ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration
Abstract: LLMs are powerful generalists, yet solving deep and complex problems such as those of the Humanity's Last Exam (HLE) remains both conceptually challenging and computationally expensive. We show that small orchestrators managing other models and a variety of tools can both push the upper bound of intelligence and improve efficiency in solving difficult agentic tasks. We introduce ToolOrchestra, a method for training small orchestrators that coordinate intelligent tools. ToolOrchestra explicitly uses reinforcement learning with outcome-, efficiency-, and user-preference-aware rewards. Using ToolOrchestra, we produce Orchestrator, an 8B model that achieves higher accuracy at lower cost than previous tool-use agents while aligning with user preferences on which tools are to be used for a given query. On HLE, Orchestrator achieves a score of 37.1%, outperforming GPT-5 (35.1%) while being 2.5x more efficient. On tau2-Bench and FRAMES, Orchestrator surpasses GPT-5 by a wide margin while using only about 30% of the cost. Extensive analysis shows that Orchestrator achieves the best trade-off between performance and cost under multiple metrics, and generalizes robustly to unseen tools. These results demonstrate that composing diverse tools with a lightweight orchestration model is both more efficient and more effective than existing methods, paving the way for practical and scalable tool-augmented reasoning systems.
Sponsor


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration”
1) What is this paper about?
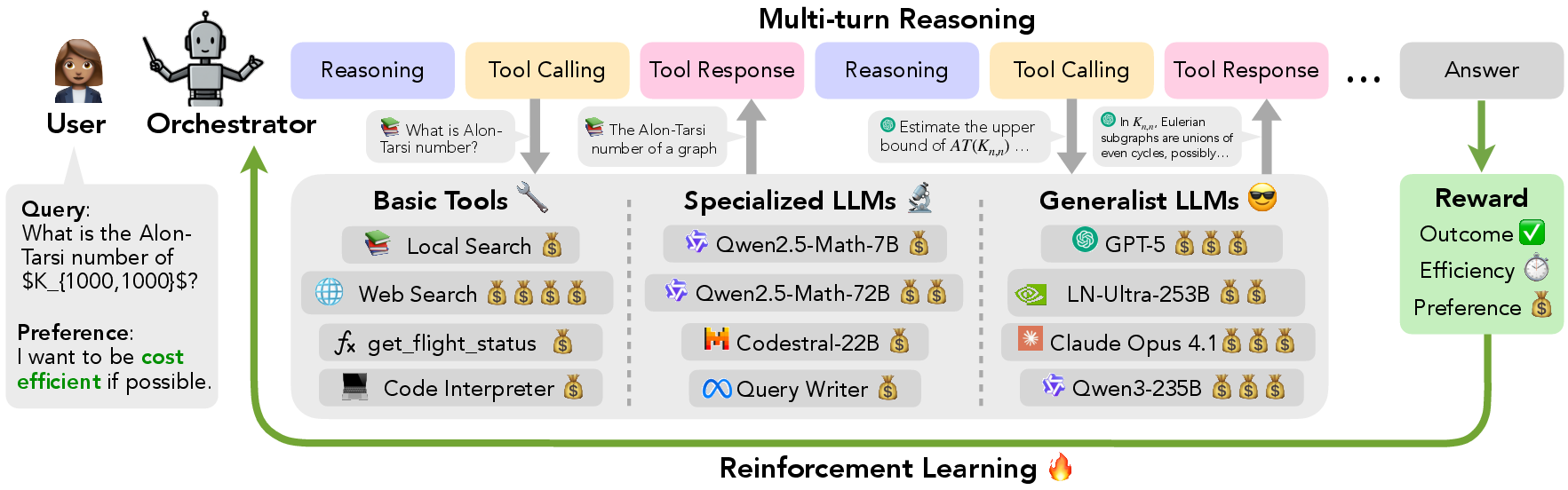
This paper shows a new way to make AI smarter and cheaper to run by having a small “manager” AI (called an orchestrator) decide when and how to use many other tools and AIs. Instead of one big model doing everything, a small model acts like a team leader, choosing the right helpers (search, calculator, coding tools, or bigger AIs) at the right time to solve tough problems.
2) What questions were the researchers trying to answer?
They focused on three simple questions:
- Can a small AI that coordinates tools beat big, single AIs on hard tasks?
- Can it do this while spending less money and time?
- Can it follow different users’ preferences, like “use cheaper tools,” “run faster,” or “avoid certain tools”?
3) How did they do it? (Methods in everyday language)
Think of the system like an orchestra:
- The small AI “Orchestrator” is the conductor.
- The tools and other AIs (like web search, code interpreters, math specialists, and large general AIs) are the musicians.
- The orchestrator chooses which “musician” to play and in what order, so the whole group solves the problem well and efficiently.
Key ideas and how they trained it:
- Unified tool calling: All tools (including other AIs) are presented in one simple menu the orchestrator can pick from, like apps on a phone.
- Multi-step planning: The orchestrator works in turns: think, choose a tool, read the tool’s reply, then think again—until it reaches an answer.
- Reinforcement learning (RL): The orchestrator learns by trial and error, getting “rewards” for good behavior—like winning points in a video game.
- Outcome reward: Did it get the right final answer?
- Efficiency rewards: Did it keep cost ($) and time (latency) low?
- Preference reward: Did it respect the user’s choices (for example, use local search more, or avoid expensive tools)?
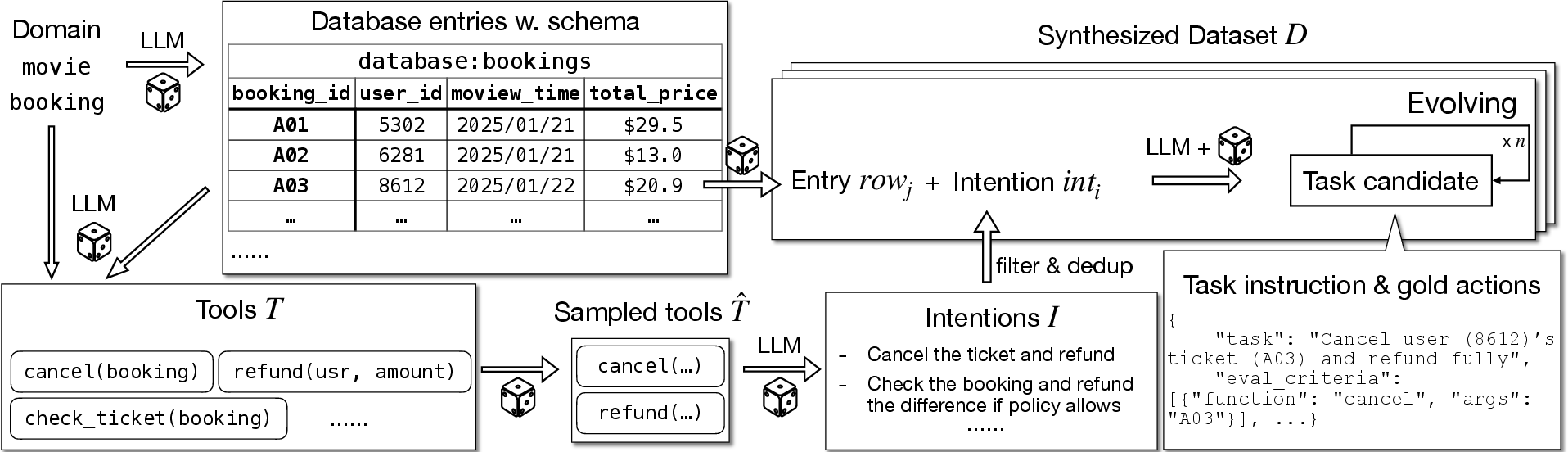
- A special training dataset (ToolScale): Because good training data is rare, the authors automatically created thousands of practice tasks inside simulated mini-worlds (with databases, APIs, and rules). Each task has a correct, checkable solution, so the model can be fairly scored.
- Practical training tricks: They used a stable RL algorithm (GRPO) and filtered out bad or unhelpful training examples to keep learning steady.
Plain-language analogies for the technical bits:
- Orchestrator: a coach assigning the right players (tools/models) for each play.
- Reinforcement learning: learning by trying, getting a score, and improving the next try.
- Preference settings: like sliders in a game—more accuracy vs. more speed vs. lower cost.
4) What did they find, and why is it important?
Main results:
- Stronger than big single models on hard tests:
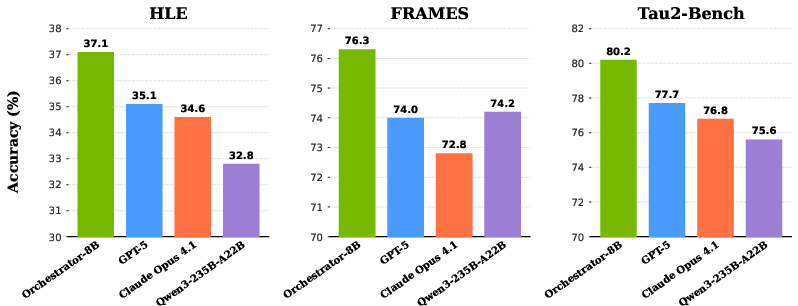
- On Humanity’s Last Exam (HLE), the orchestrator scored 37.1%, beating GPT-5 at 35.1%.
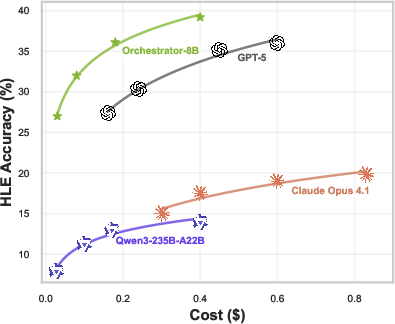
- Much cheaper and faster:
- It was about 2.5× more efficient on HLE.
- On other benchmarks (FRAMES and τ²-Bench), it beat GPT-5 while using only around 30% of the cost.
- Smart tool use:
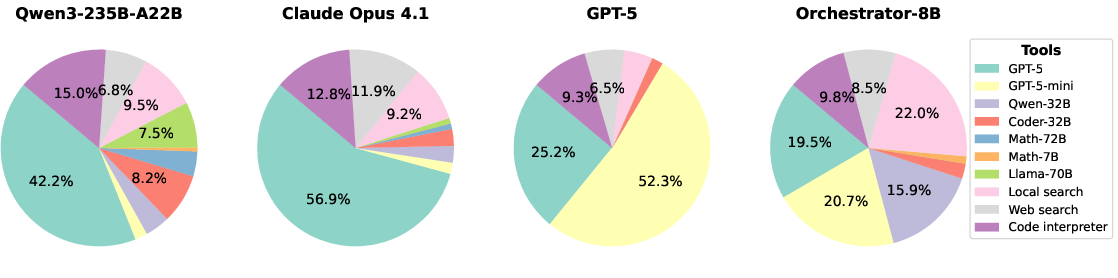
- It doesn’t just call the biggest/most expensive model by default.
- For example, on τ²-Bench it called the largest model only about 40% of the time and used cheaper tools for the rest—while still improving accuracy.
- Follows user preferences:
- If a user prefers lower cost, faster answers, or avoiding certain tools, the orchestrator adjusts its choices accordingly.
- Generalizes to new tools:
- Even when given tools and models it wasn’t trained with, it still performs well, showing flexibility.
Why this matters:
- Better accuracy with lower costs means more people and companies can use advanced AI for complex tasks without breaking the bank.
- Respecting user preferences makes the system more trustworthy and adaptable to real needs (privacy, budget, speed).
5) What’s the bigger picture?
This research suggests a powerful future direction: instead of relying on one giant AI to do everything, use a small, smart “conductor” to coordinate a team of specialized tools and models. That can:
- Push performance higher than any single model alone,
- Cut costs and waiting time,
- Let users control how the AI solves their problems (cheaper, faster, or specific tools).
In short, ToolOrchestra shows that “composing” many tools with a lightweight manager can be both more effective and more efficient. This could lead to practical AI assistants that are smarter, cheaper, and more customizable for tasks like research, coding, math help, planning trips, analyzing documents, and more.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper. Each point highlights a concrete direction future researchers can pursue.
- Reward design sparsity: The final reward is gated by binary correctness, yielding zero reward for unsolved trajectories. Investigate dense, step-level shaping (e.g., partial credit via process fidelity and operation completeness), intermediate verifiers, and curriculum strategies to improve learning signal and exploration.
- Judge bias and circularity: Accuracy on non-synthetic tasks is judged by GPT-5, which is also used as a tool. Quantify and mitigate judge-induced bias by using multiple independent judges, non-LLM verifiers, task-specific programmatic checkers, and cross-model adjudication; report inter-rater agreement and sensitivity to the judge choice.
- Synthetic data reliance: ToolScale is fully synthetic and validated with LLMs. Assess transfer to real-world, noisy environments (rate limits, tool outages, authentication, schema drift, non-deterministic APIs), and build/benchmark on human-authored, naturally occurring tool-use datasets with verifiable ground truth.
- Tool description fidelity: Tool and model “capability descriptions” are written by an LLM from only ~10 sampled tasks. Measure description accuracy and completeness, ablate the number/selection of tasks used to derive descriptions, and explore automated capability discovery (e.g., probing, performance profiling, or contract tests) rather than text summaries.
- Robustness to tool failure and drift: The system assumes correct tool responses. Systematically test timeouts, malformed returns, partial failures, rate-limiting, stale indices, and adversarial tool outputs; develop fallback policies, retries, health checks, confidence-based tool selection, and error-aware rewards.
- Preference modeling realism: User preferences are synthetic vectors produced by LLMs. Conduct human studies to learn preferences from natural language, model conflicting or dynamic preferences, evaluate stability over sessions, and measure actual satisfaction; compare vector-based control with direct natural-language preference conditioning.
- Cost and latency modeling validity: Costs are approximated via token-based API pricing and single-provider latency. Add measurements for compute energy, memory, cold start overheads, network variability, parallel calls, caching, and provider heterogeneity; perform sensitivity analyses under alternative pricing schedules and deployment topologies.
- Generalization breadth: Evaluations focus on text-only HLE, FRAMES, and -Bench. Extend to multimodal tasks (vision/audio/video), multilingual queries, long-horizon projects, and domains with complex stateful environments (e.g., software development pipelines, robotic control); quantify degradation when key tools are missing.
- Orchestrator scale and architecture: Only an 8B model is studied. Derive scaling laws for orchestrator size, compare smaller/larger models and mixture-of-experts variants, test hierarchical/recursive orchestrators, and evaluate parallel scheduling ability; analyze trade-offs between orchestration intelligence and tool dependency.
- RL algorithm and training ablations: GRPO is used without comparative baselines. Run ablations on RL algorithms (e.g., PPO, A2C, DPO, Q-learning hybrids), advantage normalization, KL control, entropy bonuses, and exploration schemes; quantify the impact of filtering heuristics (homogeneity threshold, format checks) on stability and performance.
- Turn budget and stopping policies: A fixed 50-turn cap is imposed. Learn adaptive stopping and dynamic budgets from preferences, add explicit “stop” rewards, and evaluate cost-aware planning (e.g., meta-reasoning about remaining budget); analyze performance-cost curves under constrained budgets.
- Security and privacy: No systematic assessment of prompt injection through tool outputs, data exfiltration, or privacy leakage when invoking external models/APIs. Integrate defenses (input/output sanitizers, content filters, provenance tracking), formalize privacy budgets, and evaluate attacks and mitigations in realistic threat models.
- Interpretability and accountability: Tool-call rationales and planning transparency are limited. Provide interpretable plans, causal attributions for tool choices, and post-hoc summaries; study how explanations affect user trust and oversight and whether interpretable policies improve reliability.
- Reproducibility under open stacks: Training/evaluation depend on proprietary tools (e.g., GPT-5 as judge/tool). Release open-source substitutes and protocols; report seeds, confidence intervals, and cross-lab replication results; quantify performance variance across providers and model versions.
- Economic optimality and Pareto analysis: Claims of cost-effectiveness lack formal optimality guarantees. Map Pareto fronts of accuracy–cost–latency–preference adherence, test constrained optimization (e.g., fixed budget or SLA), and benchmark competitive baselines under identical budgets.
- Sequential-only orchestration: The rollout is strictly sequential. Explore parallel tool calls, speculative execution, opportunistic caching, and result fusion strategies; measure throughput gains and contention costs; introduce transaction management for stateful multi-tool workflows.
- Context management and long-horizon memory: The system uses fixed context limits (24k input, 8k output) without detailed memory policy. Evaluate context overflow, pruning strategies, retrieval augmentation, episodic memory modules, and state summarization for very long tasks.
- Tool-call fairness and bias: Baselines show self-enhancement and strong-tool overuse biases; Orchestrator’s “balanced” calling is asserted but not statistically validated. Perform rigorous bias analysis across vendors/tools, enforce fairness constraints if desired, and measure impact on outcomes and costs.
- Evaluation consistency and significance: Some reported results could not be reproduced (e.g., GPT-5 on -Bench). Standardize evaluation protocols, release exact prompts and tool configs, report statistical significance, and include robustness across temperatures, seeds, and test splits.
- Legal/compliance implications: External tool use may entail licensing, data handling, and compliance risks. Audit the orchestration pipeline for terms-of-service adherence, data residency, and consent; propose governance controls for enterprise or regulated deployments.
Glossary
- Advantage: In reinforcement learning, a baseline-adjusted measure of how much better a trajectory is than average, used to reduce variance in policy gradient updates. "compute an advantage:"
- Agentic tasks: Tasks that require an autonomous agent to plan, act, and interact with tools over multiple steps to achieve goals. "complex agentic tasks such as those posed by the Humanity’s Last Exam (HLE)"
- Chain-of-thought (CoT): A step-by-step reasoning process generated by a model to plan actions or derive answers. "Chain-of-thought (reasoning)."
- Clipped surrogate objective: The PPO-style objective that constrains policy updates by clipping the probability ratio to stabilize training. "maximize the clipped surrogate objective:"
- End-to-end reinforcement learning: Training where the model learns the entire decision-making pipeline directly from rewards without intermediate supervision. "an 8B-parameter model trained end-to-end with reinforcement learning (RL)"
- EOS token: A special marker indicating the end of a generated sequence. "that ends with an EOS token."
- Faiss index: A vector similarity search index/library used for fast nearest-neighbor retrieval. "build Faiss index with Qwen3-Embedding-8B"
- FRAMES: A factuality reasoning benchmark used to evaluate retrieval-augmented reasoning. "On -Bench and FRAMES, Orchestrator surpasses GPT-5 by a wide margin"
- Format consistency filtering: A training-time filter that removes examples whose outputs do not follow the required tool-call schema. "(2) format consistency filtering, when the example output is not aligned with the tool call format;"
- Group Relative Policy Optimization (GRPO): A policy-gradient algorithm that normalizes rewards within groups to compute advantages, used here to train the orchestrator. "specifically Group Relative Policy Optimization (GRPO)"
- Homogeneity filtering: A stabilization technique that skips updates when rollouts in a batch have too-similar rewards, indicating weak learning signals. "(1) homogeneity filtering, when the standard deviation of rewards in a rollout batch is smaller than 0.1"
- Humanity’s Last Exam (HLE): A challenging, multi-disciplinary benchmark for assessing advanced reasoning. "On HLE, Orchestrator achieves a score of 37.1\%"
- Invalid output filtering: A training-time filter that removes examples lacking a valid answer or properly formatted output. "(3) invalid output filtering, when the example does not produce a valid answer or output."
- KL loss explosion: Instability arising when the Kullback–Leibler divergence term grows too large during training. "avoid KL loss explosion for this agent system"
- Likelihood ratio: The ratio of trajectory probabilities under the current policy versus the previous policy, used in PPO/GRPO updates. "is the likelihood ratio between the current and previous policy."
- Markov Decision Process (MDP): A formal framework for sequential decision-making defined by states, actions, transitions, and rewards. "formalize them as a Markov Decision Process (MDP)"
- Monolithic LLM systems: Single-model setups that attempt to solve tasks without orchestrating external tools or models. "off-the-shelf monolithic LLM systems"
- Orchestration paradigm: A design approach where a lightweight controller coordinates multiple tools and models to solve tasks efficiently. "we propose the orchestration paradigm."
- Orchestrator: The coordinating model that plans, selects, and sequences tool calls to solve tasks. "Orchestrator alternates between reasoning and tool calling in multiple turns to solve it."
- Pass@k: An evaluation metric measuring whether any of k generated attempts solve a task. "LLMs cannot solve it in pass@$8$;"
- Policy gradient: A reinforcement learning method that updates a policy by ascending the gradient of expected rewards. "fine-tuned using a policy gradient reinforcement learning algorithm"
- Preference-aware rewards: Reward components that incorporate user tool and cost preferences into optimization. "user-preference-aware rewards."
- Preference vector: A vector of weights specifying how much to prioritize different objectives (e.g., accuracy, cost, latency, tool usage). "is the preference vector, indicating the extent the user would like to optimize"
- Rollout: An iterative sequence of model actions and environment feedback used to generate and evaluate a trajectory. "The rollout is initialized with a predefined system prompt and the question;"
- Self-enhancement bias: The tendency of a model to prefer using variants of itself or stronger familiar tools, regardless of cost-effectiveness. "self-enhancement bias"
- ToolScale: A synthetic dataset of multi-turn, verifiable tool-use tasks created to train the orchestrator with RL. "the resulting dataset, ToolScale, publicly available"
- Trajectory: The sequence of states, actions, and observations generated during an episode, used to compute rewards. "Each trajectory is assigned a scalar reward "
- -Bench: A function-calling benchmark evaluating tool scheduling and API usage in conversational agents. "On -Bench and FRAMES, Orchestrator surpasses GPT-5 by a wide margin"
- Unified tool calling: A single interface that exposes diverse tools (APIs and models) with typed schemas for consistent invocation. "expose all tools through a single, unified interface."
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s orchestration model, unified tool interface, preference-aware rewards, and the publicly released artifacts (Orchestrator-8B, ToolScale, unified JSON tool schema).
- Enterprise software and DevOps: Cost-aware model/tool routing
- Sector: Software, MLOps/FinOps
- What: Deploy an orchestration layer that dynamically routes requests between cheaper specialized LLMs, deterministic tools (web search, local RAG, code interpreter), and stronger generalist LLMs only when needed. Enforce budgets, latency SLAs, and user/tool preferences per request.
- Tools/products/workflows: “Model & Tool Router” service in the API gateway; JSON tool catalog; preference engine; cost and latency instrumentation; GRPO-trained or off-the-shelf
Orchestrator-8B. - Assumptions/dependencies: Reliable tool APIs; accurate tool descriptions; consistent pricing and latency telemetry; organizational acceptance of cost caps and preference policies.
- Enterprise knowledge assistants (RAG with orchestration)
- Sector: Knowledge management, enterprise search
- What: A preference-aware assistant that chooses between local embeddings (e.g., Faiss), web search (e.g., Tavily), and stronger LLMs to answer questions with citations, optimizing for factuality (FRAMES-style) and cost.
- Tools/products/workflows: Local index + web search + code interpreter pipeline; preference-aware routing (privacy-first vs breadth-first); automated citations and evidence trace.
- Assumptions/dependencies: Access to internal corpora; data privacy/compliance; quality and freshness of indexes; governance over tool use logs.
- Customer support triage and resolution
- Sector: Customer experience, IT support
- What: Multi-turn agent that calls domain-specific functions (e.g., status check APIs), uses local knowledge bases, and escalates to stronger models only for edge cases—reducing average handle time and spend.
- Tools/products/workflows: Function-calling scheduler; run-books encoded as tool calls; agentic loop with capped turns.
- Assumptions/dependencies: Stable domain APIs; guardrails for escalation; observability of tool failures.
- Developer productivity and code workflows
- Sector: Software engineering
- What: Orchestrated “coding copilot” that selects specialized coding LLMs vs generalist models, uses a Python sandbox for tests, and routes to web search for library usage, balancing accuracy with cost/latency.
- Tools/products/workflows: Code writer selection (e.g., Qwen Coder vs generalist), unit-test execution via sandbox, function-calling pipelines for CI suggestions.
- Assumptions/dependencies: Secure sandboxing; repository access policies; prompt formatting consistency for tool calls.
- Business and data analysis assistant
- Sector: Business intelligence, analytics
- What: Self-service analytics agent that chooses when to query databases, execute Python for charts, or perform web research, meeting latency/cost preferences per user or department.
- Tools/products/workflows: SQL/BI connectors exposed as tools; Python sandbox for analysis; report synthesis via cheaper models and final polish via stronger ones if needed.
- Assumptions/dependencies: Database permissions; accurate schema/tool descriptions; monitoring for data leakage.
- Finance research desk (cost-constrained)
- Sector: Finance
- What: An orchestrated research agent that schedules market data APIs, calculators, and only occasionally calls frontier LLMs for synthesis—producing evidence-backed briefs within pre-set budgets.
- Tools/products/workflows: API scheduling; preference vector tuned for compute/latency; memo generation pipeline with source tracking.
- Assumptions/dependencies: Licensed data feeds; strict compliance records; risk of model hallucinations mitigated by evidence gating.
- Education and tutoring
- Sector: Education
- What: Personalized tutoring that routes math questions to math-specialized models and conceptual explanations to generalists, with optional privacy-first local search and cost limits for classrooms.
- Tools/products/workflows: Per-student preference profiles; function calling for graded steps; chain-of-thought governance for pedagogy.
- Assumptions/dependencies: Age-appropriate safety; curriculum alignment; monitoring for correctness and bias.
- Public-sector knowledge assistant
- Sector: Policy, public administration
- What: Preference-aware research assistants for civil servants—favor local search (privacy) and low cost, while providing citations for policy briefs.
- Tools/products/workflows: Local corpora; web search with audit trails; preference toggles (privacy vs breadth vs speed); evidence logging.
- Assumptions/dependencies: Data classification policies; accountability standards; procurement rules for external APIs.
- Security/IT operations triage
- Sector: Cybersecurity, IT
- What: Agents that parse indicators of compromise in a sandbox, query threat intel APIs, and escalate to a stronger model only when needed—reducing cost while preserving speed.
- Tools/products/workflows: IOC parsers in Python; vetted threat intel tools; escalation rules; audit logs.
- Assumptions/dependencies: Sandboxing guarantees; secure tool access; strict incident logging.
- Daily life personal research assistant
- Sector: Consumer
- What: Budget-aware assistant for travel, shopping, and general research that chooses local knowledge vs web search vs expensive model calls, and uses domain functions like
get_flight_status. - Tools/products/workflows: Preference sliders (privacy, speed, cost); function-calling for travel and commerce APIs; evidence citations.
- Assumptions/dependencies: API availability; reliable pricing; honest disclosures about uncertainty.
- Academic use: Training and evaluation of tool-use agents
- Sector: Academia, AI research
- What: Use
ToolScaleto train domain-specific orchestrators; evaluate on HLE, FRAMES, and -Bench; study efficiency/performance trade-offs and preference adherence. - Tools/products/workflows: GRPO training scripts; unified tool schemas; preference generation and adherence metrics.
- Assumptions/dependencies: Compute availability; careful reward shaping; replication of evaluation settings (pricing, latency).
- Platform productization: Orchestration SDK and server
- Sector: Platforms, SaaS
- What: Offer a turnkey “Orchestration SDK/Server” that standardizes the JSON tool interface, supports preference vectors, logs cost/latency, and exposes policies as managed services.
- Tools/products/workflows: Tool registry; policy management; observability dashboards; integration guides.
- Assumptions/dependencies: Developer adoption; compatibility across heterogeneous APIs; sustained maintenance of tool descriptions.
Long-Term Applications
The following applications are promising but require further safety, reliability, standardization, scaling, or integration work.
- Healthcare clinical decision support (non-autonomous)
- Sector: Healthcare
- What: Orchestrate EHR APIs, local medical knowledge bases, calculators, and specialized reasoning models to support clinicians with cost- and privacy-aware workflows.
- Tools/products/workflows: “Clinical Orchestrator” with strict auditing, evidence gating, and privacy-first preferences; staged escalation to stronger models.
- Assumptions/dependencies: Regulatory approvals (e.g., FDA), rigorous clinical validation, robust safety guardrails, HIPAA-compliant integrations; LLM-judge replacement with verified evaluation.
- Robotics and edge autonomy
- Sector: Robotics
- What: Orchestrate perception, planning, and control models/tools; schedule expensive vision or reasoning modules only when necessary; run small orchestrators on-device.
- Tools/products/workflows: Real-time tool adapters; on-device
Orchestrator-8Bvariants; fallback policies for unavailability. - Assumptions/dependencies: Real-time constraints; reliable on-device tool implementations; deterministic behavior needs; hardware acceleration.
- Energy and industrial operations
- Sector: Energy, manufacturing
- What: Orchestrate forecasting and optimization tools for grid operations, demand response, and predictive maintenance under strict latency and reliability constraints.
- Tools/products/workflows: Time-series models as tools; optimization services; cost/latency budgeting in control rooms.
- Assumptions/dependencies: High availability requirements; deep integration with OT/SCADA; rigorous validation and fail-safes.
- Cross-vendor tool marketplaces and standards
- Sector: Software platforms, ecosystem
- What: Standardize tool descriptions, pricing/latency metadata, and preference semantics to enable plug-and-play orchestration across vendors.
- Tools/products/workflows: Open schema for tool catalogs; marketplace governance; compatibility layers.
- Assumptions/dependencies: Industry consensus; certification programs; security and compliance frameworks.
- Multi-orchestrator recursive systems (“compound AI” at scale)
- Sector: General AI systems
- What: Recursively compose orchestrators that partition tasks, supervise sub-orchestrators, and learn adaptive pipelines—pushing intelligence while controlling cost.
- Tools/products/workflows: Hierarchical orchestration; task decomposition policies; meta-preferences (cost, speed, accuracy).
- Assumptions/dependencies: Robust coordination protocols; stability under recursion; advanced reward shaping; safety and auditability.
- On-device/offline privacy-preserving orchestration
- Sector: Consumer, enterprise
- What: Run small orchestrators on edge devices with local toolsets (offline RAG, calculators) and opportunistic cloud escalation under strict privacy settings.
- Tools/products/workflows: Local embeddings; offline tool packs; differential privacy; hybrid routing.
- Assumptions/dependencies: Sufficient local compute and storage; offline tool coverage; secure update channels.
- Preference learning and personalization without explicit vectors
- Sector: Product analytics, UX
- What: Infer user preferences from behavior (implicit signals) and adapt routing policies dynamically—reducing configuration burden.
- Tools/products/workflows: Bandit/RL for preference inference; cohort-level policies; continuous evaluation and safeguards.
- Assumptions/dependencies: Consent and privacy compliance; robust signal quality; avoidance of bias and unintended optimization.
- Verified correctness and trustworthy evaluation
- Sector: Safety, compliance
- What: Replace LLM-as-judge with formal verification, domain verifiers, or multi-modal grounders to assure correctness beyond text comparison.
- Tools/products/workflows: Verifiable pipelines; domain-specific validators; provenance chaining and audit trails.
- Assumptions/dependencies: Availability of verifiers; coverage across tasks; standardization of proof artifacts.
- Regulatory and compliance orchestration
- Sector: Legal, public policy
- What: Encode legal constraints, fairness, and audit requirements into preference vectors and routing policies; produce documented tool-call trails for oversight.
- Tools/products/workflows: Policy-aware orchestration; audit dashboards; compliance reporting APIs.
- Assumptions/dependencies: Clear regulatory guidance; interoperable auditing standards; organizational adoption.
- Adaptive procurement and pricing-aware orchestration
- Sector: Procurement, finance
- What: Dynamically adjust routing to reflect changing API prices and SLAs; negotiate cost-performance trade-offs programmatically.
- Tools/products/workflows: Pricing monitors; automated policy updates; A/B testing across providers.
- Assumptions/dependencies: Real-time access to pricing/SLAs; robust failover; governance over vendor switching.
- Domain-specific orchestrators (e.g., trading, legal drafting) with stronger safety
- Sector: Finance, legal
- What: Specialized orchestrators with domain tools and guardrails; enforce conservative escalation and strict evidence requirements to mitigate risk.
- Tools/products/workflows: Tool registries per domain; safety policies; post-hoc verification.
- Assumptions/dependencies: Domain verifiers; liability frameworks; human-in-the-loop oversight.
Notes on common assumptions and dependencies across applications
- Tool availability and reliability: Many applications depend on stable, well-documented APIs and accurate tool descriptions in the unified JSON schema.
- Pricing and latency telemetry: Cost/latency signals must be captured consistently to optimize rewards and enforce budgets.
- Safety and governance: Preference vectors and routing policies need guardrails to avoid misuse; audit trails are essential for compliance.
- Evaluation fidelity: Current setups often rely on LLM-as-judge; higher-stakes use cases need verified, domain-specific evaluators.
- Compute and infrastructure: RL fine-tuning and orchestration at scale assume adequate GPUs/servers and observability; on-device scenarios need efficient small models and secure sandboxes.
- Generalization: While the orchestrator generalizes to unseen tools, production reliability still depends on tool description quality and integration rigor.
Collections
Sign up for free to add this paper to one or more collections.

