- The paper introduces a novel encoder-decoder framework that generalizes forecasting by predicting arbitrary temporal segments, unifying extrapolation, interpolation, and imputation tasks.
- It employs a latent bottleneck encoder with query-based decoding to efficiently capture global temporal and inter-channel dynamics, enhancing performance across diverse datasets.
- Empirical results demonstrate state-of-the-art performance with significant MSE/MAE improvements and reduced GPU memory usage, validating the framework’s scalability.
TimePerceiver: An Encoder-Decoder Framework for Generalized Time-Series Forecasting
The TimePerceiver framework addresses a significant gap in multivariate time-series forecasting: the lack of alignment between model architecture, prediction (decoding), and training strategy. Traditional approaches predominantly optimize encoder design, often under a narrow task setting—predicting a continuous future segment conditioned on a fixed past window (Figure 1). This paradigm restricts model generalization across extrapolation, interpolation, and imputation tasks. TimePerceiver generalizes the forecasting objective by enabling prediction of arbitrary temporal segments, encompassing both future and missing (or past) values given any contextual subset. This yields a more comprehensive training protocol, exposing the model to a broad distribution of temporal reasoning challenges.
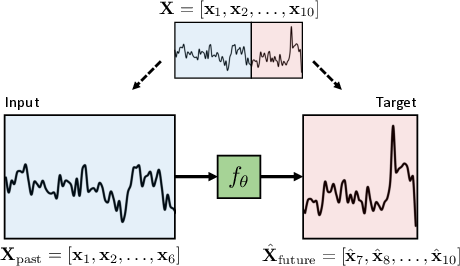
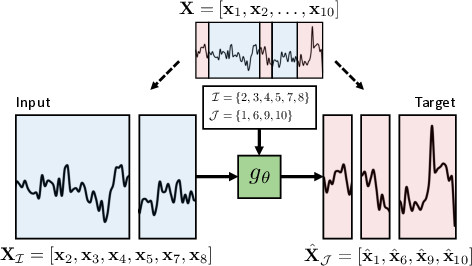
Figure 1: The standard time-series forecasting formulation is limited to unidirectional prediction, whereas TimePerceiver enables prediction over arbitrarily positioned segments along the temporal axis.
This generalized setup formalizes the forecasting task as the estimation of XJ given inputs XI, for arbitrary, potentially non-contiguous index sets I, J satisfying I∩J=∅, thus unifying extrapolation, interpolation, and imputation under a single end-to-end system. The empirical evidence demonstrates that exposure to such diverse temporal prediction objectives improves generalization across conventional and non-standard benchmarks.
Architecture: Latent Bottleneck Encoder and Query-Based Decoder
TimePerceiver's encoder-decoder design is tailored to the generalized formulation, introducing a latent bottleneck encoder and a query-based decoder.
Encoder. The input sequence is discretized into temporal patches and augmented with learnable temporal and channel positional embeddings, forming an enriched set of token representations. The encoder begins with a cross-attention stage, projecting input tokens into a compact set of learnable latent tokens. This bottleneck reduces computational complexity from O(N2) (full self-attention) to O(NM), where N is the number of input tokens and M≪N is the number of latents. Several stacked self-attention layers refine the latents, which in turn inject global information back into the input patch tokens via a second cross-attention layer. This design efficiently aggregates global temporal and inter-channel dynamics.
Decoder. Prediction targets (arbitrary patches) are represented as learnable query tokens constructed via temporal and channel embeddings. The decoder runs cross-attention from these queries to the enriched encoder outputs, yielding context-aware predictions for each arbitrary target segment (Figure 2).
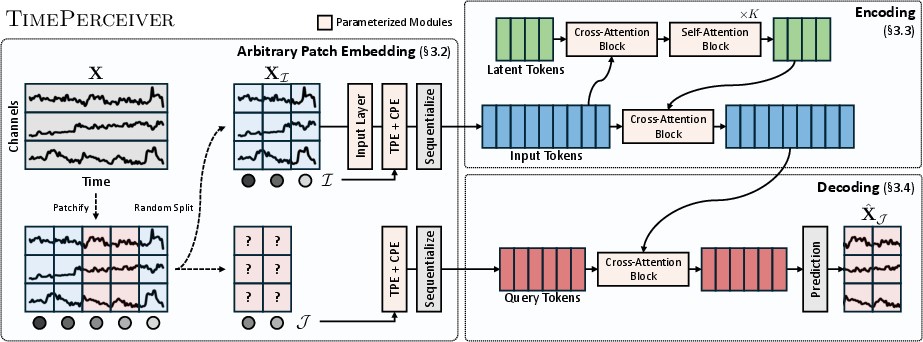
Figure 2: The TimePerceiver encoder-decoder framework with latent bottleneck encoding and target-specific query-based decoding.
This decoupling between input and target positions enables information routing across arbitrary input-output mappings, fundamentally aligning the model with the generalized training protocol.
Empirical Results and Ablative Analysis
TimePerceiver surpasses state-of-the-art models across all major public multivariate forecasting datasets, encompassing electricity, weather, traffic, and solar benchmarks, as well as ETT subsets. Evaluations average over multiple lookback and forecasting horizon combinations, measuring both MSE and MAE. Strong numerical claims include:
- TimePerceiver achieves the best (55/80) and second-best (17/80) scores across 80 settings, attaining the most favorable average rank in both MSE (1.375) and MAE (1.550).
- Consistent performance improvements over strong channel-dependent models (e.g., 5.6%/4.4% MSE/MAE boost over CARD and an 8.5%/7.3% improvement over iTransformer) are observed.
A key ablation investigates the benefit of the generalized task and bottleneck attention approach. The generalized task formulation consistently outperforms standard unidirectional forecasting, with up to 5.0% and 3.4% average improvements in MSE and MAE, respectively. Further, the latent bottleneck encoder yields lower error and superior efficiency compared to full self-attention and decoupled axis-wise attention, especially for longer context windows.

Figure 3: Relative MSE reduction (%) due to various target sampling strategies in the generalized formulation, illustrating the benefit of flexible training objectives, particularly with mixed or disjoint patch sampling.
The results also validate that the query-based decoder, leveraging shared positional embeddings between encoder and decoder, is crucial for temporal alignment, offering optimal performance in most datasets. Alternative configurations (e.g., direct latent-to-query decoding, or unshared positional embeddings) underperform relative to the unified design.
Model Interpretability and Resource Efficiency
Visual analysis of attention maps clarifies the model’s information flow. Encoder-side latents capture diverse, distributed dependencies across temporal and channel dimensions, while decoder queries attend selectively to contextually aligned input regions, often matching periodic phenomena (Figure 4).
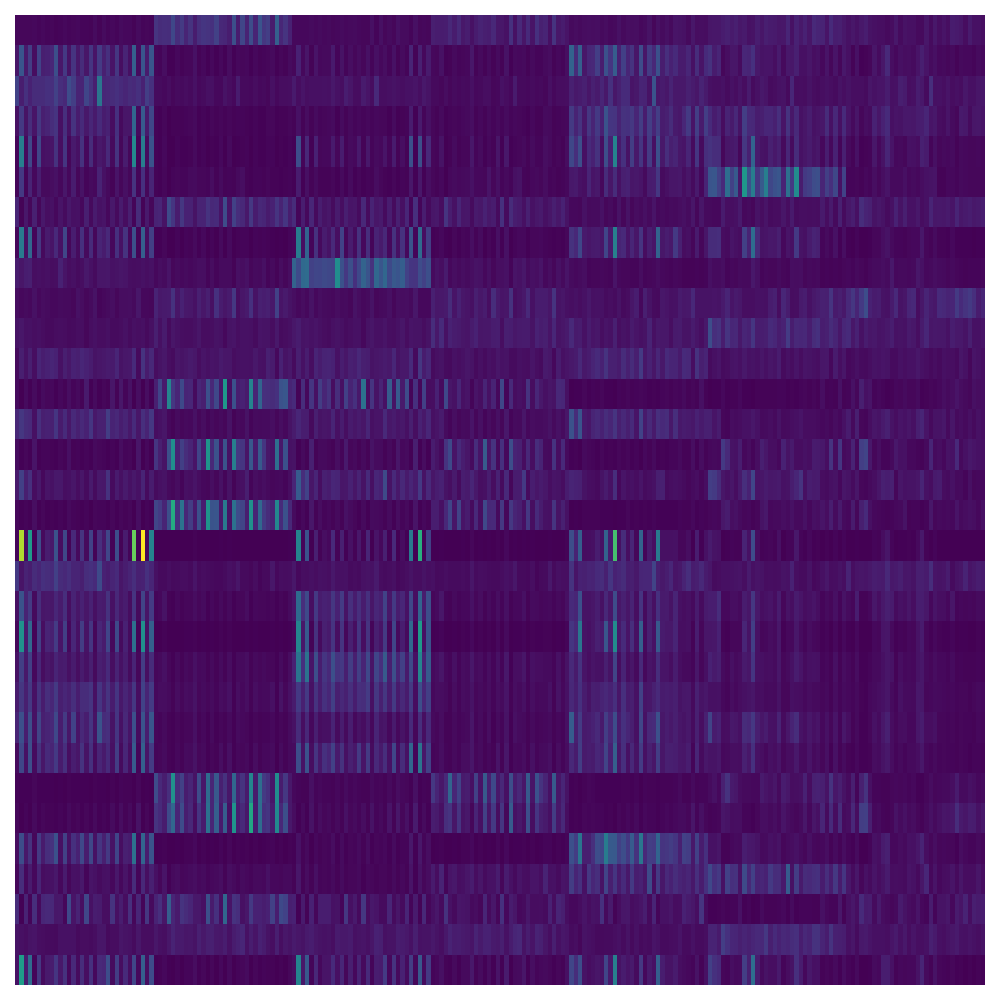



Figure 4: Encoder and decoder attention maps on ETTh1, showing the distributed and periodic routing of attention across temporal and channel positions in both latent bottleneck (encoder) and query-based (decoder) stages.
Resource efficiency is a salient property of TimePerceiver. The latent bottleneck yields lower GPU memory and faster training compared to self-attention baselines, with decoder parameter count remaining nearly constant regardless of forecasting horizon, unlike linear projection decoders whose size grows linearly with target length. These characteristics ensure scalability to high-dimensional, long-context time series (Figure 5).
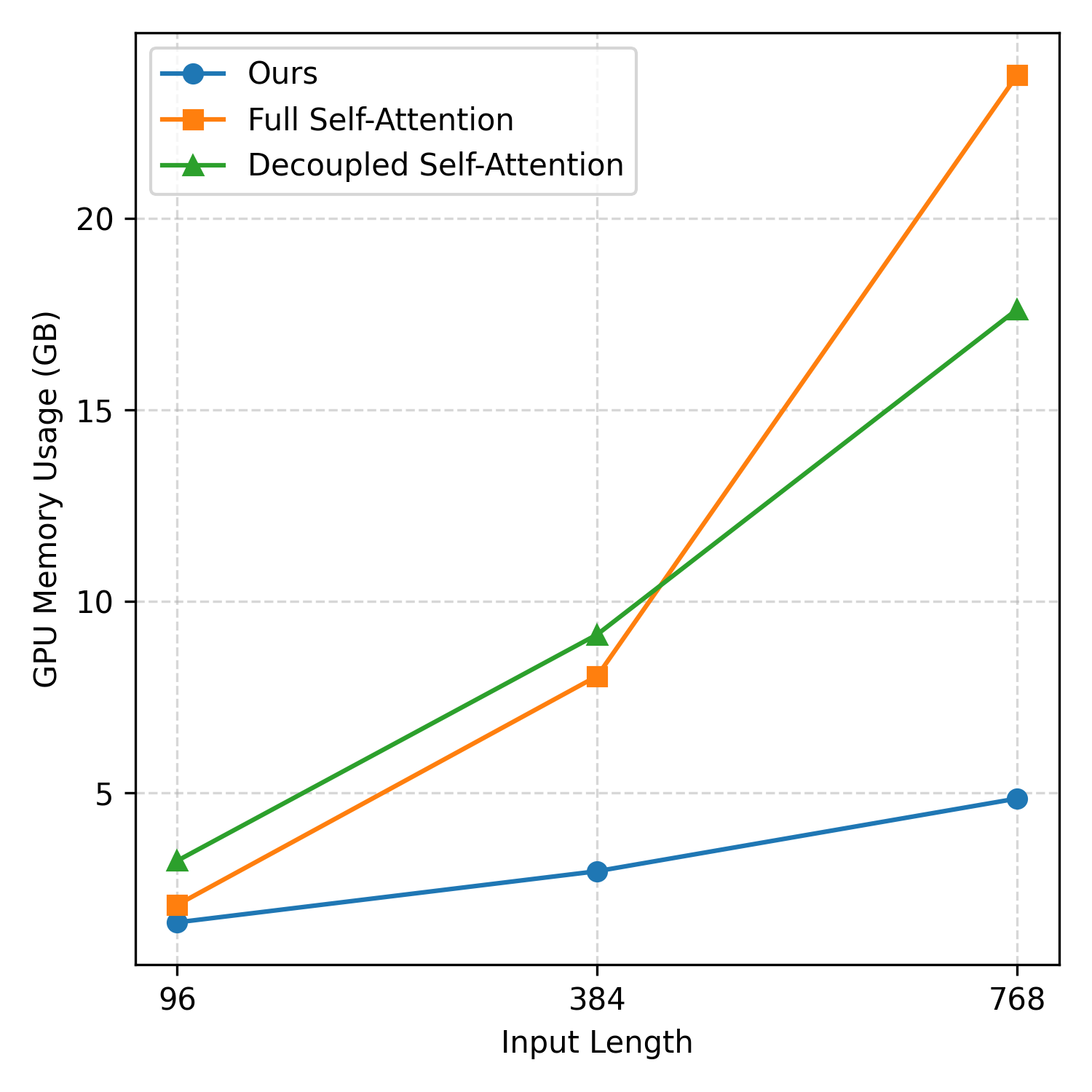
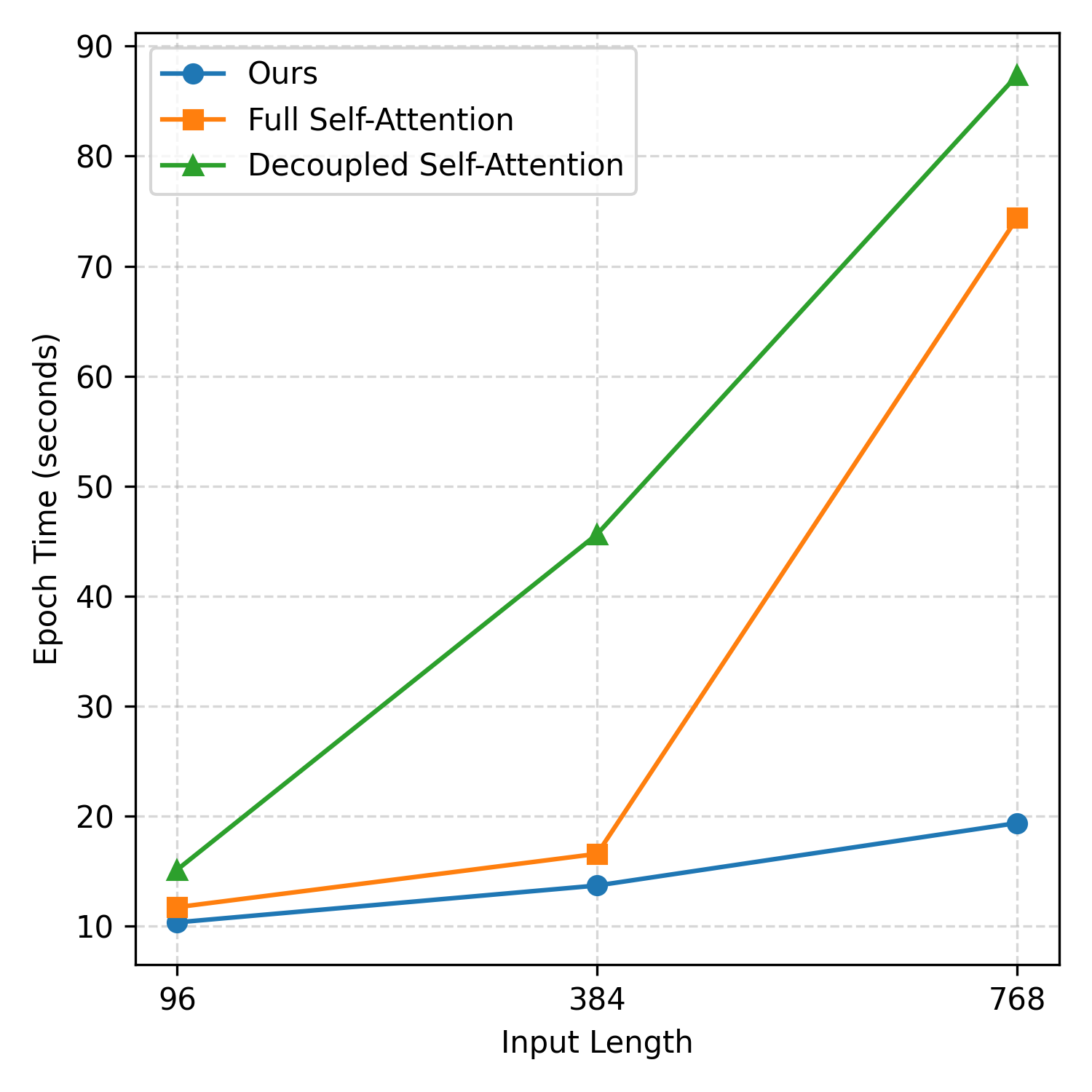
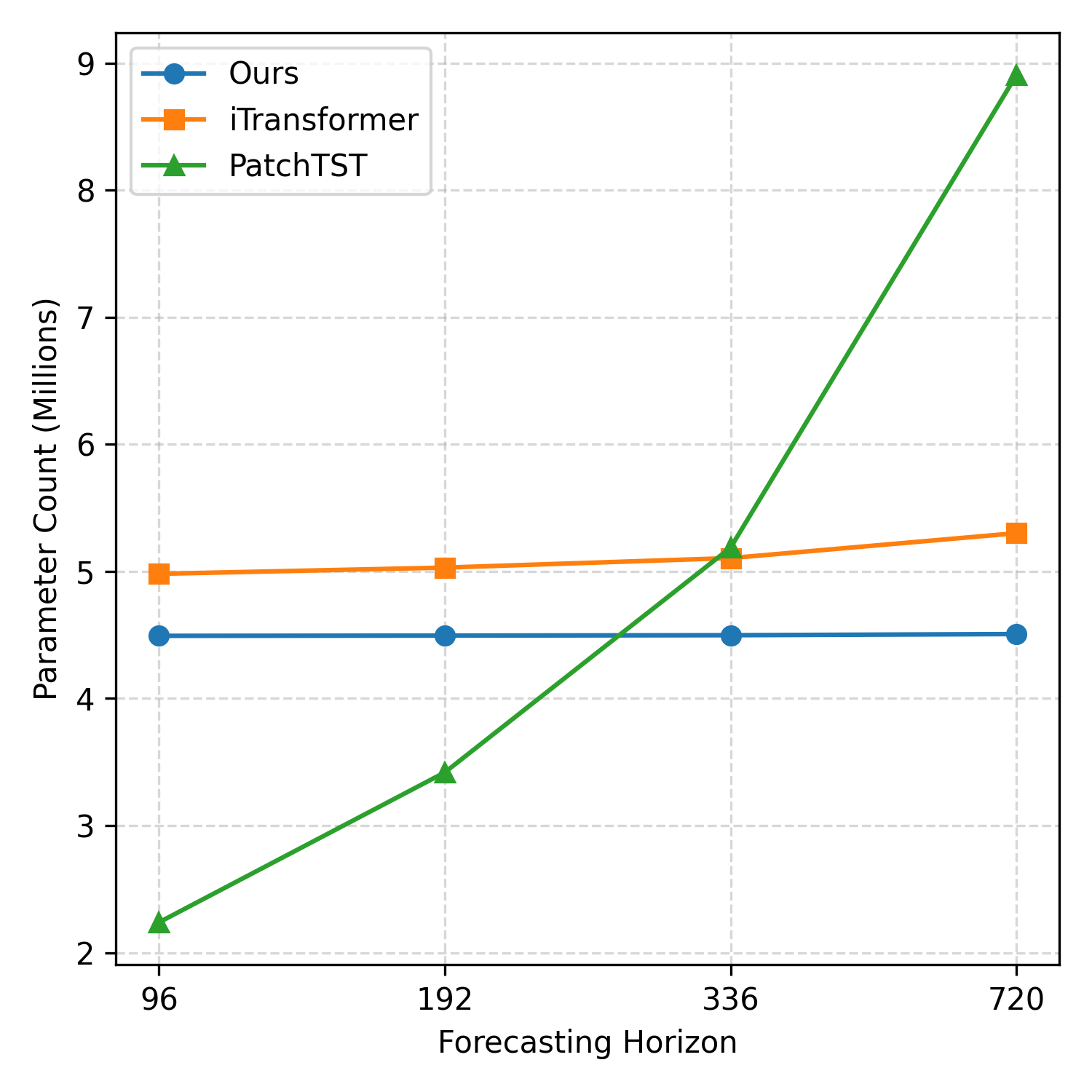
Figure 5: GPU memory usage comparison across encoder architectures, demonstrating substantial savings with the latent bottleneck approach at increasing input lengths.
Theoretical and Practical Implications
The architectural and algorithmic alignment promoted by TimePerceiver marks a methodological advance in time-series modeling. By unifying extrapolation, interpolation, and imputation within one modeling framework and training objective, TimePerceiver advances the prospect of generalizable forecasting systems. Its encoding via learnable latents resonates with developments in structured neural memory and set transformers, but explicitly incorporates temporal/channel structure and prediction requirements of time-series data.
Practically, the method’s robust generalization and computational efficiency render it appealing for deployment in industrial and scientific forecasting pipelines, especially where missing data and non-standard query patterns are routine. Furthermore, the generalized task setup is broadly applicable, as evidenced by consistent improvements when incorporated into non-TimePerceiver encoders (e.g., PatchTST).
Future research directions include extending the framework to irregular or event-driven sampling, as well as exploring compositional or hierarchical latent schemas to model even more complex temporal dependencies without sacrificing tractability.
Conclusion
TimePerceiver introduces an end-to-end, generalized forecasting framework that holistically integrates temporal context encoding, flexible decoding, and a diverse training objective. Its design significantly elevates empirical performance across standard and non-standard forecasting tasks, and its structural alignment of architecture and objective suggests wide applicability within the broader time-series modeling landscape. The results highlight the importance of unified modeling for robust and adaptable time-series forecasting.