- The paper introduces InfTool’s closed-loop, autonomous data synthesis framework that leverages multi-agent role-playing and GRPO to boost LLM tool invocation accuracy from 19.8% to 70.9%.
- It employs a tripartite multi-agent system to generate high-fidelity synthetic tool trajectories, cluster raw API definitions, and iteratively refine samples via self-reflection.
- The study demonstrates practical efficiency by reducing human annotation costs and enabling domain adaptation to unseen tools across diverse application areas.
Motivation and Problem Landscape
The reliable invocation of external tools by LLM-driven agents constitutes a central challenge for scalable AI autonomy. Existing protocol-centric frameworks and supervised datasets confront three inherent limitations: high costs associated with human annotation of high-fidelity trajectories, poor adaptation to previously unseen tools, and a quality ceiling—generated data inherits synthesis model biases, constraining downstream performance. "Close the Loop: Synthesizing Infinite Tool-Use Data via Multi-Agent Role-Playing" (2512.23611) directly addresses these systemic bottlenecks by introducing InfTool—a closed-loop, fully autonomous data generation and optimization pipeline.
Framework Architecture and Data Synthesis
InfTool employs a tripartite multi-agent system: a User Simulator, a Tool-Calling Assistant (MCP Client), and an MCP Server Simulator. This architecture supports both single-turn and multi-turn interaction scenarios, ranging from basic tool invocation to complex cross-tool workflows dependent on sequential reasoning. Raw API definitions are ingested and iteratively clustered using semantic embeddings, with redundant entries abstracted for compact, high-fidelity MCP toolsets.
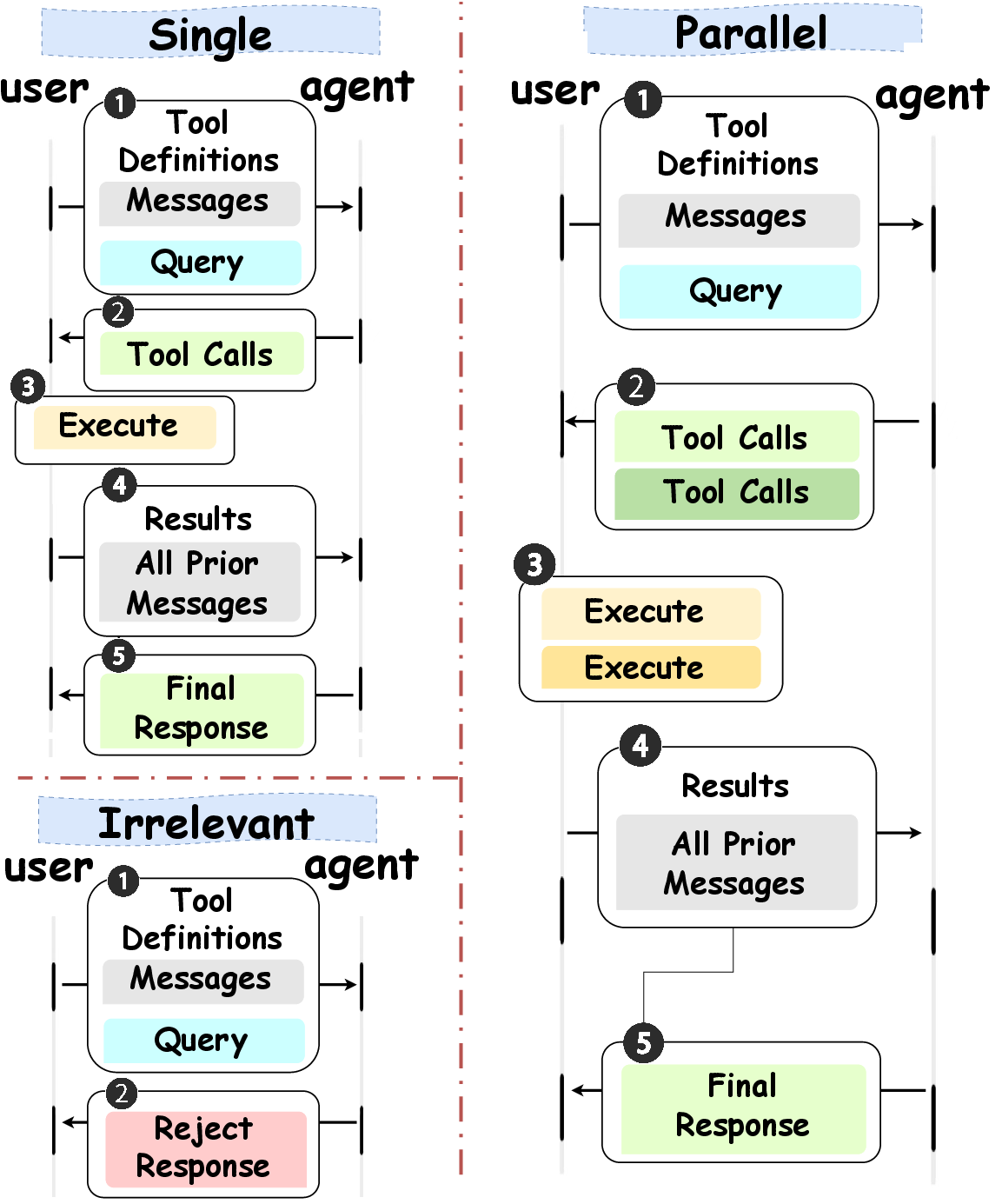
Figure 1: MCP-based tool calling across three scenarios, illustrating divergent trajectories and tool-call complexities.
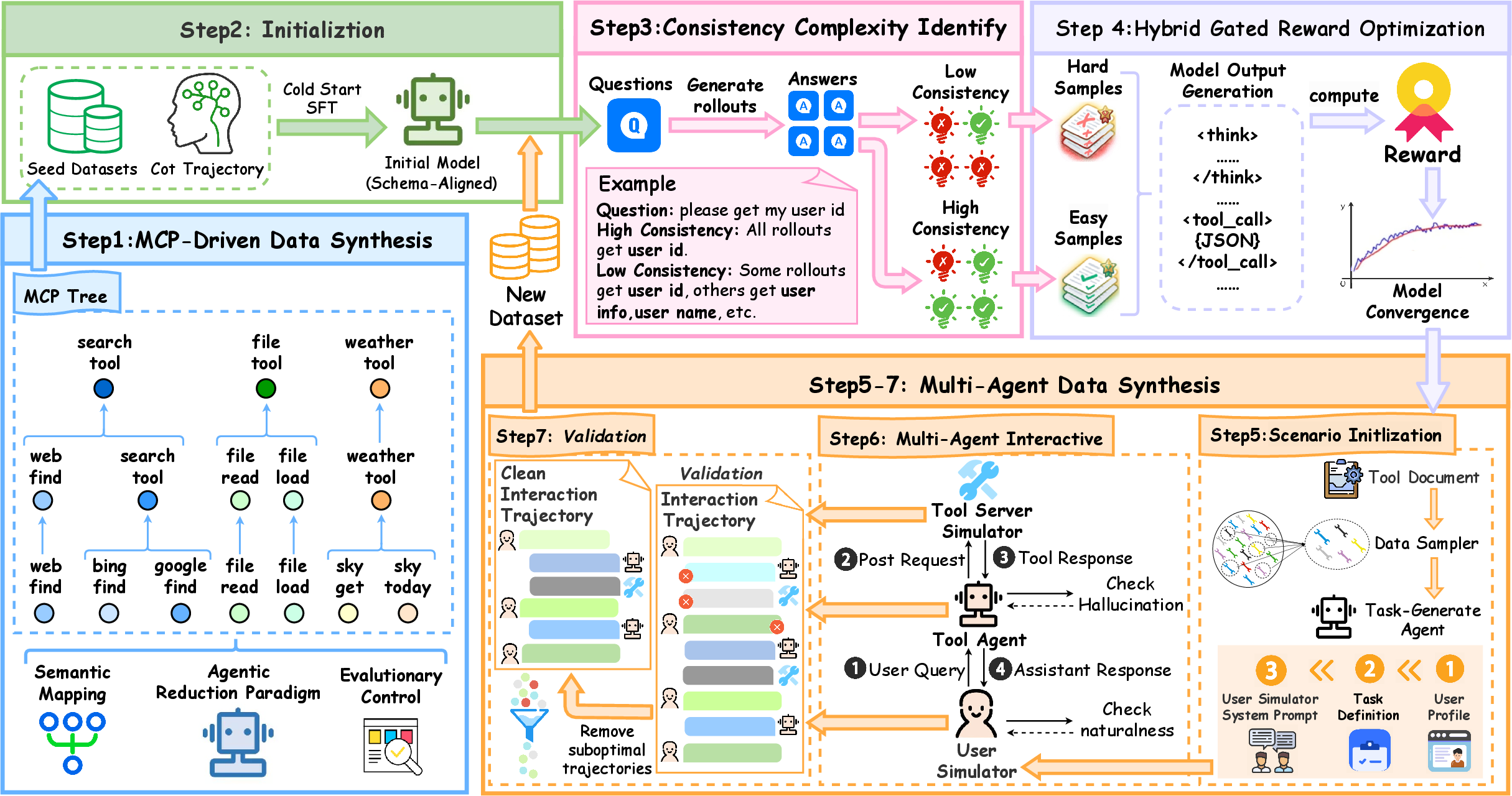
Figure 2: Framework overview: MCP tool definition synthesis, cold start SFT, sample rollout evaluation, GRPO policy optimization, multi-agent trajectory synthesis, and filtering.
Hierarchical data synthesis leverages user profile initialization, parameter gap analysis, and dynamically generated multi-agent scenarios. Automated self-reflection and multi-agent voting guarantee rigorous schema compliance and logical validity, proactively correcting hallucinations and argument violations before sample acceptance.
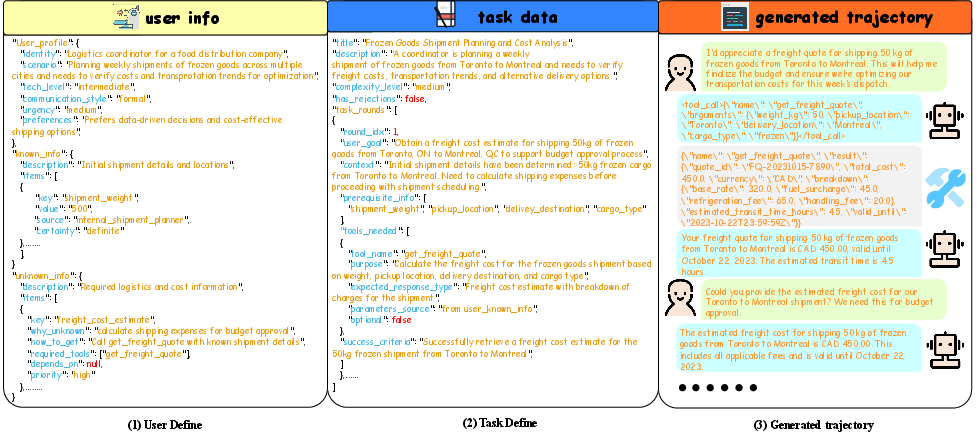
Figure 3: Data generation pipeline phases: profile and information gap initialization, task structuring, and multi-turn trajectory creation.
Iterative Self-Evolving Training Loop
The closed-loop optimization engine is powered by Group Relative Policy Optimization (GRPO), eliminating the need for explicit value networks while establishing a compact update rule for trajectory-derived group rewards. GRPO is unified with a gated composite reward mechanism. Here, schema-compliance must precede reasoning improvement: only when executions conform to protocol are additional rewards unlocked for stepwise reasoning. Each cycle stratifies data into "Easy" and "Hard" subsets based on execution consistency, focusing new synthetic samples on the hard frontier.
Dataset Evolution and Distributional Characteristics
InfTool synthesizes over 3,000 unique MCP tools from an initial set of 17,713 raw API candidates, spanning 15 primary domains with coverage of 35 additional niches. 82.83% of tools require nontrivial arguments, and structured domains (Finance, Travel, Sports) exhibit maximal parameterization complexity.
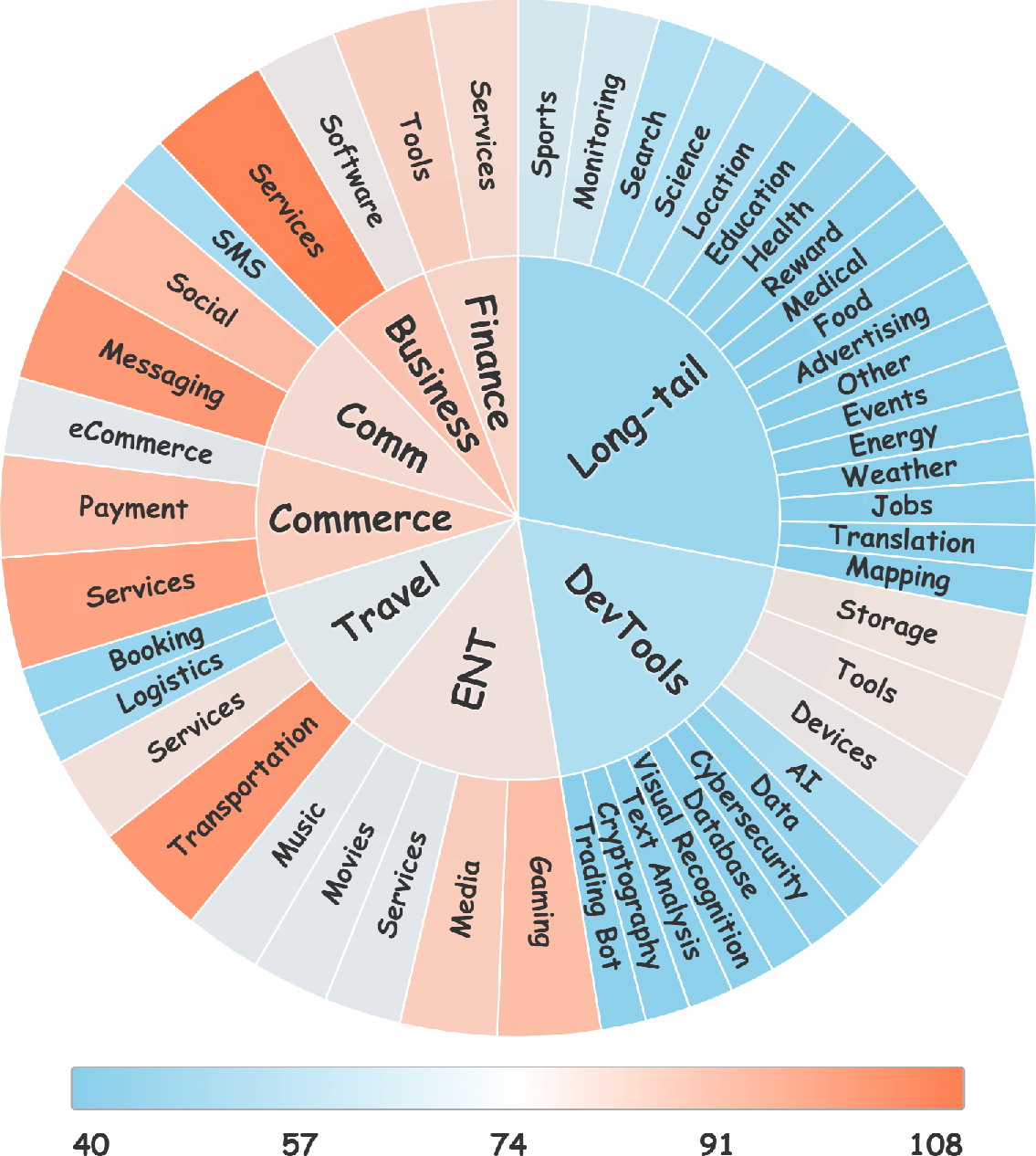
Figure 4: Sunburst visualization of domain distributions in the training dataset, highlighting broad coverage and parameterization demands.
Multi-turn dialogues exhibit a mean of 7.78 turns, with 62.46% of scenarios running 8 or fewer turns, and a substantial tail of long-horizon (10+ turn) interactions.
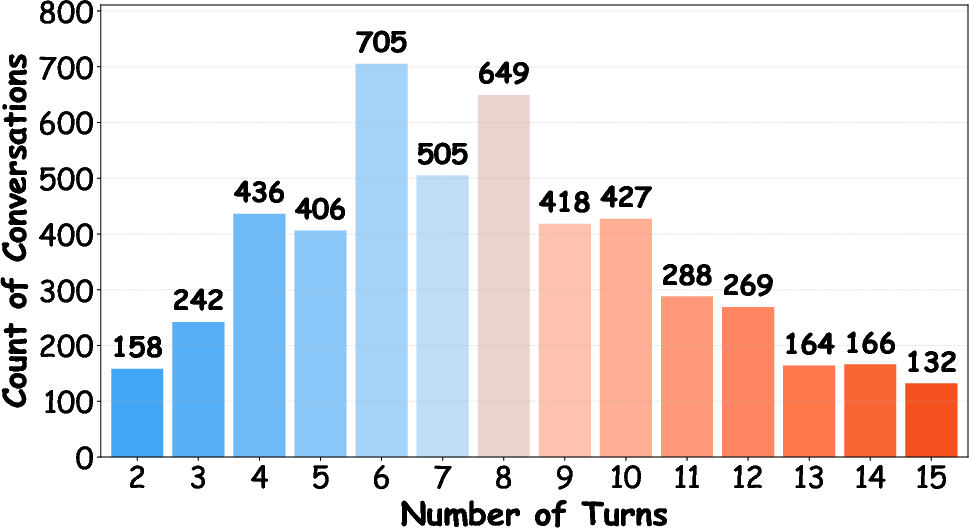
Figure 5: Conversation turn distribution, indicating prevalence of mid- to long-horizon interaction complexity.
Interaction pattern analysis shows that multi-turn, multi-tool dialogues consume up to four times the tokens of single-turn scenarios, intensifying model context management pressure.
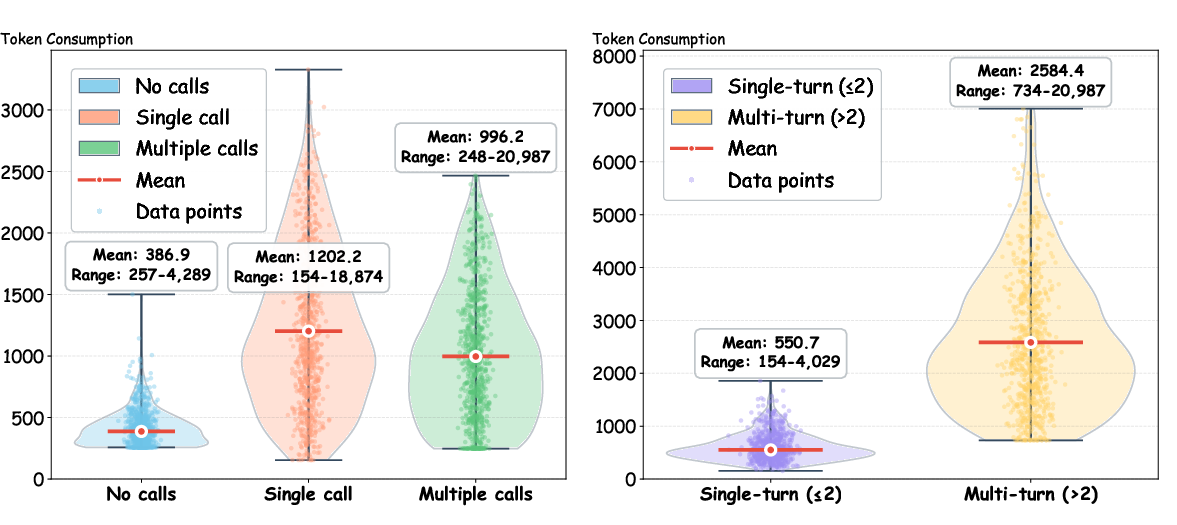
Figure 6: Token consumption stratified by tool-use frequency (none, single, multiple) and conversation length (single, multi-turn).
Experimental Evaluation and Empirical Results
InfTool's training and evaluation on the Berkeley Function-Calling Leaderboard (BFCL, V3) demonstrate substantial quantitative improvements. The base Qwen2.5-32B model attains only 19.8% accuracy; following InfTool's closed-loop regime, performance surges to 70.9% (+258%), outperforming models 10× larger and matching proprietary systems such as Claude-Opus.
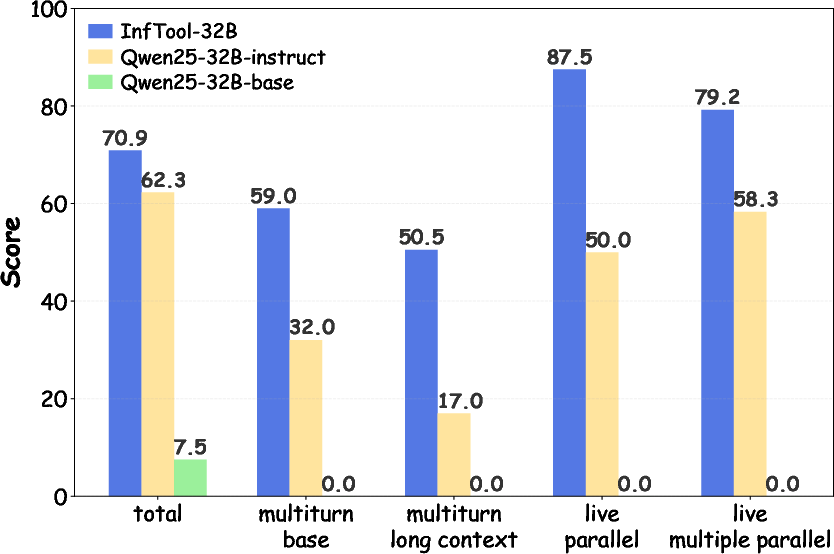
Figure 7: Comparative performance of InfTool versus baselines on BFCL, underscoring multi-turn and live tool-call superiority.
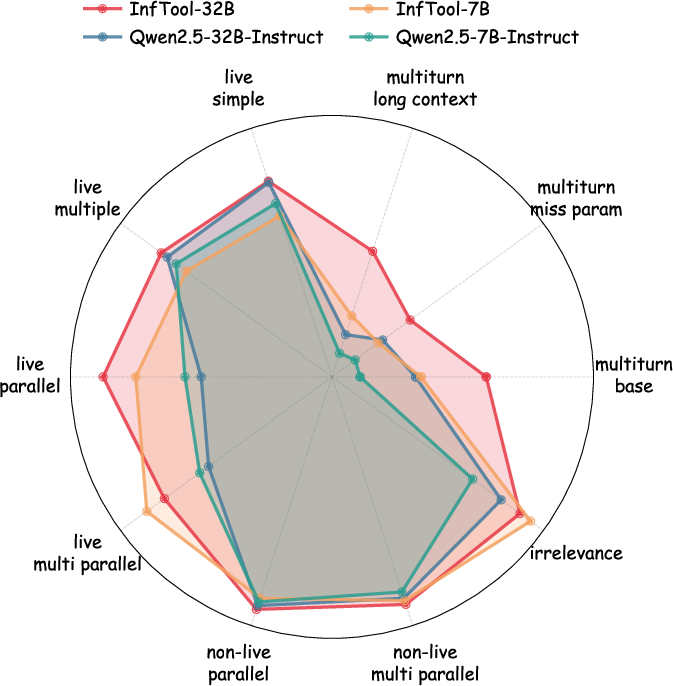
Figure 8: Radar plot analysis highlighting robustness in multi-turn reasoning, parallel execution, and error reduction.
Error analysis reveals most persistent failures arise in simple tasks due to dataset volume, despite the model achieving a +93.3% improvement rate in complex scenarios.
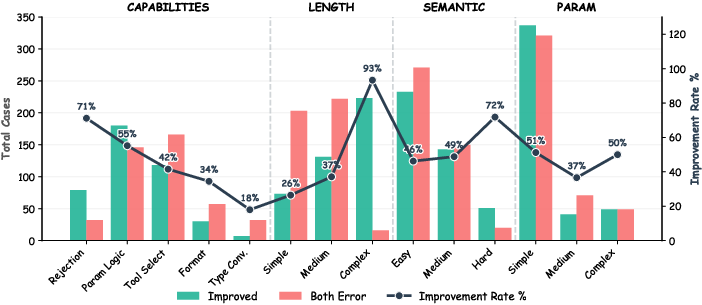
Figure 9: Unified performance landscape displaying volume (bars) and efficiency (line) stratified by difficulty and improvement rates.
Scaling analyses indicate that supervised fine-tuning with 50k synthetic samples nearly matches RL-optimized performance, though RL achieves this using half as much data per iteration.
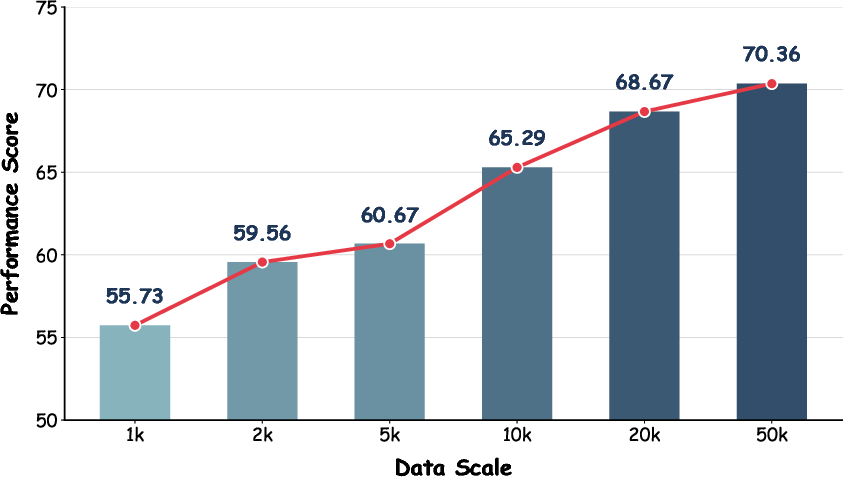
Figure 10: Performance scaling as a function of synthetic sample volume, comparing SFT and RL regimes.
Ablation studies highlight the criticality of the MCP Tree refinement: removing semantic clustering and tool deduplication degrades scores from 70.9 to 55.2. Similarly, disabling self-reflection dramatically increases hallucination frequency, with irrelevance metrics dropping by over 80 points.
Theoretical and Practical Implications
InfTool proves that data scarcity and quality ceiling issues in agentic tool-use can be resolved via autonomous synthetic trajectories coupled with iterative, reward-gated RL optimization. This points to the feasibility of domain adaptation to unseen tools without further human intervention. The recursive cycle fosters dynamic curriculum creation around previously unsolved samples, alleviating coverage and generalization constraints. Practical deployments in information integration, domain-specific virtual assistants, and agentic RPA frameworks can thus be achieved with dramatically reduced human labor.
Theoretically, the locked reward structure tightly aligns reasoning skill improvements with genuine protocol compliance, mitigating the drift problems observed in previous self-instruct paradigms. This paradigm supports future advances in agentic tool-use by expanding beyond text-only modalities, integrating vision and audio APIs, and flexibly scaling to evolving protocols.
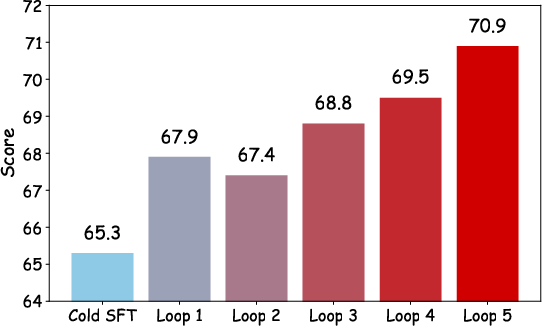
Figure 11: RL-driven performance evolution over multiple self-evolution rounds, corroborating the value of closed-loop autonomous synthesis.
Limitations and Future Directions
InfTool relies exclusively on simulated user agents, introducing an inevitable sim-to-real gap. Idealized dialogue lacks the ambiguity and adversarial behavior of human actors. The framework is presently restricted to JSON-RPC style tool integration, and its context window limits fidelity for extremely long-horizon scenarios. Future work should focus on closing the simulation gap via adversarial and in-the-wild test sets, extending multi-modal capacity, and exploring adaptive prompt and context management strategies.
Conclusion
InfTool operationalizes a scalable, annotation-free paradigm for cultivating robust tool-use behaviors in LLM agents through a self-evolving multi-agent RL loop. The framework demonstrates strong numerical gains over models of substantially larger parameter footprints and substantiates the claim that data quality and curriculum dynamism supersede raw scale for agentic function utilization. This work lays the groundwork for future agentic AI systems capable of open-ended, protocol-driven, and context-adaptive tool invocation.