- The paper introduces Kling-Omni, a holistic framework that unifies multimodal video generation, editing, and reasoning through an integrated diffusion transformer architecture.
- It employs a multi-stage training regimen with a specialized prompt enhancer and cascaded super-resolution modules, reducing inference steps from 150 to 10 while ensuring high dynamic quality.
- The approach supports flexible, compositional task integration with robust cross-modal data curation, enabling advanced video synthesis with improved semantic stability.
Kling-Omni: A Generalist Framework for Unified Multimodal Video Generation and Editing
Motivation and Unified Paradigm
Kling-Omni addresses the disjointed nature of extant video generation pipelines, which are traditionally segmented into isolated pathways for generation, editing, and reasoning. Contemporary approaches suffer from limited integration, constraining the breadth of user control, and often depend on rigid text encoders or auxiliary adapters that impede scalability and degrade semantic fidelity. Kling-Omni introduces a holistic architecture that unifies multimodal video generation tasks by embedding a Multi-modal Visual Language (MVL) input interface, supporting flexible text, image, and video conditioning within a shared representation space. This eliminates rigid task boundaries and enables seamless handling of diverse video creation and editing tasks.
Architecture and System Design
The Kling-Omni framework is structured around three principal modules: a Prompt Enhancer (PE), an Omni-Generator, and a Multimodal Super-Resolution (SR) component. The PE employs a specialized MLLM to reformulate heterogeneous user prompts into an aligned MVL distribution, maximizing identity and spatial consistency as well as instruction adherence. The Omni-Generator leverages a robust diffusion transformer architecture to process visual and textual tokens jointly, promoting deep cross-modal interaction and robust grounding for high-fidelity synthesis, in both instruction-driven and reference-based scenarios.
A cascaded diffusion-based super-resolution module further refines low-resolution latents using spatio-temporally aware local attention mechanisms (with shifted windows and asymmetric attention), distributing the computation efficiently and exploiting KV caching for inference acceleration. The entire pipeline is end-to-end trainable and optimized for both memory and throughput, utilizing hybrid parallelism and sophisticated load-balancing during large-scale pretraining.
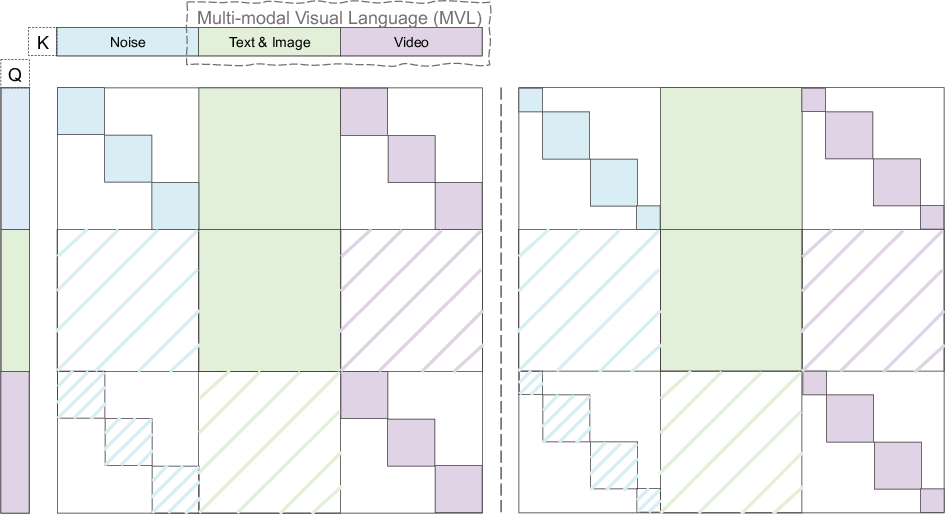
Figure 1: Attention maps in Multimodal Super-Resolution, highlighting the computational reduction via windowed attention with shaded regions skipped, enabling efficient and scalable high-res video synthesis.

Figure 2: Kling-Omni's pipeline schedule, demonstrating simultaneous data- and pipeline-parallel processing of VAE/TE modules for minimal GPU memory overhead and maximal utilization.
Training Regimen and Optimization
Model training adopts a staged progression, initially pretraining with extensive text-video and image-video pairs for robust instruction and reference conditioning. The curriculum is expanded during supervised finetuning to include mixed-modality tasks such as video editing, image-to-video, and reference-based generation with increased compositional complexity, enforcing modular cross-modal reasoning.
A direct preference optimization (DPO) RL phase aligns perceptual outputs with human evaluations, targeting dynamic quality, integrity, and adherence metrics. Kling-Omni explicitly optimizes for model output distribution congruence with expert-annotated aesthetics, enabling improved motion dynamics and semantic stability.
Model acceleration is achieved via a two-stage distillation protocol that combines trajectory-matching distillation and distribution-matching distillation, compressing sampling from 150 NFE to 10 NFE per sample. Unlike SDE-based techniques, Kling-Omni maintains an ODE-centric setup, regularized by trajectory fidelity, ensuring high efficiency without visual degradation.
Scalable Data Infrastructure
The system leverages a highly diversified, dual-source data curation strategy. It aggregates vast real-world video/image-sourced data with synthetic, expert-model-curated edits for maximal coverage of the cross-modality and cross-task spectrum necessary for unified video synthesis, as evidenced by the expansive cross-modal data distributions.

Figure 3: Visualization of cross-modal and cross-task data coverage (image/text/video, referencing, editing, etc.), underpinning Kling-Omni’s ability to generalize broadly.
The data pipeline integrates rigorous filtering stages, embracing basic sample curation, stringent temporal continuity assessment, and automated multimodal alignment, including identity preservation for human-centric tasks. This clean, interpretable foundation raises the effective training ratio and reduces noise accumulation, directly influencing Kling-Omni’s strong generalization across diverse compositional instructions.

Figure 4: Data filtering pipeline ensuring only temporally consistent and semantically aligned data enter model training.
Human Evaluation and Quantitative Results
Performance evaluation leverages an exhaustive multimodal benchmark encompassing over 500 test cases, spanning a heterogeneous blend of subject categories, application scenarios, and compositional challenges. Human expert scoring employs a Good–Same–Bad (GSB) protocol, comparing Kling-Omni with leading contemporaries (Veo 3.1 and Runway Aleph) on dimensions such as dynamic quality, prompt adherence, identity consistency, and editing stability.
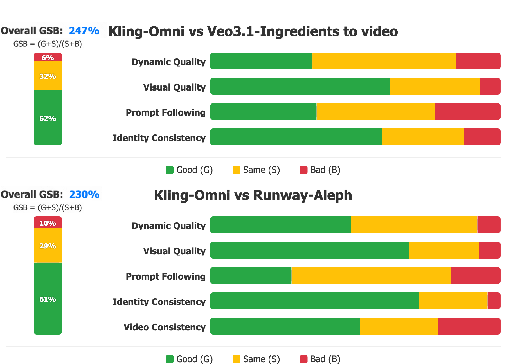
Figure 5: Kling-Omni quantitatively surpasses controllable baselines in reference-based generation and video editing across all GSB categories and evaluation metrics.
Kling-Omni demonstrates high dynamic quality and consistent identity maintenance, outperforming conventional models particularly on advanced referencing and combinatorial editing tasks.
Multimodal Referencing and Compositional Control
Kling-Omni’s MVL interaction allows user conditioning via flexible fusion of images, subject libraries, videos, sketches, and explicit text prompts. The system integrates information across these modalities, ensuring semantic congruence and robust subject consistency, supporting sophisticated referencing such as novel view generation, motion/camera transfer, temporal narration from image sets, and sketch-driven control.

Figure 6: Qualitative examples of image-reference-based video generation, illustrating precise subject and stylistic control.

Figure 7: Multi-expression element library referencing for robust identity management across varying representations.

Figure 8: Fusion of image and element library references enables highly granular video synthesis.
Temporal narrative capability further allows the model to convert a grid of sequential images into smoothly cohesive video narratives, leveraging inter-frame reasoning.

Figure 9: Kling-Omni reconstructs dynamic video narratives from temporally arranged image grids.
High-freedom editing supports unconstrained manipulations—addition, replacement, stylization, attribute adjustment, and special effects—spanning neither temporal nor spatial limitations.

Figure 10: Examples of editing operations such as addition, removal, and replacement in real video sequences.

Figure 11: Special effects manipulation, demonstrating compositional editing capabilities.
Flexible Task Composition
The model natively merges multiple references and instructions into a single generative pass without serial task chaining, minimizing error propagation and improving consistency. Task composition is evidenced in cases of combining subject libraries, visual style, new shot generation, and background manipulation within a unified instruction instance.

Figure 12: Example of intricate task composition—fusion of subject library, reference, and stylization in a single process for coherent video synthesis.
Enhanced Reasoning and Visual Control
Kling-Omni’s architecture supports visual-signal-guided control and advanced reasoning—including geospatial, temporal, and logical inference—by interpreting user-provided signals such as annotated images, visual cues, or context-enriched prompts. This reframes video synthesis as a generative reasoning engine capable of dynamic task adaptation, situational awareness, and creative visual grounding.

Figure 13: Compositional manipulation fusing camera angle changes, background edits, and style transfer within a single coherent result.
Theoretical and Practical Implications
Kling-Omni’s unified framework establishes a foundation for agentive, multimodal world simulators capable of cross-modal reasoning, generative perception, and high-level environmental interaction. The system’s tightly integrated data curation, distillation-accelerated ODE sampling, and robust MVL grounding mark a strong transition point from task-specific pipelines towards generalist, interactive media simulators.
On the practical front, Kling-Omni enables efficient, high-quality controllable video synthesis with broad applications in cinematic production, e-commerce, virtual environment generation, and vision-language research platforms. The compositional instruction and visual signal interface invite future multimodal UI innovation, while the underlying architectural and data systems provide a blueprint for the next generation of generalist world models.
Conclusion
Kling-Omni unifies the generation, editing, and reasoning paradigms in video modeling via a diffusion transformer backbone, a tailored data engineering pipeline, and a holistic multimodal interaction scheme. It achieves state-of-the-art results on comprehensive benchmarks, demonstrates broad compositional flexibility, and lays the groundwork for future developments towards fully interactive multimodal world models (2512.16776).