- The paper presents a disaggregated infrastructure for agentic RL training that minimizes synchronization overhead and enhances resource utilization.
- The paper demonstrates trajectory-level asynchrony and serverless reward computation, achieving up to 2.05× latency reduction and 4.58× throughput gains.
- The paper validates RollArt on large-scale clusters, ensuring robust fault tolerance and scalability for training hundreds-of-billions parameter models.
Scaling Agentic RL Training: The RollArt System
Motivation and Challenges in Agentic RL Training
Agentic RL constitutes a paradigm shift in LLM post-training, focusing on autonomous decision-making and long-horizon planning within heterogeneous environments. The agentic RL pipeline involves three stages: rollout (data generation via agent–environment interaction), reward computation (trajectory evaluation), and training (agent weight update). Each stage exhibits distinct resource profiles; for example, rollouts encompass both TFLOPS-heavy prefill and memory-bandwidth-bound decoding, intermixed with stateful, CPU-intensive environment simulations. Monolithic clusters and naive resource allocation fail to accommodate these heterogeneous requirements, resulting in severe resource underutilization and orchestration bottlenecks.
RollArt targets the agentic RL infrastructure challenge by proposing rigorous disaggregation strategies that enable hardware specialization without incurring detrimental synchronization overhead.
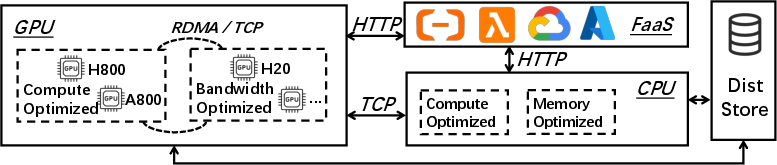
Figure 1: Disaggregated infrastructure for agentic RL training, showing decoupled resource pools for training, inference, environments, and serverless components.
Workload Profiling Insights
The latency breakdown of agentic RL steps reveals the dominant cost components shift depending on the environment's stability and phase affinity. Notably, environment initialization failures (env.reset) can shift the bottleneck from GPU-bound LLM generation to environment overhead, with latency spikes observed up to 513.3s per iteration, compared to the 366s baseline. These failures occur frequently, necessitating robust environment management and asynchronous orchestration.
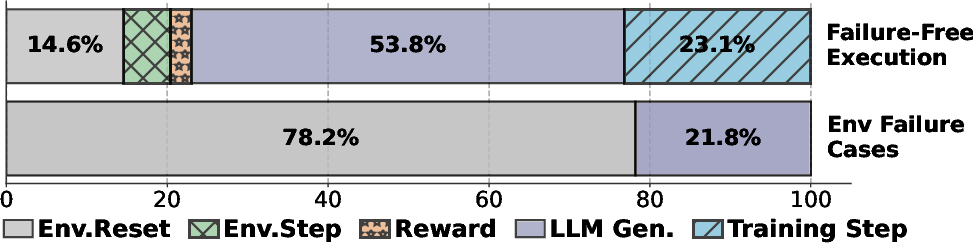
Figure 2: Successful runs are dominated by LLM compute, while environment failures shift the bottleneck to environment initialization.
Additionally, multi-task agentic RL tasks manifest bimodal hardware affinities. Prefill-heavy tasks such as FrozenLake benefit from compute-optimized GPUs (H800), while decode-heavy tasks like GEM-Math achieve greater efficiency on bandwidth-optimized GPUs (H20). The paper provides empirical evidence that static GPU assignment is insufficient to maximize throughput.
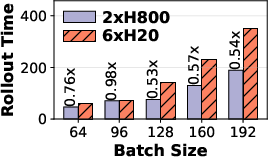
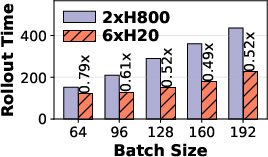
Figure 3: FrozenLake as a representative prefill-heavy agentic task, requiring compute-optimized hardware for optimal throughput.
RollArt Design Principles
The RollArt design is governed by three principles:
Hardware-Affinity Workload Mapping
RollArt enforces granular hardware affinity, assigning trajectories to optimal devices according to their phase-specific resource profile. Task routing is configurable at both stage and trajectory levels, leveraging cost-efficient scheduling in heterogeneous clusters.
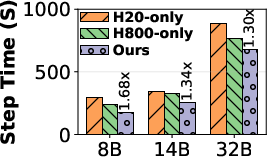
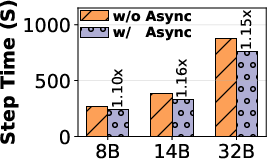
Figure 4: Hardware affinity yields step-time speedups by matching decoding/prefill phases to appropriate GPUs.
Fine-Grained Asynchrony and Trajectory-Level Scheduling
To eliminate resource bubbles due to synchronization delays, RollArt operates at the trajectory level, overlapping environment interaction, LLM generation, and reward computation. Managed asynchrony exposes an explicit bound on policy staleness to balance throughput and gradient stability.

Figure 5: Trajectory-level rollout overview demonstrating overlapping and pipelined execution of environment, inference, and reward.
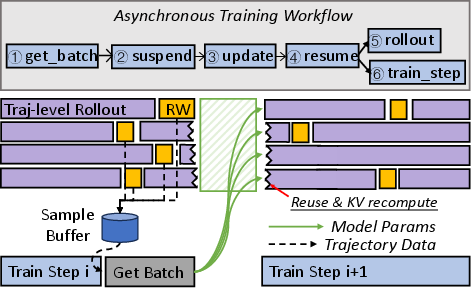
Figure 6: Asynchronous training workflow, enabling parallel progression of rollout and training, masking communication delays.
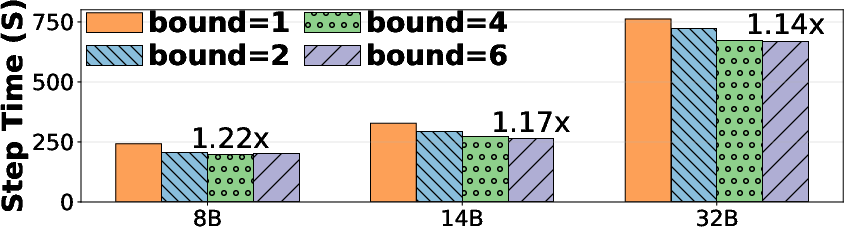
Figure 7: RollArt’s asynchronous bound (α) directly impacts step time and model convergence, providing configurable tradeoffs.
Statefulness-Aware Computation: Serverless Reward-as-a-Service
Stateless reward workers can be elastically provisioned on serverless platforms for autoscaling and improved resource efficiency, while stateful components remain on managed clusters for environment isolation. Empirical analysis demonstrates that local GPU dedication for reward computation yields only 7.4% utilization, whereas serverless deployment achieves utilization up to 88% and reduces rollout time per step from 158s to 77s.
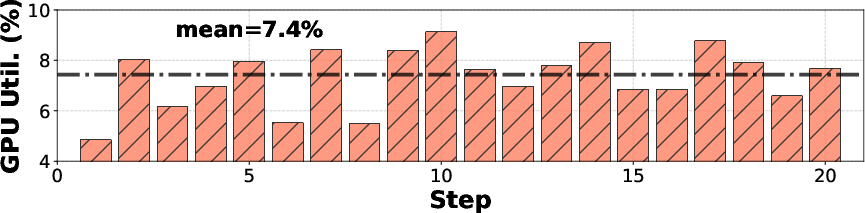
Figure 8: Local GPU reward computation underutilizes resources due to statefulness misalignment.
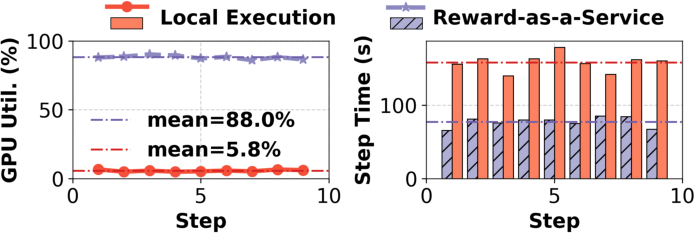
Figure 9: Reward-as-a-Service on serverless architecture drastically improves GPU utilization and step speed.
Programming and System Model
RollArt introduces a declarative programming model with explicit hardware affinity and statefulness registration via Python decorators. The cluster abstraction acts as a controller, broadcasting and routing workloads in accordance with user preference and system policy. This enables rapid adaptation to task-level hardware requirements and seamless offloading to serverless endpoints.
The architecture combines a distributed runtime layer with a centralized resource manager, interfacing with high-throughput communication engines (NCCL, Mooncake) and object-based deferred messaging (Ray’s ObjRefs).
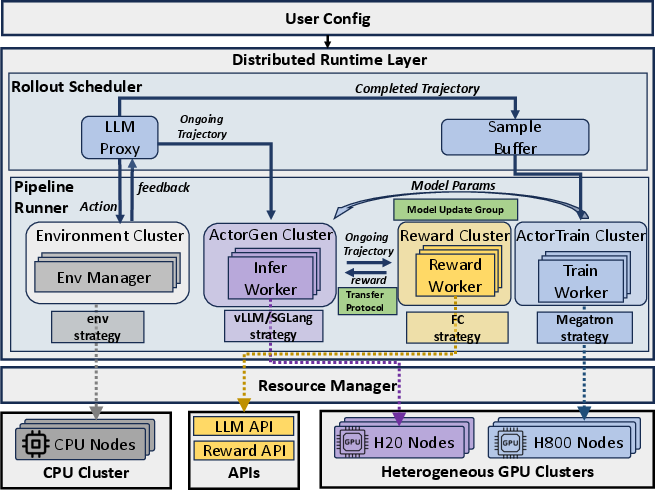
Figure 10: RollArt system architecture, visualizing resource managers, cluster abstraction, and distributed workflow orchestration.
End-to-End Evaluation
Comprehensive benchmarks indicate RollArt achieves 1.35–2.05× reduction in end-to-end training latency against both synchronous (veRL+) and asynchronous (StreamRL) baselines, while throughput gains range from 2.65×–4.58× over synchronous implementations. Asynchronous workflow mitigates environment failures, sustains throughput under heavy-tailed latency distributions, and exploits hardware affinity for step-time improvements. Scaling experiments reveal continued throughput improvements when increasing rollout GPU allocation—a property not observed in competing baselines.
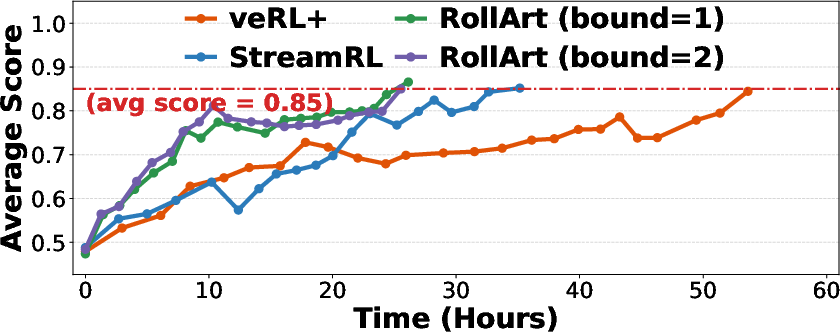
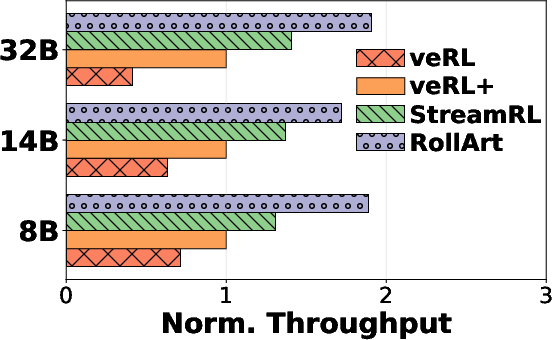
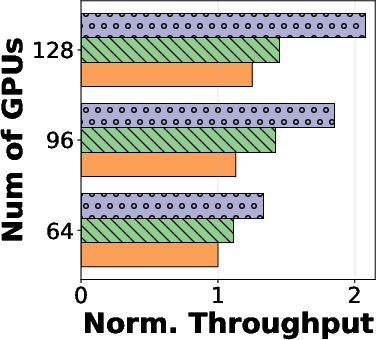
Figure 11: RollArt achieves consistent time-to-score reduction in multi-task agentic RL convergence curves.
Production Deployment and Scalability
RollArt has been deployed on Alibaba’s 3,000+ GPU production cluster for large MoE LLM RL training (hundreds of billions of parameters). Large-scale workload characterization uncovers actionable optimization opportunities (e.g., prefix caching and multi-tiered environment image caching), with observed step-time speedups of 1.66× in week-long jobs. Asynchronous orchestration and resource disaggregation result in robust system resilience, with demonstrated 99.99% environment setup success and efficient recovery from worker failures.
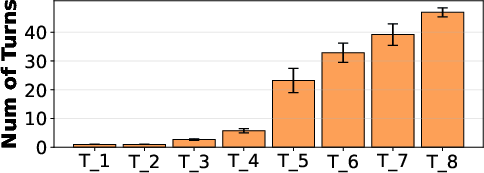
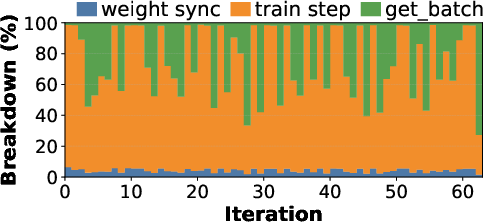
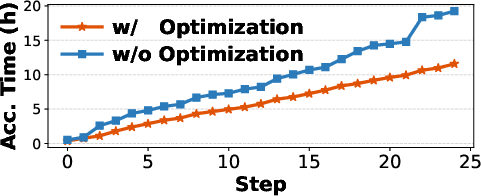
Figure 12: The distribution of average number of turns per agentic RL task illustrates modality-driven heterogeneity and phase affinity.
Practical and Theoretical Implications
RollArt represents a robust system-level solution for the scaling laws and systems challenges of agentic RL. Its highly configurable, fine-grained orchestration mechanisms and abstraction-driven runtime offer strong guarantees on throughput, scalability, and resource efficiency for heterogeneous workloads.
The practical implications include:
- Production-grade support for hundreds-of-billions parameter models and multi-thousand GPU clusters.
- Hardware-agnostic extensibility for continuous integration of new device classes, network interconnects, and serving paradigms.
- Compliance with elasticity and fault tolerance requirements via serverless offloading.
Theoretically, RollArt quantifies the impact of trajectory-level asynchrony on model convergence and provides actionable insights into hardware affinity, optimal resource mapping, and environment management. Future directions include automated load balancing for prefill–decoding disaggregation, adaptive asynchronous bound tuning for model quality, and further system fusion for latency masking and pipeline optimization.
Conclusion
RollArt delivers empirically validated throughput and scalability advances for agentic RL training, leveraging disaggregated infrastructure and fine-grained execution principles. The results generalize to multi-tenant, multi-task RL workloads with complex dependency patterns, and establish RollArt as a reference architecture for robust, production-level agentic LLM training on heterogeneous clusters (2512.22560).