- The paper presents Affordance RAG, a framework that decouples semantic matching from manipulation suitability using a hierarchical, affordance-aware memory.
- It leverages a two-stage process: constructing an affordance-aware memory during pre-exploration and executing top-down multimodal retrieval with multi-level fusion.
- Experimental results demonstrate significant improvements in recall (37.1% at recall@10) and task success (85% SR in real trials) over traditional methods.
Affordance RAG: Hierarchical Multimodal Retrieval with Affordance-Aware Embodied Memory for Mobile Manipulation
Introduction
The challenge of scalable open-vocabulary mobile manipulation (OVMM) demands both robust visual grounding of natural language instructions and affordance-aware reasoning across complex, unstructured indoor environments. Traditional VLM-based retrieval approaches for manipulation tasks suffer from two key deficiencies: bias toward visually similar but functionally irrelevant objects, and the lack of action-centric filtering — crucial for high task completion rates in physical robot systems. The "Affordance RAG" framework (2512.18987) advances OVMM by proposing a hierarchical, affordance-centered memory and retrieval process, decoupling semantic matching from manipulation suitability and fusing multi-granularity context for robust zero-shot deployment.
Affordance RAG Framework
The pipeline is structured in two stages: the construction of an Affordance-Aware Embodied Memory (Affordance Mem) during environmental pre-exploration, and hierarchical multimodal retrieval upon receiving free-form instructions. The approach systematically addresses the limitations of flat, label-based, or purely visual memory architectures by explicitly encoding affordance triplets and leveraging region- and context-aware node aggregation.
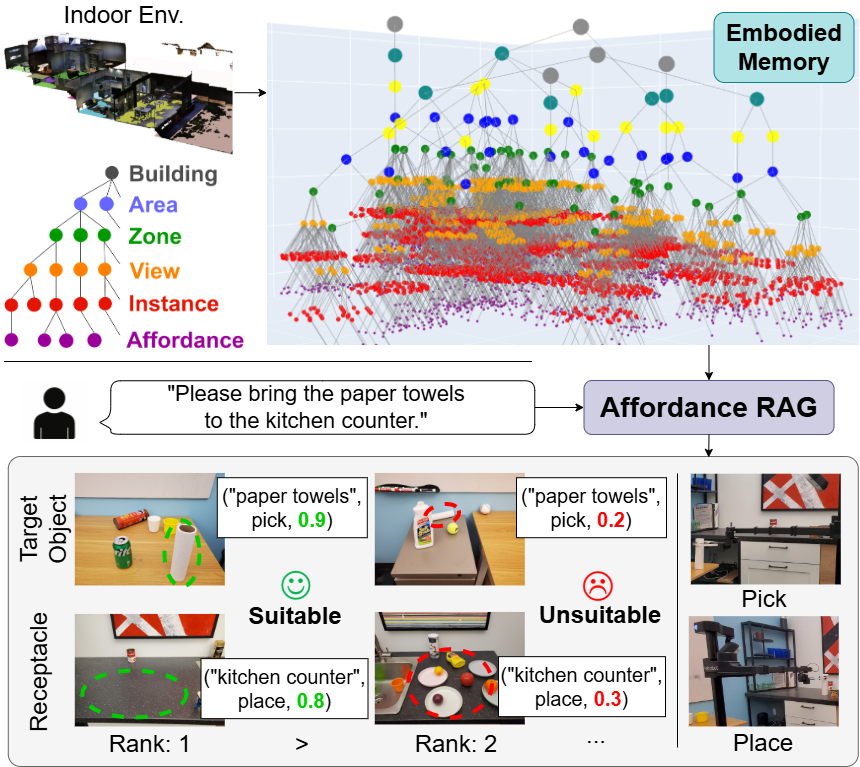
Figure 1: Overview of Affordance RAG for open-vocabulary mobile manipulation. The robot's embodied memory is constructed from pre-explored images, then queried hierarchically using natural language, with candidates prioritized by affordance scores.
Affordance Mem is built bottom-up, progressing from detected object instances through multi-level clustering to form region/area/building nodes. Each level aggregates not only image-level features (from foundation VLMs such as BEiT-3 and BLIP-2), but also visually prompted, instance-specific affordance triplets (object, action type, affordance score), supporting queries about both what is physically present and what is feasible for manipulation.
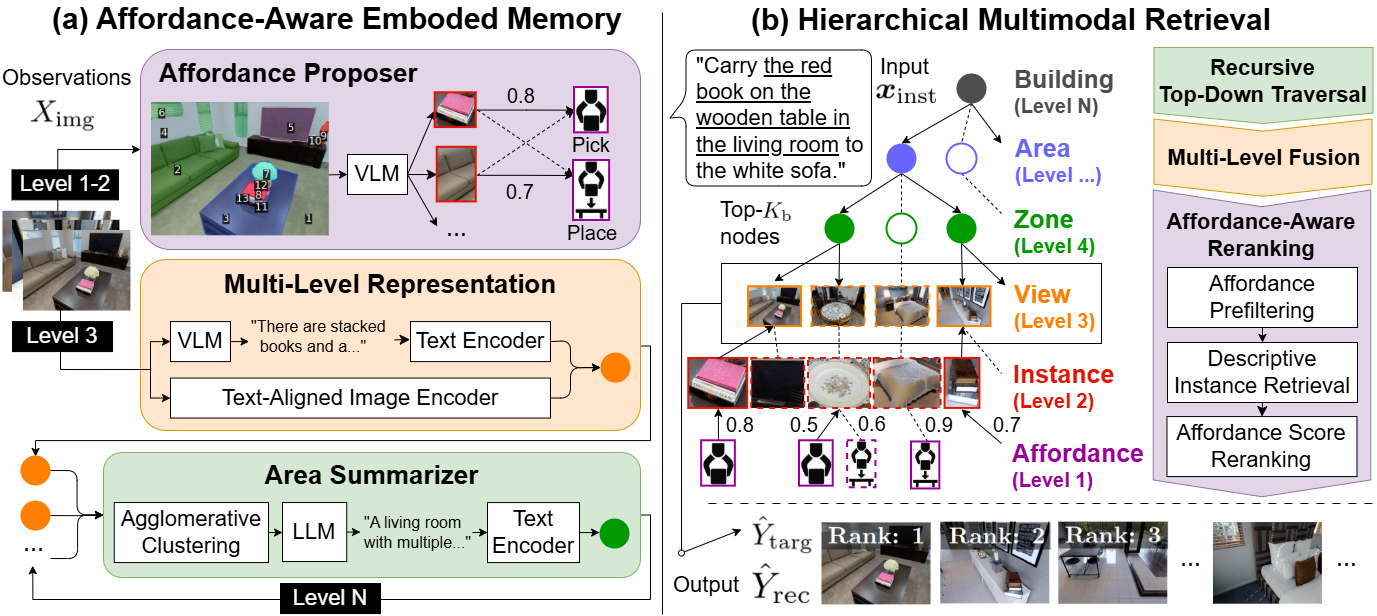
Figure 2: The Affordance RAG framework: (a) Construction of Affordance Mem with affordance proposing and multi-level aggregation. (b) Top-down retrieval and affordance-aware reranking.
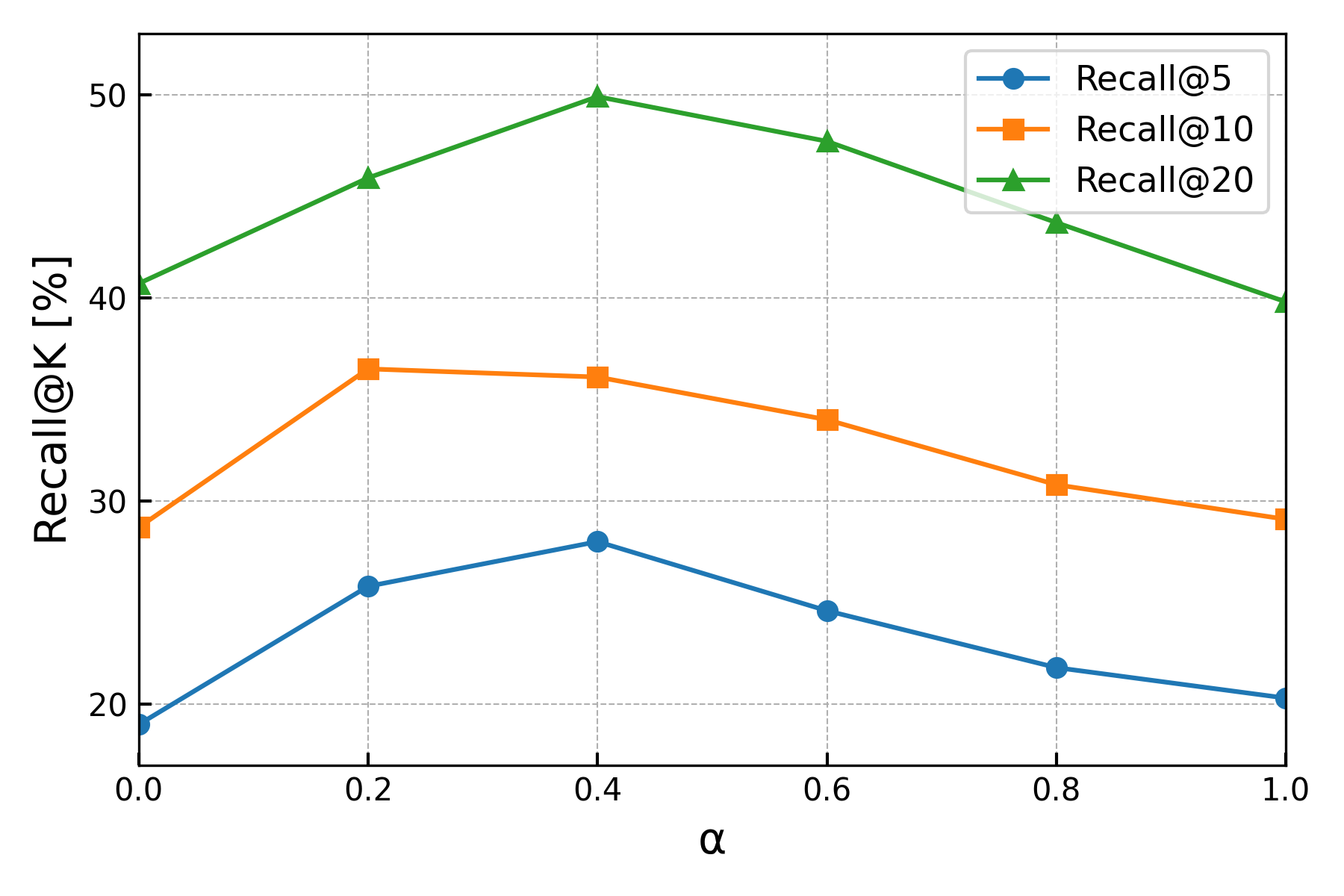
The query process executes a recursive top-down traversal from region to candidate instance level, guided by similarity in embedded regional semantics. A key innovation is Multi-Level Fusion, which linearly combines contextual and object-centric matching with a tunable hyperparameter α, and an Affordance-Aware Reranking step that filters and prioritizes candidates based on predicted affordance feasibility.
Experimental Results
WholeHouse-MM Benchmark
Affordance RAG is evaluated on the WholeHouse-MM benchmark, which is specifically designed to capture the complexity of building-scale mobile manipulation with human-generated, compositional instructions and large image sets per episode, thus reflecting high practical relevance.
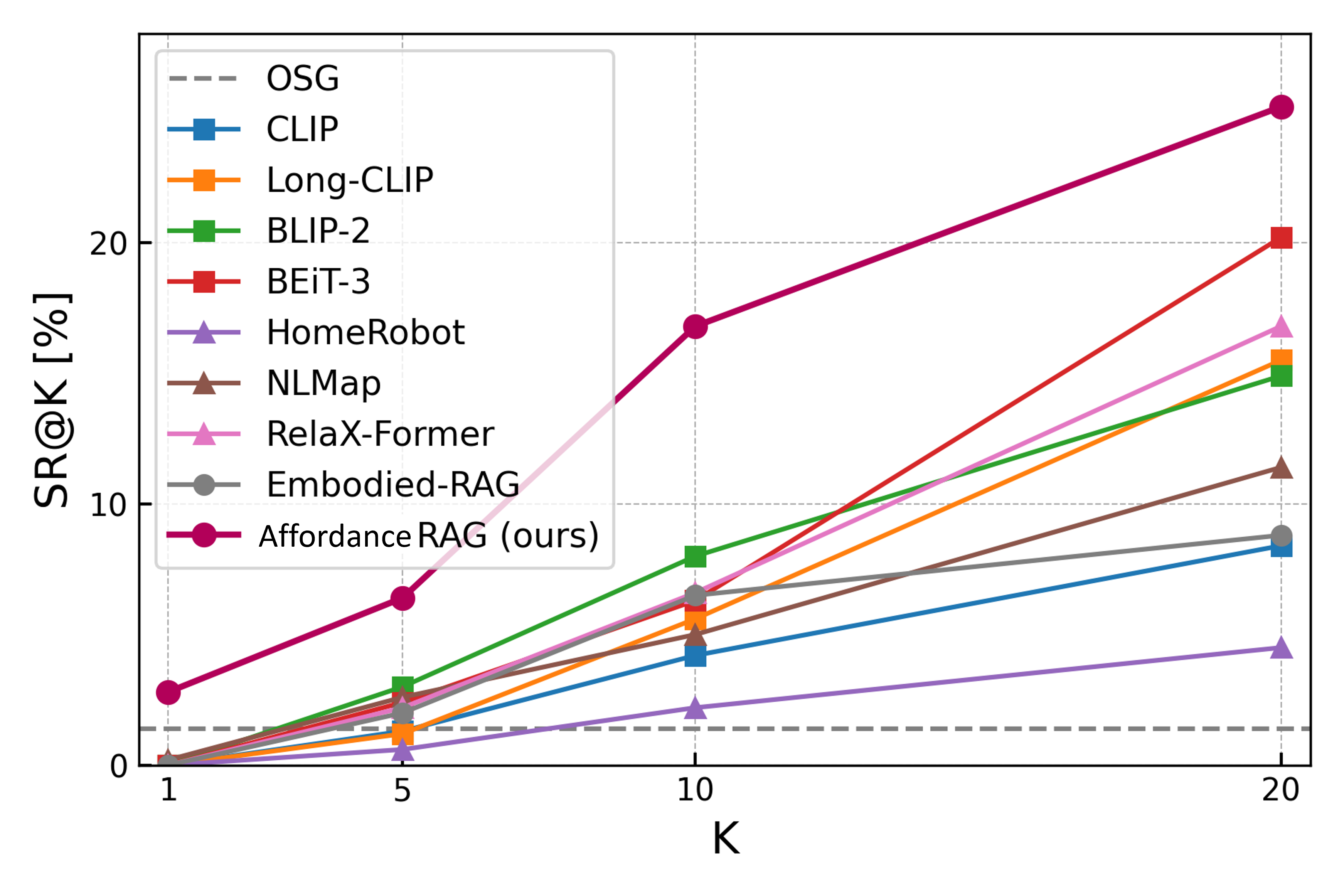
Figure 3: Task success rates (SR) at various recall levels on the WholeHouse-MM benchmark; Affordance RAG outperforms both flat and hierarchical baselines.
The method surpasses all baselines — including BEiT-3, BLIP-2, and advanced retrieval-centric methods (e.g., RelaX-Former, Embodied-RAG) — by significant margins. Specifically, it records overall recall@10 rates of 37.1% on WholeHouse-MM, an 8.4 point absolute improvement over its strongest non-affordance aware competitor. Affordance RAG achieves SR@10 of 16.8%, compared to 1.4% for the Object Goal Navigation memory baseline.
Ablations demonstrate clear contributions from each architectural element:
The sensitivity analysis for α shows that both modalities are complementary: skewing toward either pure regional or visual matching consistently reduces recall.
Qualitative Analysis
Qualitative results elucidate the system’s robust handling of compositional and ambiguous queries. For example, when prompted to "take a photo frame from the side table in the bedroom and place it on the dining table with a bouquet of flowers," Affordance RAG exclusively retrieves feasible, contextually accurate regions and objects, while strong visual-semantic baselines mis-rank implausible or incorrect candidate objects and locations.

Figure 5: Qualitative retrieval—Affordance RAG retrieves semantically and manipulatively correct object/receptacle pairs consistent with under-specified human instructions.
Real-World Validation
Deployment on a physical Hello Robot Stretch 2 platform affirms high task success rates — the method achieves 85% success (SR) in 40 real-world execution trials, compared to 45% for BEiT-3 and 70% for the variant without affordance reranking. This is marked considering the prevalence of ambiguous instructions and the presence of multiple physically distinct candidate objects and placement sites.

Figure 6: Qualitative results from real-world experiments: affordance-aware reranking enables selection of graspable/placable candidates even under ambiguous visual context.
The results validate that ASR (Affordance Score Reranking) is essential for improving end-to-end task success, especially when semantic cues alone do not distinguish between viable and non-viable manipulation options.
Theoretical and Practical Implications
This work substantiates that hierarchical, affordance-aware memories are necessary for bridging the gap between open-vocabulary language understanding and real-world robotic manipulation. The empirical gains are directly attributable to the explicit disentanglement of semantic and physical-action reasoning, and to the use of memory architectures that can scale to large, complex environments while remaining tractable at inference time.
From a practical perspective, Affordance RAG demonstrates immediate applicability to service robots in human spaces, as well as broader embodied agents requiring instruction following under uncertainty. The approach generalizes beyond static object recognition, supporting dynamic task composition and adaptation to scene affordances in zero-shot settings.
Future Directions
Outstanding challenges remain in scaling this framework to dynamically evolving and partially observed environments—particularly with severe occlusions—and in integrating closed-loop physical/kinematic reasoning. Expanding the affordance ontology, incorporating interactive/active exploration, and joint optimization with manipulation policy learning are promising directions.
Conclusion
The Affordance RAG framework redefines the state-of-the-art for instruction-conditioned mobile manipulation by introducing a zero-shot hierarchical multimodal retrieval paradigm, explicitly structured for affordance reasoning. Empirical results in both simulation and real-world execution validate the superior effectiveness of affordance-aware, multi-level memory architectures for open-vocabulary robotic manipulation tasks (2512.18987).