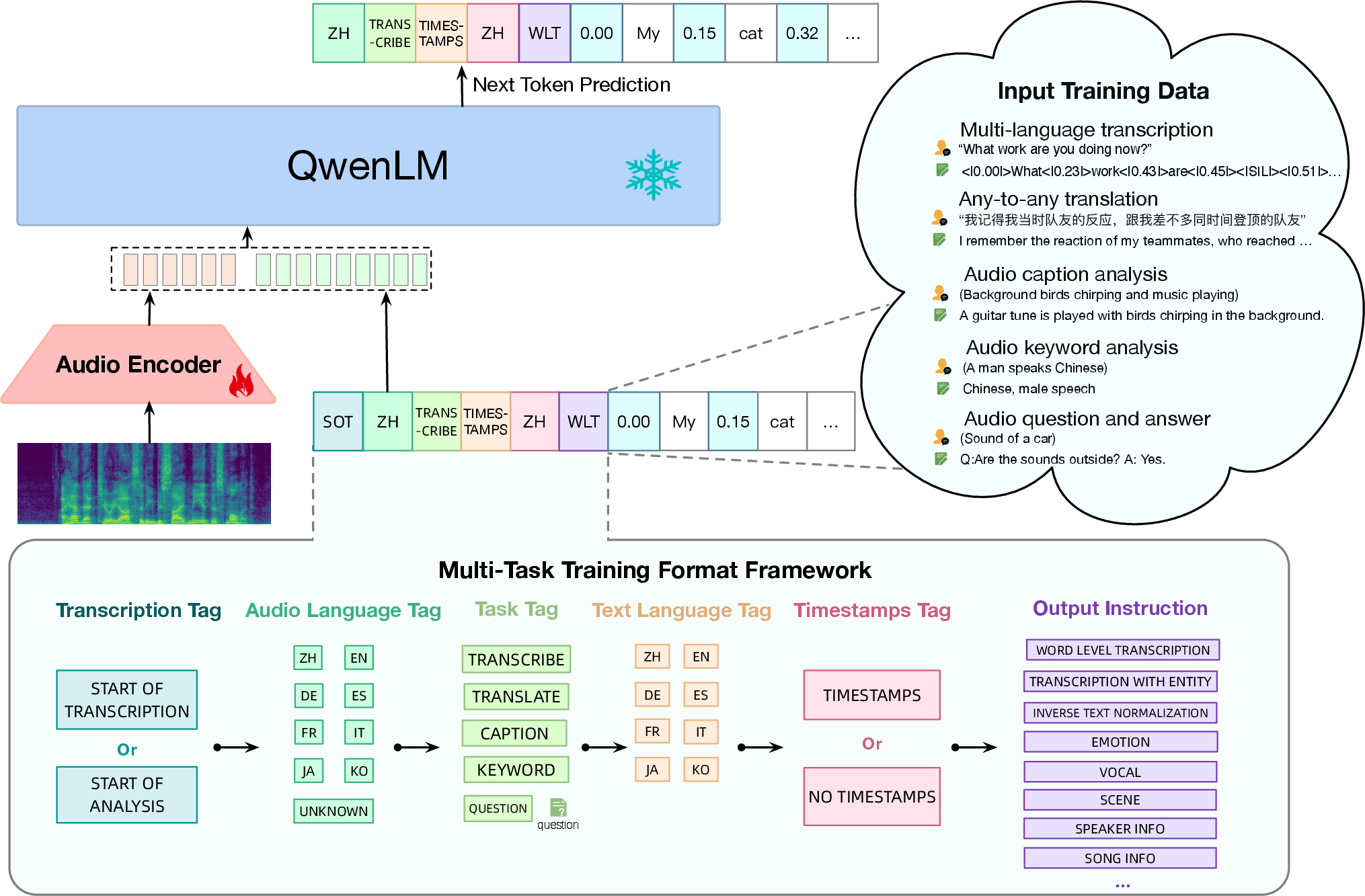
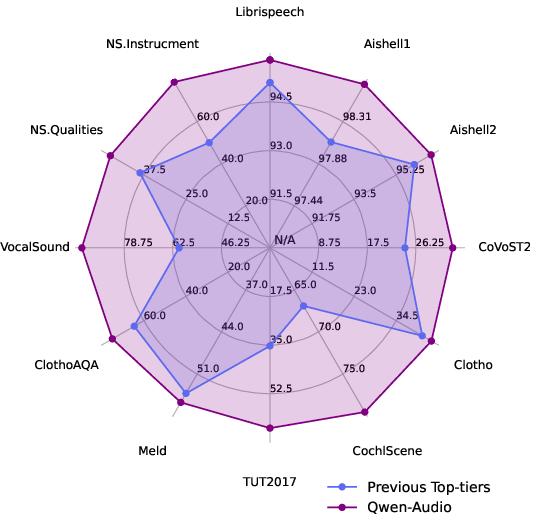
Abstract: Recently, instruction-following audio-LLMs have received broad attention for audio interaction with humans. However, the absence of pre-trained audio models capable of handling diverse audio types and tasks has hindered progress in this field. Consequently, most existing works have only been able to support a limited range of interaction capabilities. In this paper, we develop the Qwen-Audio model and address this limitation by scaling up audio-language pre-training to cover over 30 tasks and various audio types, such as human speech, natural sounds, music, and songs, to facilitate universal audio understanding abilities. However, directly co-training all tasks and datasets can lead to interference issues, as the textual labels associated with different datasets exhibit considerable variations due to differences in task focus, language, granularity of annotation, and text structure. To overcome the one-to-many interference, we carefully design a multi-task training framework by conditioning on a sequence of hierarchical tags to the decoder for encouraging knowledge sharing and avoiding interference through shared and specified tags respectively. Remarkably, Qwen-Audio achieves impressive performance across diverse benchmark tasks without requiring any task-specific fine-tuning, surpassing its counterparts. Building upon the capabilities of Qwen-Audio, we further develop Qwen-Audio-Chat, which allows for input from various audios and text inputs, enabling multi-turn dialogues and supporting various audio-central scenarios.
- Flamingo: a visual language model for few-shot learning. NeurIPS, 2022.
- Spice: Semantic propositional image caption evaluation. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part V 14. Springer, 2016.
- PaLM 2 technical report. arXiv:2305.10403, 2023.
- Anonymous. SALMONN: Towards generic hearing abilities for large language models. In Submitted to The Twelfth International Conference on Learning Representations, 2023. under review.
- Speecht5: Unified-modal encoder-decoder pre-training for spoken language processing. arXiv:2110.07205, 2021.
- Qwen technical report. arXiv preprint arXiv:2309.16609, 2023a.
- Qwen-VL: A frontier large vision-language model with versatile abilities. CoRR, abs/2308.12966, 2023b.
- Language models are few-shot learners. NeurIPS, 2020.
- AISHELL-1: an open-source mandarin speech corpus and a speech recognition baseline. In 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment, O-COCOSDA 2017, Seoul, South Korea, November 1-3, 2017. IEEE, 2017.
- Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv:2306.15195, 2023.
- Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE J. Sel. Top. Signal Process., 2022.
- Speechnet: A universal modularized model for speech processing tasks. arXiv:2105.03070, 2021.
- PaLM: Scaling language modeling with pathways. arXiv:2204.02311, 2022.
- High fidelity neural audio compression. arXiv:2210.13438, 2022.
- Pengi: An audio language model for audio tasks. CoRR, 2023.
- Clotho: an audio captioning dataset. In 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, May 4-8, 2020. IEEE, 2020.
- AISHELL-2: transforming mandarin ASR research into industrial scale. abs/1808.10583, 2018.
- CLAP: learning audio concepts from natural language supervision. abs/2206.04769, 2022.
- Neural audio synthesis of musical notes with wavenet autoencoders. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, Proceedings of Machine Learning Research. PMLR, 2017.
- Funasr: A fundamental end-to-end speech recognition toolkit. CoRR, abs/2305.11013, 2023.
- Vocalsound: A dataset for improving human vocal sounds recognition. In IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2022, Virtual and Singapore, 23-27 May 2022, pages 151–155. IEEE, 2022. doi: 10.1109/ICASSP43922.2022.9746828. URL https://doi.org/10.1109/ICASSP43922.2022.9746828.
- Whisper-at: Noise-robust automatic speech recognizers are also strong general audio event taggers. CoRR, abs/2307.03183, 2023a.
- Listen, think, and understand. CoRR, abs/2305.10790, 2023b.
- Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE ACM Trans. Audio Speech Lang. Process., 2021.
- Lora: Low-rank adaptation of large language models. arXiv:2106.09685, 2021.
- Audiogpt: Understanding and generating speech, music, sound, and talking head. CoRR, abs/2304.12995, 2023.
- Cochlscene: Acquisition of acoustic scene data using crowdsourcing. abs/2211.02289, 2022.
- Voicebox: Text-guided multilingual universal speech generation at scale. CoRR, 2023.
- Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, 2022.
- BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, Proceedings of Machine Learning Research. PMLR, 2023.
- Clotho-aqa: A crowdsourced dataset for audio question answering. In 30th European Signal Processing Conference, EUSIPCO 2022, Belgrade, Serbia, August 29 - Sept. 2, 2022. IEEE, 2022.
- Macaw-llm: Multi-modal language modeling with image, audio, video, and text integration. CoRR, abs/2306.09093, 2023.
- Voxtlm: unified decoder-only models for consolidating speech recognition/synthesis and speech/text continuation tasks. arXiv:2309.07937, 2023.
- Montreal forced aligner: Trainable text-speech alignment using kaldi. In Interspeech 2017, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, August 20-24, 2017, 2017.
- DCASE2017 challenge setup: Tasks, datasets and baseline system. In Proceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events, DCASE 2017, Munich, Germany, November 16-17, 2017, 2017.
- Lms with a voice: Spoken language modeling beyond speech tokens. CoRR, 2023.
- Openai. Chatml documents. URL https://github.com/openai/openai-python/blob/main/chatml.md.
- OpenAI. Introducing ChatGPT, 2022. URL https://openai.com/blog/chatgpt.
- OpenAI. Gpt-4 technical report, 2023.
- Training language models to follow instructions with human feedback. NeurIPS, 2022.
- Librispeech: An ASR corpus based on public domain audio books. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2015, South Brisbane, Queensland, Australia, April 19-24, 2015. IEEE, 2015.
- Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002.
- Specaugment: A simple data augmentation method for automatic speech recognition. In Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15-19 September 2019.
- Kosmos-2: Grounding multimodal large language models to the world. arXiv:2306.14824, 2023.
- MELD: A multimodal multi-party dataset for emotion recognition in conversations. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers. Association for Computational Linguistics, 2019.
- Qwen. Introducing qwen-7b: Open foundation and human-aligned models (of the state-of-the-arts), 2023. URL https://github.com/QwenLM/Qwen-7B.
- Robust speech recognition via large-scale weak supervision. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, 2023.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 2020.
- Audiopalm: A large language model that can speak and listen. CoRR.
- Hugginggpt: Solving AI tasks with chatgpt and its friends in huggingface. CoRR, abs/2303.17580, 2023.
- Achieving timestamp prediction while recognizing with non-autoregressive end-to-end asr model. In National Conference on Man-Machine Speech Communication. Springer, 2023.
- Llasm: Large language and speech model. arXiv:2308.15930, 2023.
- Generative pretraining in multimodality. arXiv:2307.05222, 2023.
- LLaMA: Open and efficient foundation language models. arXiv:2302.13971, 2023a.
- Llama: Open and efficient foundation language models. arXiv:2302.13971, 2023b.
- Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288, 2023c.
- Attention is all you need. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett, editors, Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, 2017.
- Cider: Consensus-based image description evaluation. In CVPR, 2015.
- Covost 2: A massively multilingual speech-to-text translation corpus. abs/2007.10310, 2020. URL https://arxiv.org/abs/2007.10310.
- Blsp: Bootstrapping language-speech pre-training via behavior alignment of continuation writing. arXiv:2309.00916, 2023a.
- SLM: bridge the thin gap between speech and text foundation models. abs/2310.00230, 2023b.
- Slm: Bridge the thin gap between speech and text foundation models. arXiv:2310.00230, 2023c.
- Viola: Unified codec language models for speech recognition, synthesis, and translation. CoRR, 2023d.
- Speechx: Neural codec language model as a versatile speech transformer. CoRR, 2023e.
- On decoder-only architecture for speech-to-text and large language model integration. abs/2307.03917, 2023a.
- Next-gpt: Any-to-any multimodal LLM. CoRR, abs/2309.05519, 2023b.
- Soundstream: An end-to-end neural audio codec. IEEE ACM Trans. Audio Speech Lang. Process., 2022.
- Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities. CoRR, abs/2305.11000, 2023a.
- Speechtokenizer: Unified speech tokenizer for speech large language models. CoRR, abs/2308.16692, 2023b.
- Google usm: Scaling automatic speech recognition beyond 100 languages. CoRR, 2023c.
- Mmspeech: Multi-modal multi-task encoder-decoder pre-training for speech recognition. abs/2212.00500, 2022.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.